Are you curious about how the Apriori algorithm & Association Rule works? and How Permutation & Combination are useful in mining rule. Then you are in the right place, let me walk you through it. In this article we will discuss:
Note: Author expects that readers understand basic probability, Permutation, Combination, Numpy, Pandas module.
Many business enterprises accumulate huge amounts of data from their daily operation. For example, a large number of customer purchase details are collected daily in grocery stores. Such data, commonly known as Market Basket Transaction shown in Figure 1. Each row i:e each customer transaction at a time labelled as Transaction. Figure 1 illustrate an example, Transaction 1 contains {Bread}, transaction 2 contain {Scandinavian}, transaction 3 contain {Hot chocolate, Jam, Cookies} etc.

Market basket data should be converted to Binary format as shown in Figure 2. Where each row corresponds to a transaction and each column corresponds to an item. Items can be treated as binary variables, holding value one if the item is present in a transaction else zero.

Itemset and Support Count
Let I = {Bread, Scandinavian, Cake, Muffin, Coffee, Pastry} be the set of all items in a market basket data and T = Total No of transactions be the set of all transactions. An itemset may contain single or more than one item like {Cake}, {Bread}, {Bread, Cake}, {Bread, Coffee}. An important property of an itemset is its support count, which refers to the number of transactions that contain itemset. Mathematically, the support {Bread, Coffee} for an itemset {Bread, Coffee} can be stated as follows:
SupportBread, Coffee= No of transaction contain Bread and CoffeeTotal no of Transaction(T)
Frequent Itemset Generation:
Objective is to find the itemsets that satisfy minimum threshold support, these itemsets are called frequent itemsets Otherwise called Infrequent Itemsets. Don’t get confused if I use this term. Figure 3 shows all possible itemsets that can be generated by an itemset I = {a, b, c, d, e}. In general, a dataset that contains k items can potentially generate up to 2^K itemset. Because K can be very large in many practical applications, it becomes computationally expensive.
To overcome this problem, we can prune the unwanted itemsets as follows, As illustrated in Figure 3. when an itemset {a}, {b} is infrequent, then all of its supersets (i:e the non-shaded itemset in this figure) must be infrequent too. Suppose {c, d, e} is a frequent itemset, then all its subsets itemset (i:e the shaded itemset in this figure) must also be frequent.

Apriori Algorithm:
Let me show you how Apriori algorithms work and generate frequent itemsets based on a concept that a subset of a frequent itemset must also be a frequent itemset. Below is the code to generate frequent itemsets with an example from our dataset.

STEP 1:
- Create dictionary “support” to stored itemsets and support.
- Store all items in set “L” available in dataset
STEP 2: Iteration are as follows:
Iteration 1: Initially the algorithm lists all the items and computes support for frequent itemsets with length 1 and stores it in a dictionary, dictionary helps to retrieve values as support using keys as items, here few of them shown in Figure 4- Table L1. Here we assume 4% as minimum threshold support.

Figure 4: Iteration 1
As you can see here, items ‘Scandinavian’ and ‘Muffin’ are infrequent. So, we are going to discard {‘Scandinavian’, ‘Muffin’} in the upcoming iterations. We have the final Table F1 as a Frequent Itemset.
Iteration 2: Next, we will create a combination of 2 itemset and calculate their support. All the combinations of itemset shown in Figure 4-Table F1 are used in this iteration.

Figure 5: Iteration 2
Infrequent Itemsets are eliminated again. In this case {(‘Bread’, ‘Cake’), (‘Bread’, ‘Pastry’), (‘Cake’, ‘Pastry’)} shown in Figure 5-Table L2. Now, let us understand what is pruning and how it makes Apriori one of the best algorithms for finding frequent itemsets.
Pruning: Here we will divide the itemsets in Figure 6-Table L3 into subsets and discard the subsets that are having a support less than minimum threshold support.
Iteration 3: Here all the itemset are infrequent since its subset {(‘Bread’, ‘Cake’), (‘Bread’, ‘Pastry’), (‘Cake’, ‘Pastry’)} already discard in Figure 5-Table. L2, So it Superset will also be infrequent. This is the main highlight of the Apriori Algorithm.

