



|
Listen to this story
|
Most of the AI and ML models developed for domains like healthcare, business, and critical governance domains have to be very robust. Models developed for this domain should be robust and able to come up with the right predictions for any uncertainty or causal effect in the data. DoWhy is one of the frameworks formulated for handling causality efficiently and is used to build critical domain models which will have the ability to yield the right predictions even if there are any causal effects. In this article, let us try to understand the DoWhy causal inference approach by building a model for medical analysis.
Table of Contents
- What is Causal Inference?
- The necessity of Causal Inference
- The DoWhy Framework
- Building a Medical inferencing model using DoWhy
- Summary
What is Causal Inference?
Causal inference is basically used to understand the effect of one of the features with respect to other features.
Causal inference basically cross validates the effect of one variable on the other and suitably validates that cause to the effect. This cross-validation among the various features of the data makes the data remain robust for unseen changes and ensures the right predictions are yielded from the models for all possible causal inferences.
Many machine learning algorithms basically use standard statistical analysis and certain hypothesis testing statements to validate the distributions of features. This helps in assessing certain important characteristics of features in the data and helps to yield the right predictions from the models developed. Correlation and casualty appear to be similar but correlation does not consider the effect of causality. So just relying on correlation would not be the right move in developing models for critical domains.
Causal inference can be used as an efficient tool for accurate data analysis and wherein the analysis can be used to make predictions interpretable from the models developed. With this introduction to causal inference let us look into the necessity of causal inference in the next section of this article.
The necessity of Causal Inference
