



Recommender systems are no joke. They have found enterprise application a long time ago by helping all the top players in the online market place. Amazon, Netflix, Google and many others have been using the technology to curate content and products for its customers. Amazon recommends products based on your purchase history, user ratings of the product etc. Netflix recommends movies and TV shows all made possible by highly efficient recommender systems.
This article is aimed at all those data science aspirants who are looking forward to learning this cool technology.
MovieLens Dataset
If you are a data aspirant you must definitely be familiar with the MovieLens dataset. It is one of the first go-to datasets for building a simple recommender system.
We will build a simple Movie Recommendation System using the MovieLens dataset (F. Maxwell Harper and Joseph A. Konstan. 2015. The MovieLens Datasets: History and Context. ACM Transactions on Interactive Intelligent Systems (TiiS) 5, 4: 19:1–19:19.) .
The dataset will consist of just over 100,000 ratings applied to over 9,000 movies by approximately 600 users.
Download the dataset from MovieLens.
The data is distributed in four different CSV files which are named as ratings, movies, links and tags. For building this recommender we will only consider the ratings and the movies datasets.
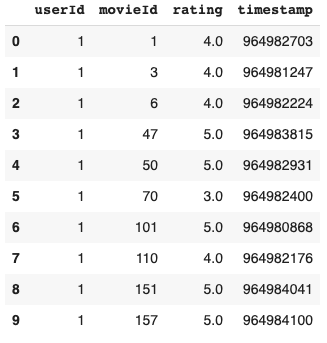
The ratings dataset consists of 100,836 observations and each observation is a record of the ID for the user who rated the movie (userId), the ID of the Movie that is rated (movieId), the rating given by the user for that particular movie (rating) and the time at which the rating was recorded(timestamp).
The movies dataset consists of the ID of the movies(movieId), the corresponding title (title) and genre of each movie(genres).
Building A Simple Movie Recommender
Loading the data
import numpy as np
import pandas as pd
data = pd.read_csv('ratings.csv')
data.head(10)
Output:
movie_titles_genre = pd.read_csv("movies.csv")
movie_titles_genre.head(10)
Output:

data = data.merge(movie_titles_genre,on='movieId', how='left')
data.head(10)
Output:

Feature Engineering
Average Rating
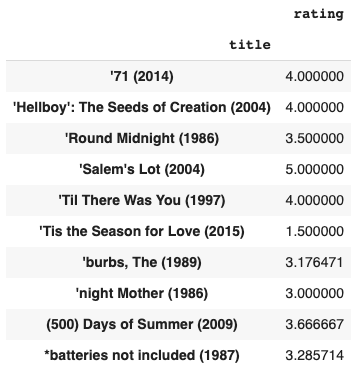
The dataset is a collection of ratings by a number of users for different movies. Let’s find out the average rating for each and every movie in the dataset.
Average_ratings = pd.DataFrame(data.groupby('title')['rating'].mean())
Average_ratings.head(10)
Output:
Total Number Of Rating
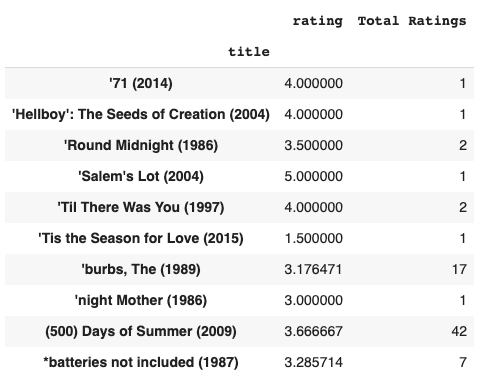
The rating of a movie is proportional to the total number of ratings it has. Therefore, we will also consider the total ratings cast for each movie.
Average_ratings['Total Ratings'] = pd.DataFrame(data.groupby('title')['rating'].count())
Average_ratings.head(10)
Output:
Building The Recommender
Calculating The Correlation
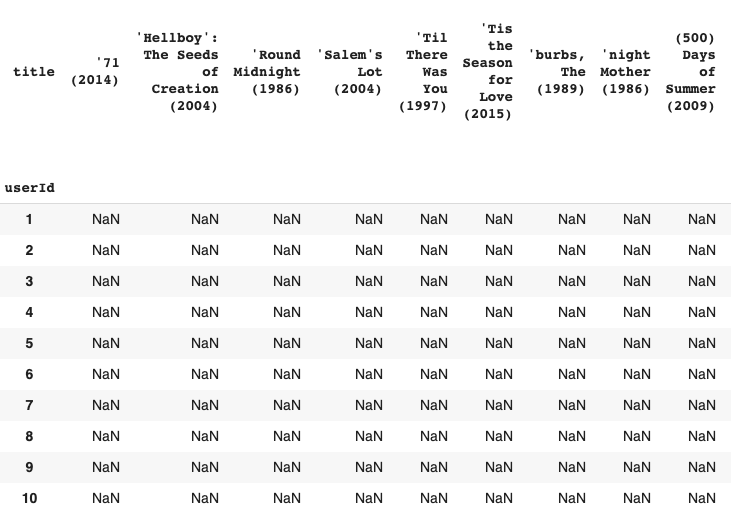
movie_user = data.pivot_table(index='userId',columns='title',values='rating')
The above code will create a table where the rows are userIds and the columns represent the movies. The values of the matrix represent the rating for each movie by each user.
movie_user.head(10)
Output:
Now we need to select a movie to test our recommender system. Choose any movie title from the data. Here, I chose Toy Story (1995).
To find the correlation value for the movie with all other movies in the data we will pass all the ratings of the picked movie to the corrwith method of the Pandas Dataframe. The method computes the pairwise correlation between rows or columns of a DataFrame with rows or columns of Series or DataFrame.
correlations = movie_user.corrwith(movie_user['Toy Story (1995)'])
correlations.head()
Output:

Now we will remove all the empty values and merge the total ratings to the correlation table.
recommendation = pd.DataFrame(correlations,columns=['Correlation'])
recommendation.dropna(inplace=True)
recommendation = recommendation.join(Average_ratings['Total Ratings'])
recommendation.head()
Output:

Testing The Recommendation System
Let’s filter all the movies with a correlation value to Toy Story (1995) and with at least 100 ratings.
recc = recommendation[recommendation['Total Ratings']>100].sort_values('Correlation',ascending=False).reset_index()
Let’s also merge the movies dataset for verifying the recommendations.
recc = recc.merge(movie_titles_genre,on='title', how='left')
recc.head(10)
Output:

We can see that the top recommendations are pretty good. The movie that has the highest/full correlation to Toy Story is Toy Story itself. The movies such as The Incredibles, Finding Nemo and Alladin show high correlation with Toy Story.















































































