


 The last step in creating corporate data from spreadsheets is the creation of the corporate database itself. The corporate database is created when –
The last step in creating corporate data from spreadsheets is the creation of the corporate database itself. The corporate database is created when –
- The spreadsheet has been selected
- The spreadsheet has been logged in
- The spreadsheet has been run through spreadsheet disambiguation technology
At this point the data and the metadata from the spreadsheet have been stripped from the spreadsheet. Fig 1 shows this progression –

The data that is put in the corporate data base consists of –
- Column name
- Row id name
- Value
- Spreadsheet system name
- Date of processing
Fig 2 shows the contents of the corporate data after processing –

The column name and the row id name serve to identify the value. The spreadsheet system name identifies the source of the data, and the date filed determines what particular day the spreadsheet was processed. Spreadsheet system name and date of processing are needed to satisfy lineage requirements, and column name and row id name are needed to provide the metadata that is associated with the value.
On occasion, it may be necessary to delete one or more entries into the corporate data. This is because sometimes spreadsheets contain extraneous or spurious data. The spreadsheet disambiguation program picks up ALL elements of data on the spreadsheet. So it is possible that unwanted data arrives in the spreadsheet corporate data input. If that is the case then those unwanted elements of data are “weeded out”.
Fig 3 shows the weeding out of unwanted data before it is placed into corporate data.

One of the features of corporate data is that it usually is arranged by subject area. But when data comes out of spreadsheet disambiguation, it comes out as it was laid out on the spreadsheet. For this reason, it is often convenient to divide the corporate data by subject area before finalizing the corporate database.
Fig 4 shows this activity.

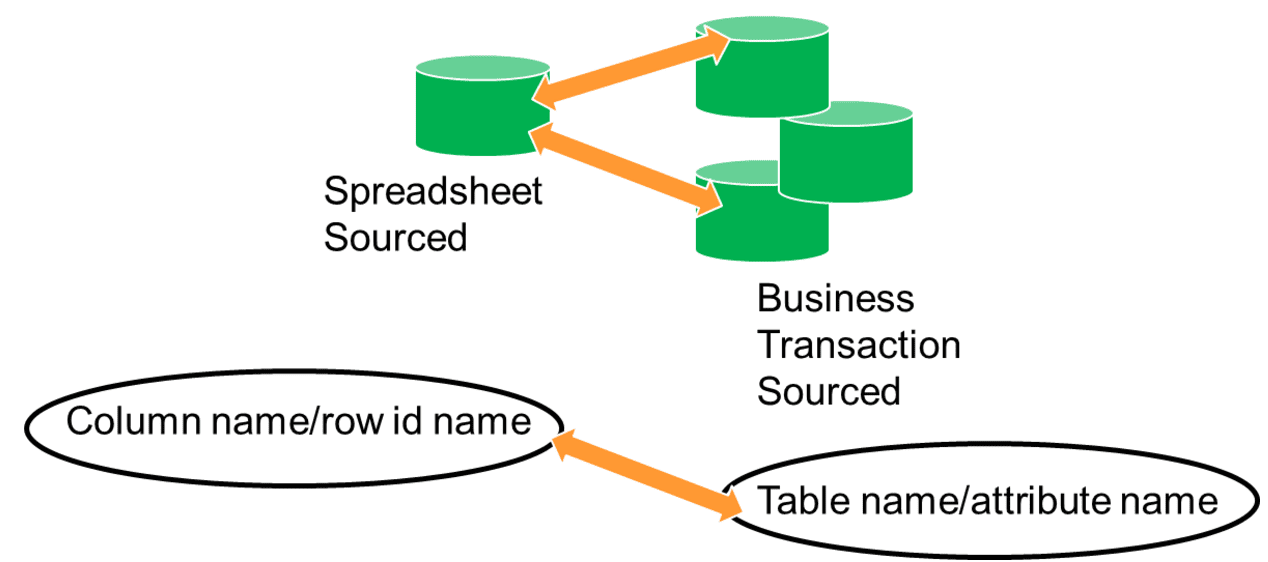
A final consideration of corporate data coming from spreadsheets and corporate data coming from other sources is that once the spreadsheet data has been cast into the form of corporate data, it can be freely mixed with other corporate data.
Fig 5 shows this capability.

The ability to integrate spreadsheet data with other corporate data easily is one of the major advantages of moving spreadsheet data to the corporate data environment. The analyst finds this capability to be very useful.
The integration is achieved by using the column name/row id metadata and comparing it to the metadata that is already found in the corporate data environment.
Fig 6 shows this interaction.
Bill Inmon – the “father of data warehouse” – has written 57 books published in nine languages. Bill was named by ComputerWorld as one of the ten most influential people in the history of the computer profession. Bill lives in Castle Rock, Colorado.
Bill’s latest book is TURNING TEXT INTO GOLD, Technics Publications, a book that shows how text can be turned into business value. TURNING TEXT INTO GOLD is available on Amazon.com.







































