As mentioned earlier, causal inference benefits the development of efficient predictive models. Many times predictive models will not have the ability to capture the necessary patterns between the input feature and the reason for that respective prediction. So to make such interpretations from predictive models causal inference is useful.
So let us summarize the need for causal inference in points for better understanding.
- Causal inference can be necessary to interpret for any improvement in the prediction by altering any of the features.
- Causal inference may be necessary to validate the change in the prediction that was caused by changing the model architecture.
- Causal inference is necessary to yield the most likely outcome as it considers the cause and effect of individual features among the various features.
- Causal inference is necessary to ensure that the assumptions made are explicit.
- Causal inference is necessary to validate the robustness and to validate the robustness in predictions from the models developed.
The DoWhy Framework
DoWhy is one of the frameworks formulated and structured to facilitate causal inference in critical domain modeling easily. DoWhy will be used as a framework to carry a complete end-to-end causal inference for developing robust models for critical domains.
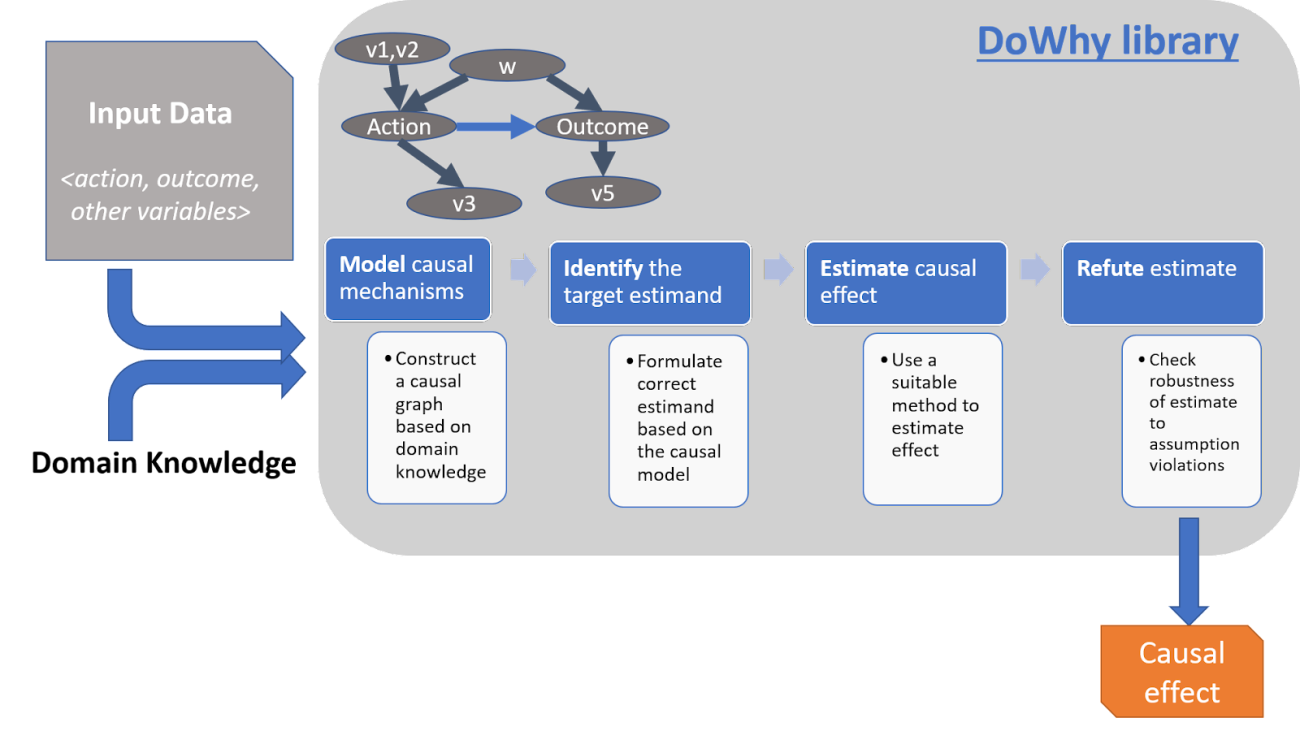
The DoWhy framework uses a four-step framework to make causal inferences and to focus on explicit assumptions made. The DoWhy framework will operate on data acquired from critical domains and that data will be handled suitably using domain expertise. The Refutation feature of DoWhy is very beneficial for validating the assumptions and the causality of the prediction with respect to the various assumptions being made. The DoWhy framework also integrates with another framework named EconML for estimating the average causal effect for various features and estimating the conditional effects of various features.
Steps involved in formulating a causal inference problem
There are mainly four steps involved in formulating a causal inference problem using the DoWhy framework and they are as mentioned below.
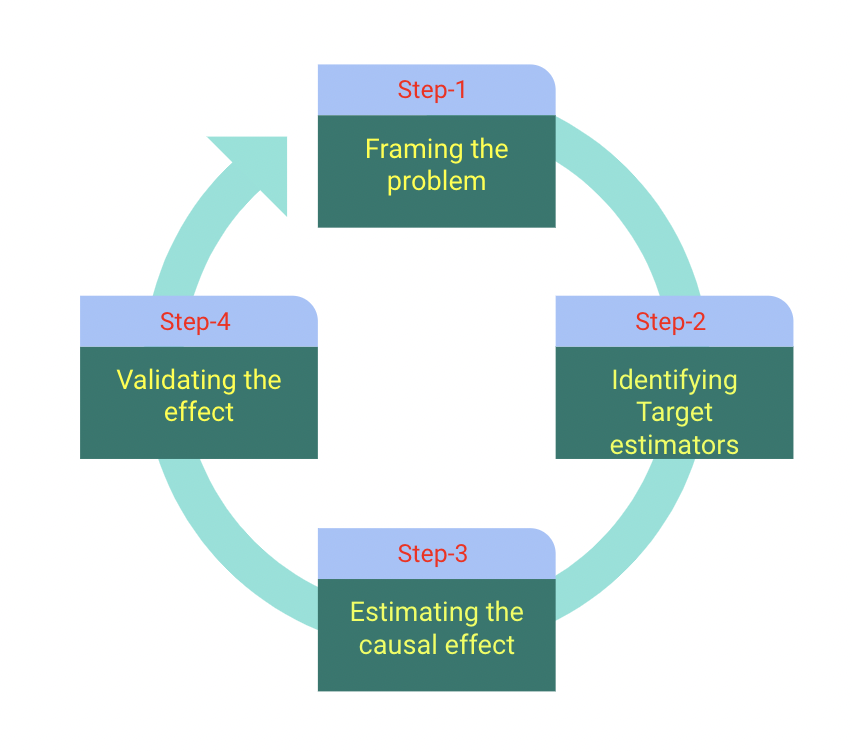
Let us try to understand how the causal problem is formulated in the DoWhy framework.
