


|
Listen to this story
|
Microsoft’s recent works have been shrouded in privacy, and left everyone in anticipation, over how it would leverage OpenAI’s partnership for its own products. It was the same when it suddenly released Bing chat, without any public information on what the model is trained on, how it is trained, and its overall infrastructure.
If we look at the announcement of the launch of Bing AI, the description referred to it as “OpenAI large language model more powerful than ChatGPT” with the pseudonym ‘Prometheus’. As vague as the description sounds, it highlights the whimsical nature of big tech to play the AI race game at the cost of real value addition.
The lack of transparency regarding AI models is not unique to Microsoft, as Google has also been reticent about the inner workings of its chatbot ‘Bard’. With much at stake, these tech companies tend to claim credit when the model succeeds but absolve themselves of any and all responsibility when it fails.
What makes companies like OpenAI seem slightly better than big tech corporations is the transparency of their models. OpenAI’s ChatGPT is an example of building in public.
Microsoft’s immediate remedy
In response to the repetitive and provoked responses to its recently released Bing AI, Microsoft took a backseat and put limitations on the number of chats by a single user per day.
The number—which started at 50—reached 100 a day ago, a goal which Microsoft had set for itself. In its blog, Microsoft revealed that extended chat sessions of 15 or more questions can “confuse” the model, leading Bing to be repetitive, or even provoked, and provide responses that are not necessarily in line with its tone of design.
To combat the problem, Microsoft proposed a few ways. Firstly, the company is considering adding a tool which can “easily refresh the context or start from scratch” to avoid the model getting confused on what questions it is answering. PCWorld likens this to a slider in the world of AI art, where users can select the “guidance” or how closely the algorithm’s output matches the input prompt. Weaker guidance allows the algorithm more room for creativity, but also skews the results in unexpected directions.
Additionally, Microsoft also addressed that the provoked responses constitute a “non-trivial scenario” and they are looking to give users more fine-tuned control.
Despite these insights on what it may plan to do, there is no concrete information on how the tech giant plans to fine-tune the models and whether ‘fine-tuning’ will be the end solution for them.
AIM reached out to Microsoft for a comment on how exactly they plan to improve the model, but—perhaps to no surprise—are yet to receive a response.
However, it looks like Microsoft is leaning on OpenAI to rescue itself from the Bing chat mess.
Following OpenAI’s steps
Around the time Microsoft shared their plans on what they intend to do forward, OpenAI also released a technical blog on their approach to addressing bias in AI systems. The not-for-profit company revealed that the current method—consisting of pre-training and fine-tuning—has not been enough.
Pre-training the model involves training it on a large number of datasets and, naturally, these datasets also will have biased materials. To ensure the results of the model are not biased, the datasets are fine-tuned through various reviewers. Essentially, the company manually creates rules that filter the output of the model on a few categories and redirects a particular set of output to these responses.
However, as the company concurred, this process is imperfect. To improve on the existing model, OpenAI will be adding several building blocks to the two-part process in efforts to further understand and add more control to the fine-tuning process. These blocks will be based on public input on what the bounds of the model should be to ensure it is not used for malicious purposes.
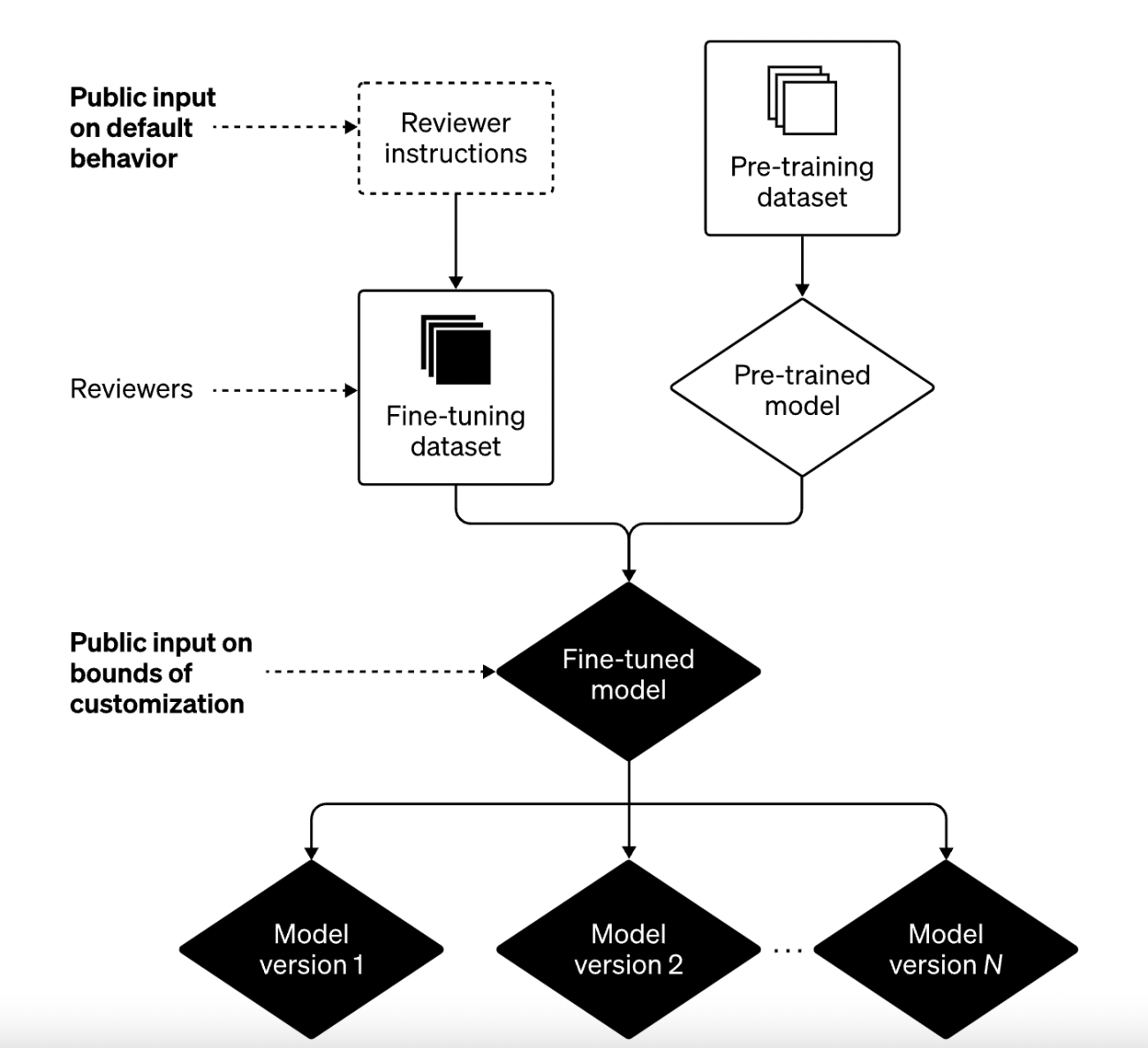
Therefore, the way forward for them has been to enable a customisable solution for each user as long as it is within the limits defined by the public. This approach, however, can be argued to result in the creation of individual echo chambers similar to what AI algorithms have been facilitating for some time now.
There is a larger issue looming around the lack of regulation in AI. The whole facade of making everything seem fine could serve as a signal for the government to step in. The AI governance aspect has been sorely missing from the language model narrative, thus giving complete freeway to anyone who wishes to release an LLM at any scale they desire, with little to no oversight.




































