



|
Listen to this story
|
The year 2024 seems to be one of long contexts, quite literally. There’s Anthropic’s Claude 3 with a context window of 200K (goes up to 1 million tokens for specific use cases) and Google’s Gemini 1.5 with a 1M context length window.
Meta’s Llama 3 has become the latest muse for the online developer community with many users coming up with wild use cases everyday such as that by Gradient, where it extended LLama-3 8B’s context length from 8k to over 1048K.
However, this is just the start because now it’s the race from long context length to infinite context length, with all big companies like Microsoft, Google, and Meta taking strides in this direction.
All this has ignited the ‘long context vs RAG’ debate yet again.
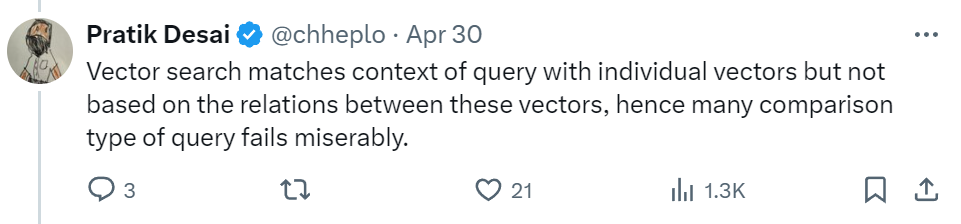
Does RAG Really Suck?
RAG, or retrieval augmented generation, was introduced as a solution to address the challenge of LLM hallucinations by extending the model’s capabilities to external sources, vastly widening the scope of accessible information.
This seemed to be a good idea, for till just about a year ago context windows were somewhere in the range of 4K to 8K tokens. But now, with long context, if we can stuff a million tokens into an LLM, which is like thousands of pages of text or hundreds of documents, then why do we any longer need an index to actually store those documents?
This has left many wondering if ‘it’s time-up for RAG?’
After all, RAG comes with its own set of limitations, such as while it is most useful in ‘knowledge-intensive’ situations where a model needs to satisfy a specific ‘information need’, it’s not that effective in ‘reasoning-intensive’ tasks.
Models can get distracted by irrelevant content, especially in lengthy documents where the answer isn’t clear. At times, they just ignore the information in retrieved documents, opting instead to rely on their built-in memory.
Using RAG can be costly due to the hardware requirements for running it at scale as retrieved documents have to be temporarily stored in memory for the model to access them. Another expenditure is compute for the increased context a model has to process before generating its response.

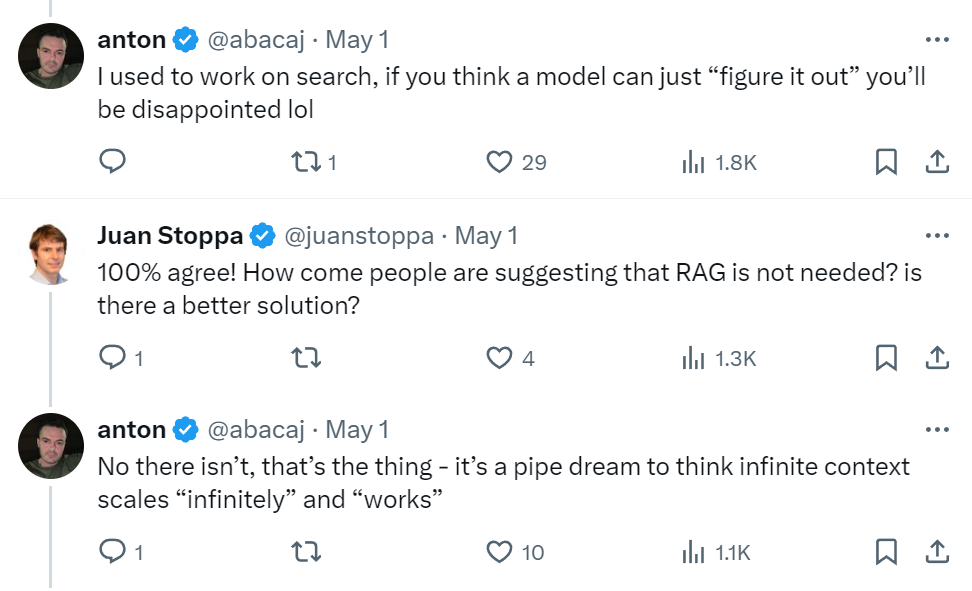
Are Long-Context LLMs Foolproof?
