



It is relatively easy for humans to learn a language. With years of practice subconsciously, we pick up nuances and stack up to the sophistication with the help of localised cultural cues. We have this complex mechanism where we meticulously derive deep meanings with the help of very few words.
For machines, which operate on inferences of binary nature, human language is almost an impossible task.
One way to do it is by predetermining the groups to which certain words belong to, segregating the useful words from stop words and appending a score to the relationship between two words in a sentence.
Latent Dirichlet Allocation (LDA) is one such technique designed to assist in modelling the data consisting of a large corpus of words. There is some terminology that one needs to be familiar with, to understand LDA:
Document: Probability distributions over latent topics
Topic: Probability distributions over words.
The word ‘topic’ refers to associating a certain word with a definition. For instance, when the machine reads-horse is black, it tokenizes the sentence and comes to the conclusion that there are two topics; horse which is an animal and black, a colour.
Plate Notation: For visually representing dependencies among the model parameters.
How Does LDA Work
What LDA actually does is topic modelling. It is an unsupervised algorithm used to spot the semantic relationship between words a group with the help of associated indicators.
When a document needs modelling by LDA, the following steps are carried out initially:
- The number of words in the document are determined.
- A topic mixture for the document over a fixed set of topics is chosen.
- A topic is selected based on the document’s multinomial distribution.
- Now a word is picked based on the topic’s multinomial distribution.
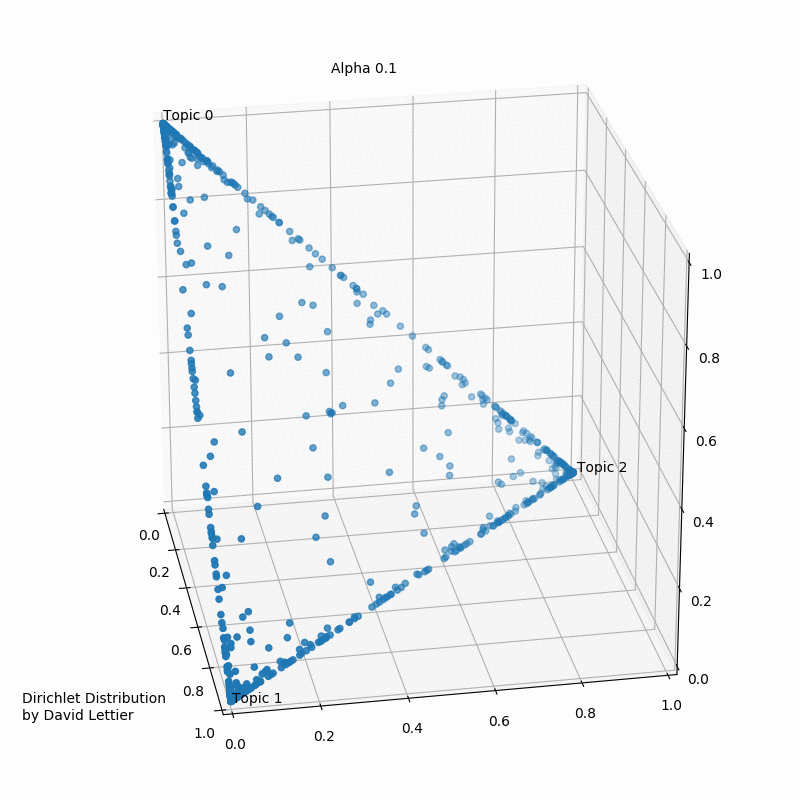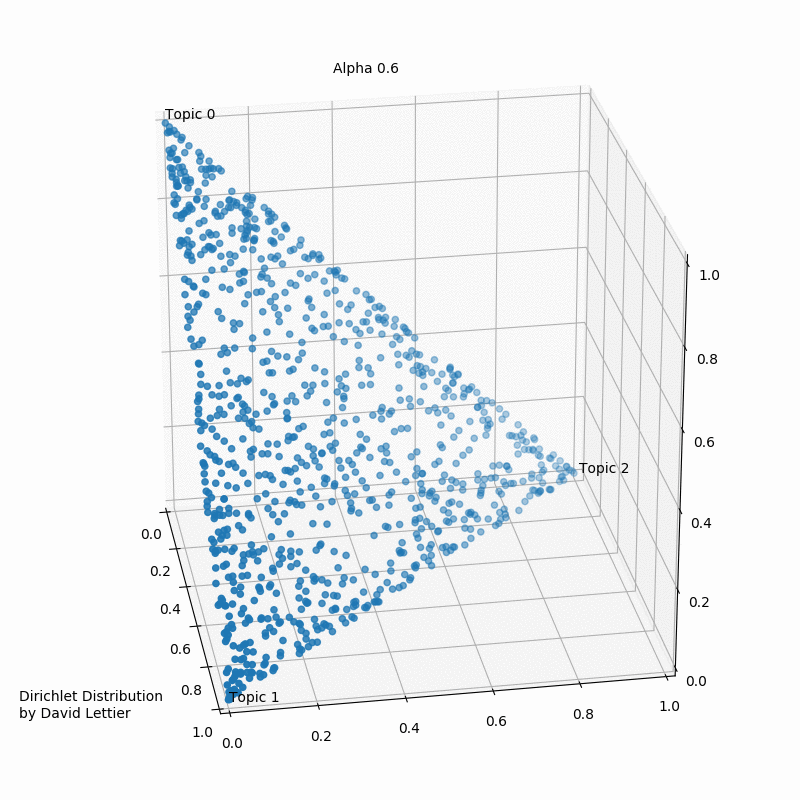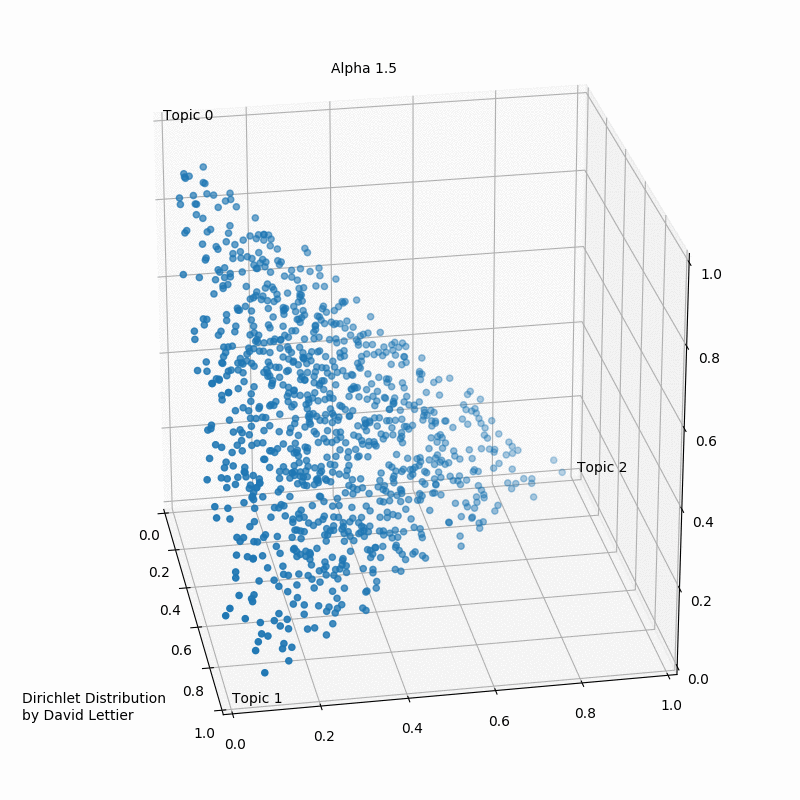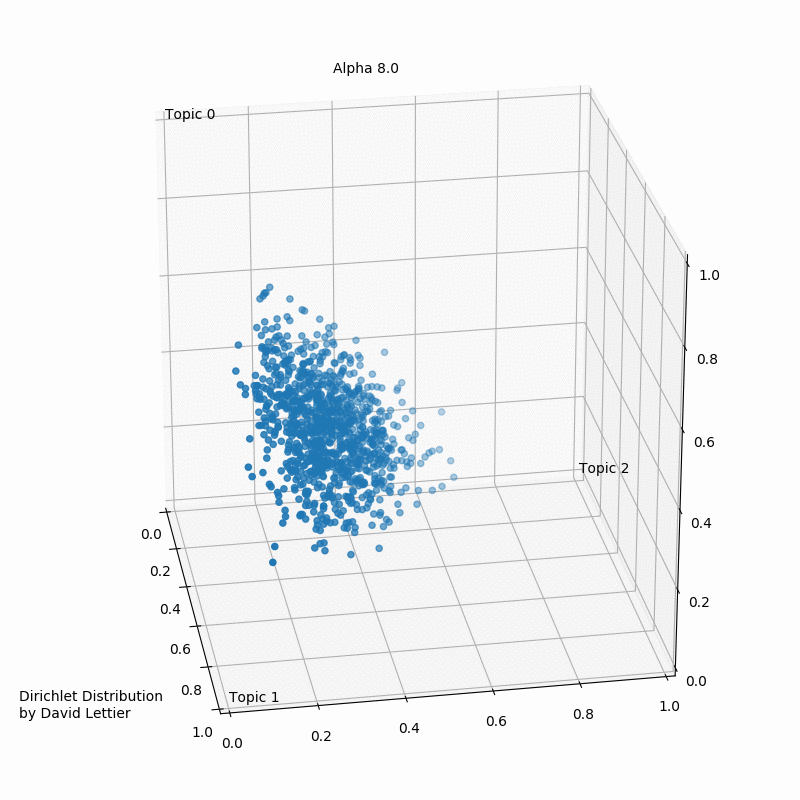 This visualization by David Lettier, serves as a very good representation of the distribution of a certain topic in a document. The edges of the apex points indicate that the probability of some word to belong to a topic reduces to null.
This visualization by David Lettier, serves as a very good representation of the distribution of a certain topic in a document. The edges of the apex points indicate that the probability of some word to belong to a topic reduces to null.
Looking At LDA From The Other End
LDA can be made to go backwards as well:
- First, each word in each document is randomly assigned to one of the topics.
- Now, it is assumed that all topic assignments except for the current one are correct.
- The proportion of words in document say, ‘d’ that are currently assigned to topic ‘t’ is equal to p(topic t | document d) and proportion of assignments topic ‘t’ over all documents that belong to word ‘w’ is equal to p(word w | topic t).
- These two proportions are multiplied and assigned a new topic based on that probability.
LDA assumes that the words in each document are related. Then after running through the aforementioned steps, it figures out how a certain might have been created. And, this very solution will be used to generate topic and word distributions over a corpus.
