



|
Listen to this story
|
After introducing ‘Make-A-Video,’ a team of scientists from Meta have released ‘AudioGen’, jointly with the University of Jerusalem. An auto-regressive generative model that generates audio samples based on text inputs. It operates on learnt discrete audio representations; for this, the team curated ten datasets that contained different types of audio and text annotations to resolve the problem of text-audio data points scarcity.
What is AudioGen
The authors of this research have set out to find the answer to ‘what would be an audio equivalent to textually guided generative models?’ They discovered that a solution to this problem is a high fidelity and controllable tool that is diverse in its outputs.
While image generation and audio generation have much in common, the latter has some unique challenges. To begin with, audio is a one-dimensional signal that offers a lesser degree of freedom to differentiate between overlapping objects. Further, real-world audio has reverberations due to which differentiating objects from the surrounding environment becomes much harder. Lastly, the availability of audio data with textual descriptions is scarce, as compared to text-image paired data—making the generation of unseen audio compositions a major challenge, or as the researchers explain in the paper, generating an audio equivalent of ‘horse riding an astronaut in space.’
Through AudioGen, the researchers attempted t0 solve the problem of generating audio samples that are conditioned on descriptive text captions. For a given prompt, the model generates three categories of acoustic content with varying degrees of background/foreground, durations, and relative position in the temporal axis.
AudioGen consists of two main stages. The first one encodes raw audio to a discrete sequence of tokens that uses a neural audio compression model, which is trained in an end-to-end fashion to reconstruct the input from a compressed representation. Such audio representation can generate high-fidelity audio samples while being compact.
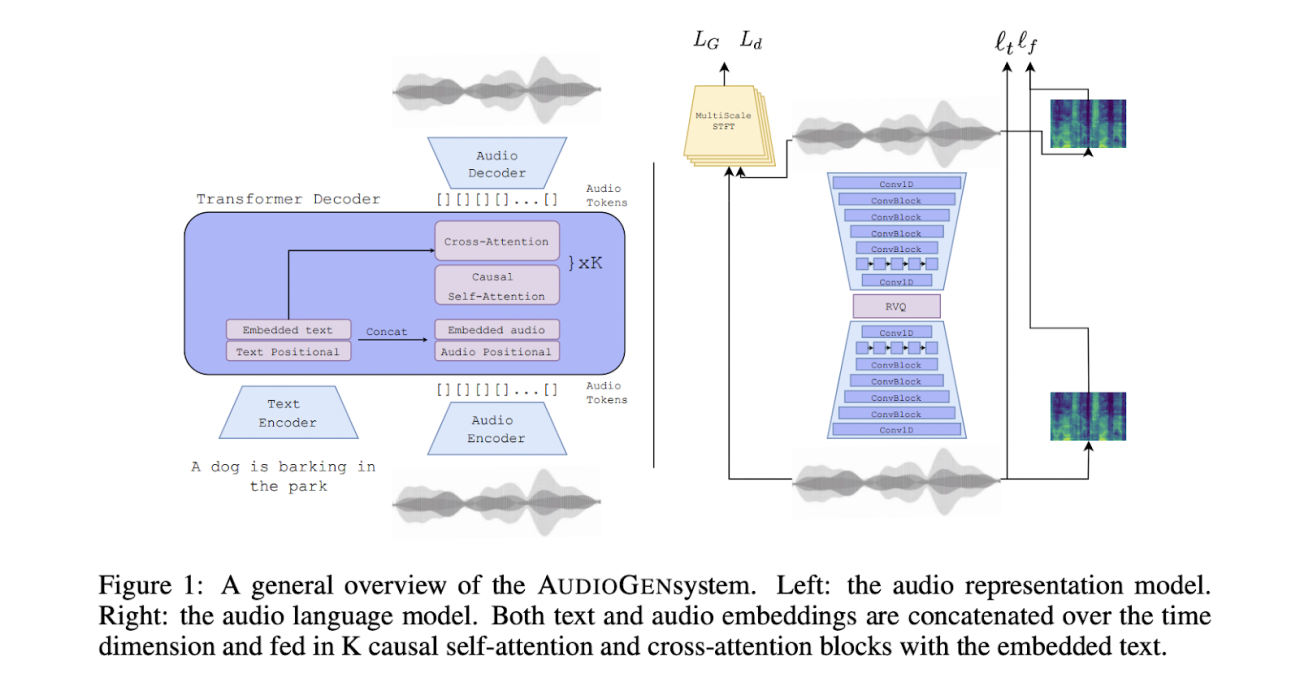
The second stage uses an autoregressive Transformer-decoder language model that operates on discrete audio tokens that are obtained from the first stage and is also conditioned on textual inputs. The text is represented using a separate text encoder model that is pre-trained on T5 (a large text corpus). This pre-trained text encoder enables generalisation to text concepts. This is important in cases where text annotations are limited in diversity and descriptiveness.
AudioGen generates samples to obtain better objective and subjective metrics and creates more natural-sounding unseen audio compositions. It can also be extended to audio continuation considering both conditional and unconditional generation.
The team has proposed two model variations—one with 285 million parameters and the other with 1 billion parameters. The text-to-audio generation is improved on two axes—improving text adherence by applying classifier-free guidance on top of the audio language model and improving compositionality by performing on-the-fly text and audio mixing.
Read the full paper here.
Age of text-to-anything
With the introduction of DALL.E and, subsequently, DALL.E 2, a new trend in AI ushered in. Many other AI firms came up with their own versions of text-to-image generating tools, the most prominent being ‘Midjourney’, ‘Stable Diffusion’, and Google’s ‘Imagen’. While Midjourney and Stable Diffusion were open sourced from the word go, OpenAI has recently removed the waitlist for DALL.E usage. That said, Google’s ‘Imagen’ is yet to be open-sourced and the company has no plans of doing so considering the challenges related to ethics and governance.
OpenAI added a few more features to DALL.E like Outpainting. This feature allows DALL.E to continue the image beyond the original borders by adding visula elements in the same style by using natural language description. Google researchers then adopted a new approach to 3D synthesis – allowing users to generate 3D models using text prompts. It is called DreamFusion.
Next came text-to-video generation. Meta recently launched ‘Make-a-Video,’ a new AI system that allows users to generate high quality video clips using text prompts. On the heels of this announcement, Google has now launched Imagen Video. The results are not perfect – it contains artifacts and noise, but Google claims that its model displays a high degree of controllability and the ability to generate footage in a range of artistic styles.
All this shows that text-to-X field is growing at a neck-breaking rate. So much so that it often becomes difficult to keep up. As a Twitter user pointed out:















































