If long context LLMs can really replace RAG, then they should also be able to retrieve specific facts from the context you give them, reason about it, and return an answer based on it. But guess what? Even long-context LLMs are too stubborn with hallucinations.
The paper ‘Lost in the Middle: How Language Models Use Long Contexts’ explains that LLMs exhibit high information retrieval accuracy at the document’s start and end. However, this accuracy declines in the middle, especially with increased input processing.
Another analysis, called ‘Needle In A Haystack’ that tests reasoning & retrieval in long context LLMs, highlights the fact that as the number of needles (correct data facts spread across the context to be retrieved) goes up in long context, the performance of an LLM goes down.
While short-context LLMs (about a thousand tokens) can effectively retrieve facts from the given context, LLM’s ability to recall details diminishes as the context lengthens, particularly missing facts from earlier parts of the document.
This issue stems from what is known as recency bias in LLMs, where due to its underlying training, the model puts greater emphasis on more recent or nearby tokens to predict the next token when generating responses. This way, the LLM learns a bias to attend to recent tokens than earlier ones in answer generation, which is not a good thing for retrieval tasks.
Source: X
Then there are high cost, high token usage, and high latency issues to consider when choosing long context LLMs over RAG.
If you choose to ditch RAG and instead stuff all your documents into the LLM’s context, then for each query, the LLM will need to handle one million tokens. For example, if you use Gemini 1.5 Pro, which costs approx $7 per million tokens, you will essentially be paying this amount every time the full million tokens are utilised in a query.
The price difference is stark as the cost per call with RAG is a fraction of the $7 required for a single query in Gemini 1.5, especially for applications with frequent queries.
Additionally, there’s latency to consider because each time a user submits a query they must provide the complete context or full information to Gemini to obtain results. This requirement can introduce significant overhead.
RAG is versatile across various domains like customer service, educational tools, and content creation. In contrast, when using long context LLMs you might need to ensure that all necessary information is correctly fed into the system with each query.
It requires continuously updating the context for different applications, such as switching from customer service to education, which can be inconvenient and repetitive.
Once the information is stored in a database for RAG, it remains accessible and only needs updating when data changes, like adding new products. This is simpler compared to using long context LLMs, where adjusting context repeatedly is necessary, potentially leading to high costs and inefficiency in obtaining optimal outputs.
RAG Survives The Day
It’s not long context vs RAG, but combining RAG with long-context LLMs that can create a powerful system capable of effectively and efficiently retrieving and analysing data on a large scale.
RAG is not limited to vector database matching anymore, there are many advanced RAG techniques being introduced that improve retrieval significantly.
For example, the integration of Knowledge Graphs (KGs) into RAG. By leveraging the structured and interlinked data from KGs, the reasoning capabilities of current RAG systems can be greatly enhanced.
Also, there are many ongoing efforts to train models to make better use of RAG-retrieved documents.
Some approaches involve models that can autonomously decide when to access documents, or even opt not to retrieve any if deemed unnecessary. Additional efforts are concentrated on developing more efficient ways to index massive datasets and enhance document search capabilities beyond mere keyword matching.
There’s the concept of representation indexing which involves using an LLM to summarise documents, creating a compact, embedded summary for retrieval. Another technique is ‘Raptor’, a method to address questions that span multiple documents by creating a higher level of abstraction. It is particularly useful in answering queries that involve concepts from multiple documents.
Methods like Raptor go really well with long context LLMs because you can just embed full documents without any chunking.
So, time to finally settle the debate. No, RAG isn’t dead. But, yes, it’s likely to change and get better. The developer ecosystem is already experimenting with RAG, like building a RAG app with Llama-3 running locally and many enterprises are also coming up with new developments like Rovo, a new AI-Powered knowledge discovery tool unveiled by Atlassian.




