Figure 6: Iteration 3
Since all the itemsets in Iteration 3 are infrequent we will stop here.
STEP 3:
- Calculate support for each jth itemsets.
- if sup meets the minimum support threshold then add to “support” dictionary.
- Update “L” for each jth itemsets take union of itemset in list L and itemset(j)
- L = list(set(L) | set(j))
Let me show you the actual frequent itemset obtained by appriori algorithm.
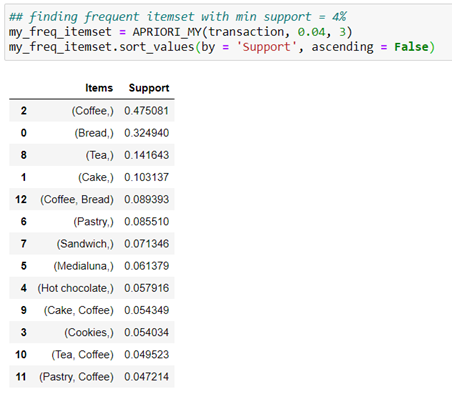
Figure 7: Frequent Itemset
We are almost done as we already obtained frequent itemset, which generally take more computational time. Next, we are going to see Association Rule.
Association Rule:
This section describes how to extract association rules efficiently from the above obtained frequent itemset. An association can be obtained by partitioning the frequent itemsets {Bread, Coffee} into two non-empty subsets, 1) Bread => Coffee, simple way to understand “If Bread then coffee”, 2) Coffee => Bread, “If Coffee then Bread”. The subset meets minimum threshold confidence and Positive lift can be called as strong rule. Curious what is Confidence and Lift? Let me tell you, there are several measures available to analyse a rule, in this article we will discuss confidence and lift.
Confidence:
Objective is to extract all the high-confidence rules from the frequent itemset found in the previous step. It says that Consequent (Coffee) is brought as an effect Antecedent (Bread). This rule is called a strong rule.
ConfidenceBread=> Coffee=Support(Bread and Coffee)Support(Bread)
But confidence measures have one drawback, it might misrepresent the importance of an association. Because it only tells how popular Antecedent (Bread) are, but not Consequent (Coffee). If coffee is very popular then it is more likely that a transaction containing Bread will also contain coffee, thus inflating confidence measures. To overcome this drawback, we use a third measure called lift.
Lift:
Lift computes the ratio between the rule’s confidence and the support of the itemset in the rule consequent. It represents how likely a consequent (Coffee) is purchased when an antecedent (Bread) is already purchased, while controlling for how popular consequent (Coffee) is. When the lift of (Bread => Coffee) is 1, which means no association between items. A lift value greater than 1 implies coffee is likely to be brought if bread is already brought, while a value less than 1 implies coffee is unlikely to be brought if bread is already brought.
LiftBread=> Coffee=Support(Bread and Coffee)SupportBread*Support(Coffee)
Or
LiftBread=> Coffee=Confidence(Bread=>Coffee)Support(Coffee)
Association Algorithm:
Now we will apply association rules to the frequent itemset obtained in the previous algorithm. We will assume minimum threshold confidence 50%.

STEP 1:
- List all frequent itemset and its support to dictionary “support”.
- Create list “data” to stored results.
- List all frequent items set to List “L”.
STEP 2:
- Initially the algorithms will generate rules using Permutation of size 2 of frequent itemset and calculate Confidence and Lift shown is Figure 8.