LDA Implementation In Python
Step 1: Initialising hyperparameters in LDA with alpha = 0.2 & beta = 0.001
# Text corpus iterations
corpus_iter = 200
K = 2
V = len(vocab_total)
D = len(text_ID)
word_topic_count = np.zeros((K,V))
topic_doc_assign = [np.zeros(len(sublist)) for sublist in text_ID]
doc_topic_count = np.zeros((D,K))
Step 2: Generate word-topic count matrix with randomly assigned topics
for doc in range(D):
for word in range(len(text_ID[doc])):
topic_doc_assign[doc][word] = np.random.choice(K,1)
word_topic = int(topic_doc_assign[doc][word])
word_doc_ID = text_ID[doc][word]
word_topic_count[word_topic][word_doc_ID] += 1
print('Word-topic count matrix with random topic assignment: \n%s' % word_topic_count)
Output:
Word-topic count matrix with a random topic assignment:
[[ 1. 0. 2. …, 5. 0. 0.]
[ 0. 1. 0. …, 7. 1. 1.]]
Check the full code here.
Conclusion
Latent Dirichlet allocation was introduced back in 2003 to tackle the problem of modelling text corpora and collections of discrete data. Initially, the goal was to find short descriptions of smaller sample from a collection; the results of which could be extrapolated on to larger collection while preserving the basic statistical relationships of relevance.
Apart from detecting topics in texts and doing sentiment analysis, LDA has also found its application in Bioinformatics, harmonic analysis for music and even object localisation for images.








































































