



According to The Overseas Development Institute, a London-based research establishment, whose findings were released in April 2009 in the paper “Providing aid in insecure environments:2009 Update”, the most lethal year in the history of humanitarianism was 2008, in which 122 aid workers were murdered and 260 assaulted.
As much as the underprivileged and unfortunate parts of society need aid in human form, it is equally important to establish a certain sense of security for uninterrupted services.
This aid usually has to reach places of great geographical inconvenience. This can be mainly attributed to war zones, the refugee crisis or lack of bare minimum natural resources. Detailed maps are important to help aid-workers and organisations to plan their logistics and mobilize relief around the world.
Though the options that existing maps offer are decent, they don’t give away much of the information at the ground level. For example, the population density of a location is important for the aid-workers to plan the infrastructure in advance so as not to fall short of food or medicine after reaching the affected areas. The census made available by the local authority in remote locations can’t be up to date.
Researchers at Facebook AI, propose a weakly and semi-supervised machine learning model to build high-resolution maps for the NGOs and other humanitarian organisations.
Targeting Road And Building Detection
In this paper, the team at Facebook focusses on mapping roads and building to help the aid workers.
For building detection, they used a combination of weakly-supervised and semi-supervised training techniques in conjunction with the freely available data in Open- StreetMap(OSM), the researchers were able to locate buildings in high-resolution satellite imagery.
The idea behind using this combination of weakly supervised learning techniques in
conjunction with simple heuristics is to train a semantic segmentation model for road extraction on noisy and never pixel-perfect training data from OSM.
“Most available datasets for road segmentation are heavily biased towards particular regions,” wrote the team in their paper titled Building High Resolution Maps for Humanitarian Aid and Development with Weakly- and Semi-Supervised Learning.
To ensure unbiased and accurate road mapping, a threshold is used on the number of roads mapped in a particular area to find areas that are more completely mapped; this data is then used to train a weakly supervised road segmentation problem.
Data collection challenges:
- The correctness of the data and over-representation of developed world maps in the existing datasets
- Ensuring the correspondence between OSM tags to the data; both temporally and spatially.
- OSM tagged features are precise but have an extremely low recall.
Creating the dataset:
The team started with a seed dataset of around 1 million labeled images and using weakly and semi-supervised techniques, a dataset of more than 100 million labeled training images are generated.
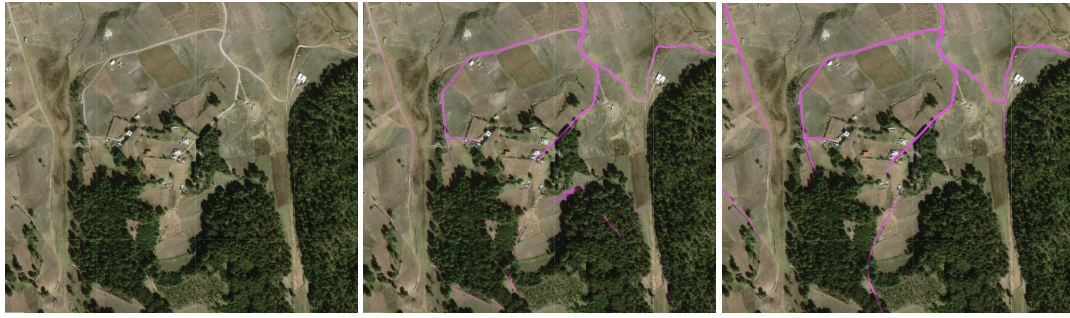
The above figure illustrates the road extraction from satellite imagery in rural Mexico. Left: Satellite Imagery. Middle: THA/IND/IDN trained model. Right: Global OSM trained model.
The model trained on DeepGlobe data misses the road in the top left almost entirely and leaves several roads in the middle of dense trees whereas the globally trained model performs well.
For every 100 automated labeled images created in the dataset, one image is manually labeled.
To keep the dataset generation simple, each edge of the road vector is converted to 5 pixel width lines. The model learns to predict roads that match the more complex twists and turns of the roads.
For mapping the buildings, a semi-supervised bootstrapping approach is implemented to restrict the error rate of non-building labels to below 1 per cent. And, for every labeled house pulled from a given region, an equal number of non-houses are randomly sampled, creating a dataset with a 50-50 building/non-building split.
Accounting for non-building is important as the existing dataset with no building regions might not have been originally mapped.
This work aims to tune the existing datasets and models that work well at the regional level but falter at the global scale. By paying more attention to road segmentation and building detection, the team at Facebook demonstrates that this model outperforms others trained on existing datasets.
Conclusion
These maps are already having a real-world impact. For example, the population density map produced for Malawi enabled the Red Cross to quickly and remotely map around 1 million houses and 120,000 km of roads for a measles and rubella immunization campaign.
This method of generating road vectors also came in handy last year during the Kerala floods when the existing mapping methods failed to aid the humanitarian workers effectively.
The datasets resulting from this work will be released as an update to the HRSL. The release will be done region by region as inter-disciplinary experts are involved ensure that the potential for misuse and abuse of this data is minimized and the accuracy of the resulting datasets meet the standards for release.
Know more about this work here














































