Figure 8: Strong Rule
Why Permutation over Combination to calculate rules? Let me answer this with a simple example.
For support, the number of transactions containing Cake & Coffee is the same as the number of transactions containing Coffee and Cake, Order does not matter. But this is not the case in a rule, let me explain.
Confidence (Cake => Coffee) = Support (Cake & Coffee) / Support (Cake) = 0.52
Confidence (Coffee => Cake) = Support (Cake & Coffee) / Support (Coffee) = 0.11
Here, Order does matter; thus, we will select those rules which meet minimum threshold confidence. Permutation help fixed position of Antecedent on left side, confuse let me explain with a simple example, let us have Permutation of Cake, Coffee and (Coffee, Cake) to calculate rule as below.
Rule 1: {Cake, (Cake, Coffee)}
LHS(Cake) is fixed for antecedent and it must be a subset of RHS (Cake, Coffee) that gives Confidence (Cake => Coffee).
Rule 2: {Coffee, (Cake, Coffee)}
LHS(Coffee) is fixed for antecedent and it must be a subset of the right side (Cake, Coffee) that gives Confidence (Coffee => Cake).
Till here it’s all good, but we will have more rules like {(Cake, Coffee), Cake} and {(Cake, Coffee), Coffee}, here antecedent is (Cake, Coffee) which seems incorrect thus subset condition is used to eliminate such rule.
Calculate Confidence and other rules for each ith itemsets, if Confidence meets minimum Confidence threshold then add to “Data”.
Below Figure 9 shows the Strong Rule obtained from experimental datasets. Do not forget that Rule is only applied on Frequent Itemset.
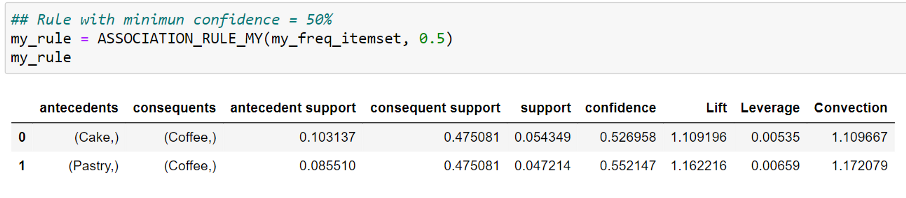
Figure 9: My Rule
Finally, we will cross verify our results with the Standard Package available in Python named mlextend.frequent_patterns having Apriori and association rules modules.
Apriori results:
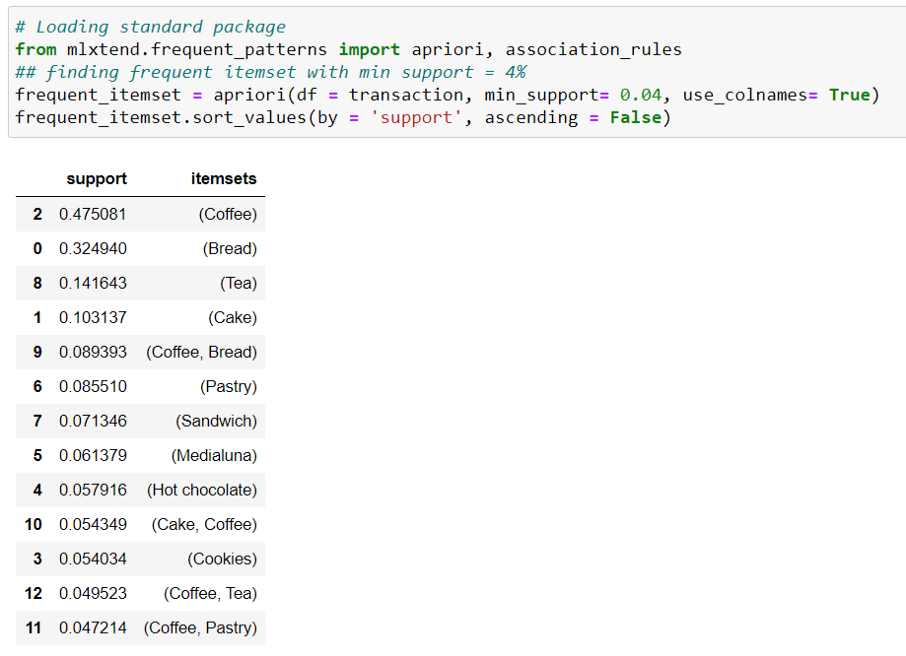
Association Rule results:

From the above comparison we can conclude that our results matched with standard packages and proposed objectives had been served. Feel free to download scratch codes available on my GitHub link https://github.com/Roh1702/Association-Mining-Rule-from-Scratch
Why is Lift a better measure overConfidence? This we will see in detail in another article I will be publishing soon.
References:
- Introduction to Data Mining by Pang-Ning Tan, Michael Steinbach and Vipin Kumar
- https://github.com/viktree/curly-octo-chainsaw/blob/master/BreadBasket_DMS.csv