

The largest trained dense models have grown by nearly 1,000 times in the last three years, from a few hundred million to over 500 billion parameters in Megatron-Turing NLG 530B (MT-NLG). However, maintaining model size expansion is becoming more difficult because of rising computing requirements. Therefore, numerous attempts have been made to minimise the amount of compute required to train large models without affecting model quality. To that end, architectures based on Mixture of Experts (MoE) have blazed a trail, allowing for sub-linear compute requirements in accordance with model parameters and enhanced model quality without increasing training costs.
MoE models, on the other hand, have their own set of difficulties.
First, MoE models are mostly restricted to encoder-decoder models and sequence-to-sequence tasks.
Second, while MoE models require less compute, they require more parameters to reach the same model quality as their dense counterparts, which necessitates more memory for training and inference.
Finally, MoE models make inference difficult and expensive because of their vast size.
What is DeepSpeed?
To address the issues on MoE models, the DeepSpeed team has been investigating novel applications and optimisations for MoE models at scale as part of Microsoft’s AI at Scale effort. These can reduce the cost of training and inference for large models while also allowing the next generation of models to be trained and served on today’s technology.
DeepSpeed is a PyTorch-compatible module that dramatically improves large model training by increasing scale, performance, cost, and usability, allowing models with over 100 billion parameters to be trained. ZeRO 2, a parallelised optimiser in the DeepSpeed toolkit, drastically reduces the resources required for model and data parallelism while dramatically expanding the number of parameters that the model can learn.
How DeepSpeed leverages MoE
DeepSpeed reduces training costs by 5x
Microsoft demonstrates that MoE can lower the training cost of NLG models like the GPT family or MT-NLG by 5x while maintaining the same model quality, expanding the applicability of MoE models beyond encoder-decoder models and sequence-to-sequence tasks. As a result, data scientists can now train models of superior quality that previously required 5x the amount of hardware.
DeepSpeed reduces MoE parameter sizes by up to 3.7x
MoE’s reduced training costs come at the cost of increasing the total number of parameters required to achieve the same model quality as dense models. PR-MoE is a hybrid dense and MoE model built using residual connections that only applies experts where they are most useful. PR-MoE decreases the size of MoE model parameters by up to 3x while maintaining model quality. In addition, Microsoft uses staged knowledge distillation to learn a Mixture-of-Students model, which reduces the model size by up to 3.7x while maintaining model quality.
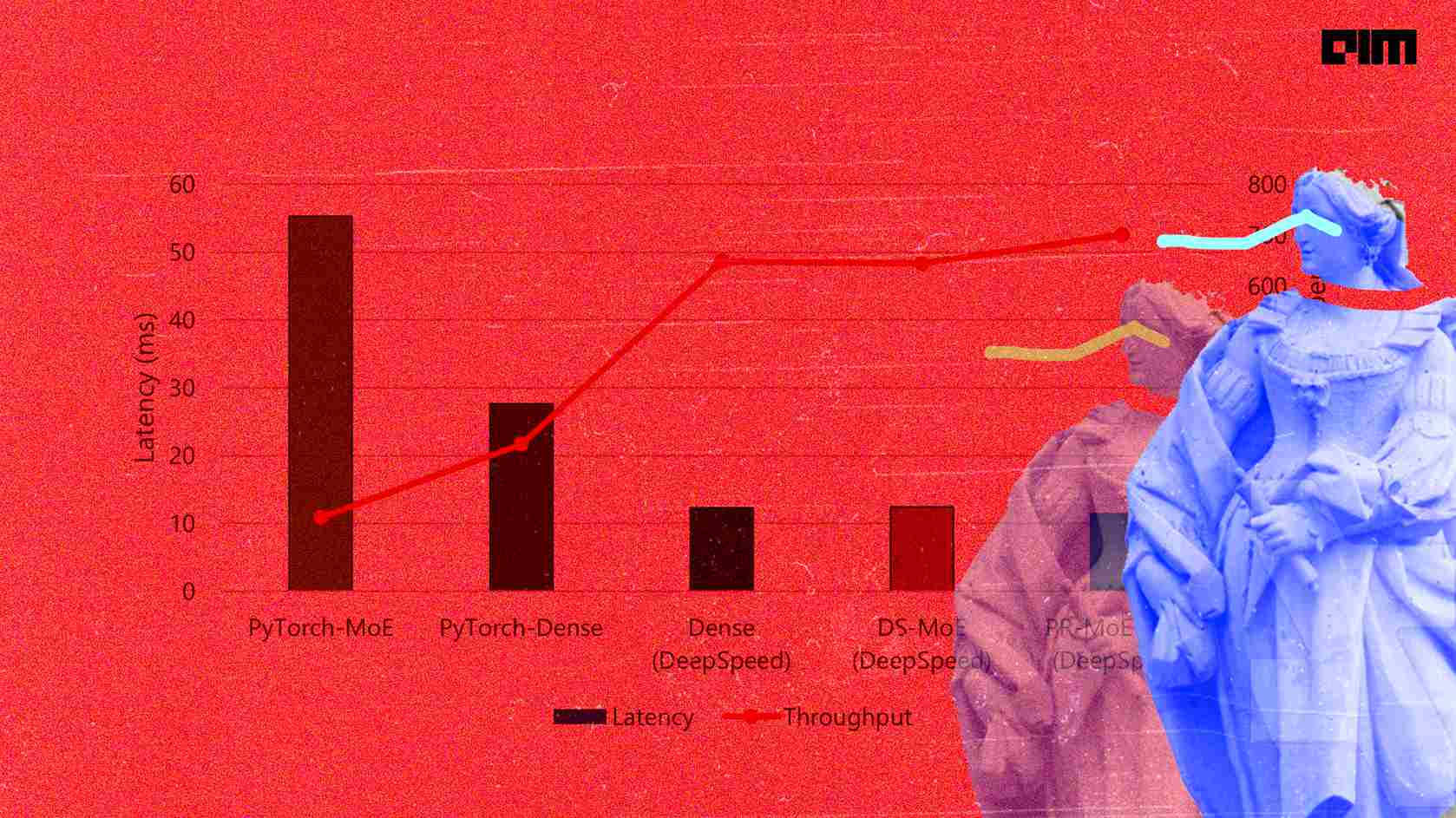
DeepSpeed reduces MoE inference latency by 7.3x on an unprecedented scale and provides up to 4.5x faster and 9x cheaper inference for MoE models than quality-equivalent dense models.
Compared to conventional systems, the DeepSpeed-MoE (DS-MoE) inference system allows for effective scaling of inference workloads across hundreds of GPUs, resulting in a 7.3x reduction in inference latency and cost. Furthermore, for trillion-parameter MoE models, it provides ultra-fast inference latencies (25 ms). By integrating both system and model optimisations, DS-MoE can provide up to 4.5x faster and 9x cheaper inference for MoE models than quality-equivalent dense models.
Overall, the breakthroughs and infrastructures present a potential path toward training and inference of the next generation of AI scale without more compute resources. Furthermore, a move from dense to sparse MoE models might pave the way for new paths in the large model landscape, such as deploying higher-quality models with fewer resources and making large-scale AI more sustainable by lowering its environmental impact.
Also Read: DeepSpeed Vs Horovod: A Comparative Analysis





























