Our brain is modular by design and is characterised by distinct but interacting subsystems which handle important functions like memory, language and perception. Attention is studied in neuroscience as an important cognitive process. These advances in neuroscience have inspired exciting developments using attentional mechanisms in machine learning. There is a whole field of research in computational modelling of attention as well.
In machine learning most of the attention mechanism models are used to process and learn from sequential data. The dominant models are based on recurrent or convolutional neural networks which include an encoder and a decoder. These dominant models are complicated and also face prediction churn issues. The researchers at Google and the University of Toronto came up with a much simpler network architecture, called the Transformer, based solely on attention mechanisms, with no need for recurrence and convolutions.
The architecture designed by the team of Google Brain, Google Research and the University of Toronto is end-to-end, based on attention model. This of the article takes a look at its architecture and the end results.
Machine Translation Tasks And The Transformer
Self-attention is an attention mechanism relating different positions of a single sequence in order to calculate a representation of the sequence. The paper proposes the Transformer — a model architecture which does not use recurrence and relies entirely on an attention mechanism — to learn global dependencies between input and output. The Transformer allows for significantly more parallelisation and can reach a new state-of-the-art level in translation quality after being trained for as only 12 hours on eight P100 GPUs.
The researchers did experiments on two machine translations tasks using their architecture. The architecture is readily parallelizable and requires significantly less time to train. The model achieves 28.4 BLEU score on the WMT 2014 English-to-German translation task, improving over the existing benchmarks. The researchers also show that the Transformer generalises excellently to other tasks by parsing both with large and limited training data. The architecture is designed in a way so that it requires lesser number of training instances than traditional networks.
Model Architecture
The neural sequence models are mostly built as encoder-decoder structures. The encoder maps an input sequence of symbol representations (x1…xn) to a sequence of continuous representations z = (z1…zn). Given z, the decoder then generates an output sequence (y1…ym) of symbols one element at a time. The Transformer is based on these three elements:
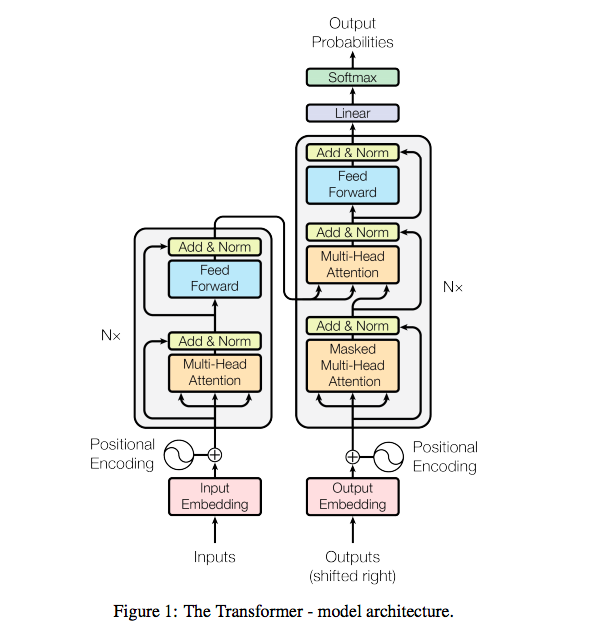
Encoder: The encoder is composed of a stack of N = 6 identical layers. The first is a multi-head self-attention mechanism, and the second is a simple, position-wise fully connected feed-forward network.
Decoder: The decoder is also composed of a stack of N = 6 identical layers. In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack.
Attention: An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors.
The model has a multi-head attention system and is used in the following ways:
- In “encoder-decoder attention” layers, the queries to the current layer come from the previous decide layer and the memory keys and values, come from the output of the encoder. This is similar to the encoder-decoder attention mechanisms in sequence-to-sequence models.
- The encoder contains self-attention layers. In a self-attention layer all of the keys, values and queries come from the same place. Each position in the encoder can attend to all positions in the previous layer of the encoder.
- Similarly, self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position. We need to prevent leftward information flow in the decoder to preserve the autoregressive property.
Training And Results
The researcher trained on the standard WMT 2014 English-German dataset consisting of about 4.5 million sentence pairs and shared source target vocabulary of about 37,000 tokens. They also trained the models on one machine with P100 GPUs and The big models were trained for 300,000 steps, which took three-and-a-half days to train.
On the WMT 2014 English-to-German translation task, the Transformer beats the best previously reported models, and hence establishes a new state-of-the-art score BLEU score of 28.4. On the WMT 2014 English-to-French translation task, the Transformer achieves a BLEU score of 41.0. The researchers evaluated the Transformer can generalise to others tasks such as English constituency parsing. Also, RNN sequence-to-sequence models have not been able to attain state-of-the-art results when smaller data sets are involved.
The researchers from Google and University of Toronto who have been working on this project, are really excited about the future of attention models in AI tasks. The processing of sequential tasks, something which was largely dominated by RNNs and CNNs, is now being tackled using a pure attention model network. The researchers plan to extend the Transformer to problems involving input and output modalities other than text and to investigate local, restricted attention mechanisms to efficiently handle large inputs and outputs such as images, audio and video.