


|
Listen to this story
|
Text to image models emerged in the mid-2010s due to advancements in deep neural networks. However, much before ChatGPT, the buzz around generative AI grew with text-to-image models OpenAI’s DALL-E, Google Brain’s Imagen, and StabilityAI’s Stable Diffusion. These generative AI models have garnered attention because of resembling real photographs and hand-drawn artwork.
Best Open Source Text to Image Models
So, let’s take a look at the top six open-source image generation models that can come to your help.
DeepFloyd IF
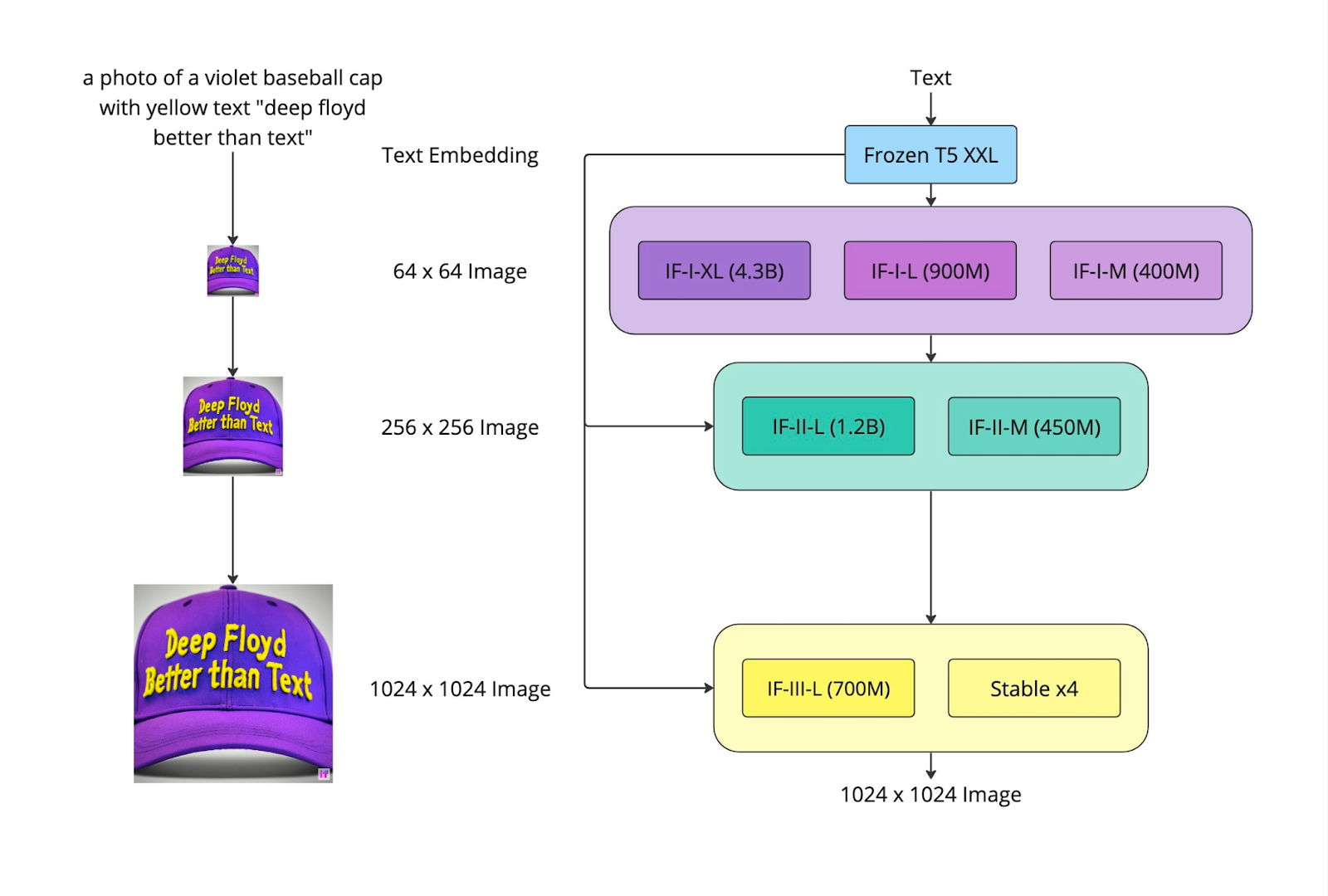
Backed by Stability AI, research group DeepFloyd’s open-source text to image model DeepFloyd IF combines realistic visuals and language comprehension. It consists of a modular design, featuring a fixed text encoder and three interconnected pixel diffusion modules. The initial module generates 64×64 px images based on text prompts, while the subsequent super-resolution modules create images of increasing resolution: 256×256 px and 1024×1024 px. The entire model leverages a frozen text encoder derived from the T5 transformer to extract text embeddings. These embeddings are then utilized in a UNet architecture, which is enhanced with cross-attention and attention pooling. As a result, this model surpasses existing models, achieving an impressive zero-shot FID score of 6.66 on the COCO dataset.
Check out their GitHub repository here.
Stable Diffusion v1-5
Latent text to image model Stable Diffusion v1-5 merges an autoencoder with a diffusion model to create photo realistic images. It has been trained on the extensive laion-aesthetics v2 5+ dataset and fine-tuned over 595k steps at a resolution of 512×512 pixels, this model has the remarkable capability of generating highly realistic images based on any given text input. It has flexibility in generating images from a wide range of latent spaces, as opposed to being restricted to a fixed set of text prompts. Its training on a large image dataset enables it to possess a deeper understanding of image characteristics, resulting in more lifelike image generation.
Stable Diffusion v1-5 is accessible in both the Diffusers library and the RunwayML GitHub repository. Check it out here.

OpenJourney
Openjourney is a free, open-source text-to-image model that produces AI art in the style of Midjourney as it is trained on a dataset of over 124k Midjourney v4 images. It’s a fine-tune of Stable Diffusion. Developed by PromptHero, a leading prompt engineering website, Openjourney is the second most downloaded text-to-image model on HuggingFace, following Stable Diffusion. Users prefer Openjourney for its ability to generate impressive images with minimal input and its suitability as a base model for fine-tuning.
Click here to access the model.

DreamShaper
Built on diffusion model architecture, fan favourite Dream Shaper V7 introduces improvements in LoRA support and overall realism. It builds upon the enhancements made in Version 6, which included increased LoRA support, general style improvements, and better generation at a height of 1024 pixels (though caution is advised when using this feature). It produces photorealistic image with a noise offset, and enhances anime-style generation with booru tags. It also improves eye performance at lower resolutions, serving as a “fix” for earlier versions. The impact of Version 3.32’s “clip fix” may differ from Version 3.31, recommending its use for mixing. It also involves inpainting and outpainting.
If you want to know more about it, check this out.

Dreamlike Photoreal
Dreamlike Photoreal 2.0 is a photorealistic model based on Stable Diffusion 1.5. Made by DreamlikeArt, you can enhance the realism of your generated images by incorporating photos into your prompt. For best results, use non-square aspect ratios. For portrait-style photos, a vertical aspect ratio is recommended, while a horizontal aspect ratio is more suitable for landscape photos. This model was trained on images with dimensions of 768×768 pixels, although it can also handle higher resolutions like 768x1024px or 1024x768px effectively. Running on server-grade A100 GPUs, it boasts an average generation speed of 4 seconds, surpassing the performance of 8x RTX 3090 GPUs. With the capability to process up to 30 images simultaneously and generate up to 4 images concurrently, it ensures an efficient workflow. It includes several features like upscaling, natural language editing, facial enhancements, pose, depth, sketch replication, and others.
You can access it here.

Waifu Diffusion
Last but not the least, we have Waifu Diffusion, a fine-tuned version (1.3) of the Stable Diffusion model, derived from Stable Diffusion v1.4. This model specialises in generating realistic anime-style images and has gained recognition for its impressive variety and high quality.
The model was trained on dataset of 680k text-image samples obtained from a booru site.
Find their GitHub repository here.





