i) Framing stage of the DoWhy framework is responsible for creating a causal graph and validating the explicitness of the causal assumption being made. The explicitness of the causality will be validated through the graph and through domain expertise.
ii) Identification stage of the DoWhy framework is responsible for identifying all possible causes and the respective effects of the causes. It uses graph-based criteria to evaluate and validate the causality of the assumptions being made.
iii) Estimation stage of the DoWhy framework is responsible for estimating the causality for particular assumptions being made. This validation is carried out by using standard stratification techniques, regression techniques, instrument variables, and two-stage regression techniques.
iv) Validating Estimation stage of the DoWhy framework is responsible for validating the rightness of the assumptions made and the casualty for that respective assumption.
Building a Medical inferencing model using DoWhy
Let us see through a case study how to formulate a causal inference model that can be applied to find out the best suitable treatment method. This model will use the patient’s data and build a causal model to find the dependencies among the features.
Let us first install the DoWhy framework and import the required libraries.
!pip install dowhy import dowhy from dowhy import CausalModel import pandas as pd import numpy as np
For the case study in this article let us make use of the IHDP dataset which has various features associated with the healthcare domain.
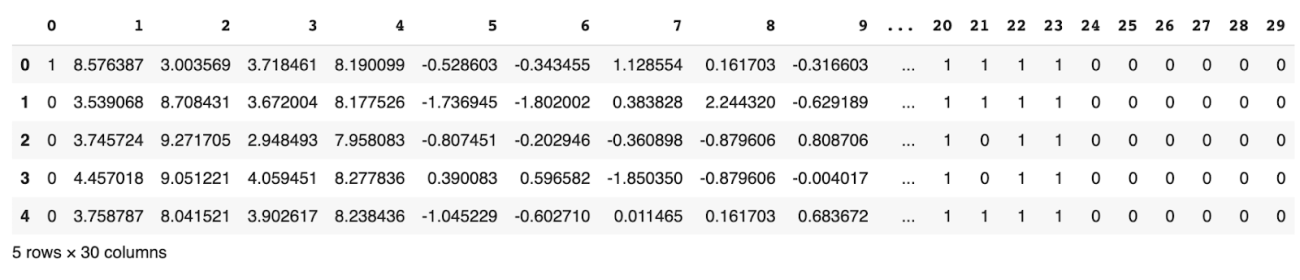
df=pd.read_csv('https://raw.githubusercontent.com/AMLab-Amsterdam/CEVAE/master/datasets/IHDP/csv/ihdp_npci_2.csv',header=None)
df.head()
Let us add some additional columns to the existing dataset and let us map 1 as True which states that the patient requires treatment, and 0 as False which states that the patient does not require the treatment.
col = ["diagnosis", "y_factual", "y_cfactual", "mu0", "mu1",] ##adding additional columns for causalty check
for i in range(1,26):
col.append("x"+str(i))
df.columns = col
df = df.astype({"diagnosis":'bool'}, copy=False)
df.head()

Now the data required for Causal Modeling is ready and now let us look into how to implement the standard steps of formulating a causal inference.
model=CausalModel(data = df,treatment='diagnosis',outcome='y_factual',common_causes=["x"+str(i) for i in range(1,26)]) model.summary()

So here we can see that we have built a model to determine the casualty factors that affect the diagnosis of the patient. Let us use the view_model() inbuilt function to determine the features that are interlinked for the causality.
model.view_model()
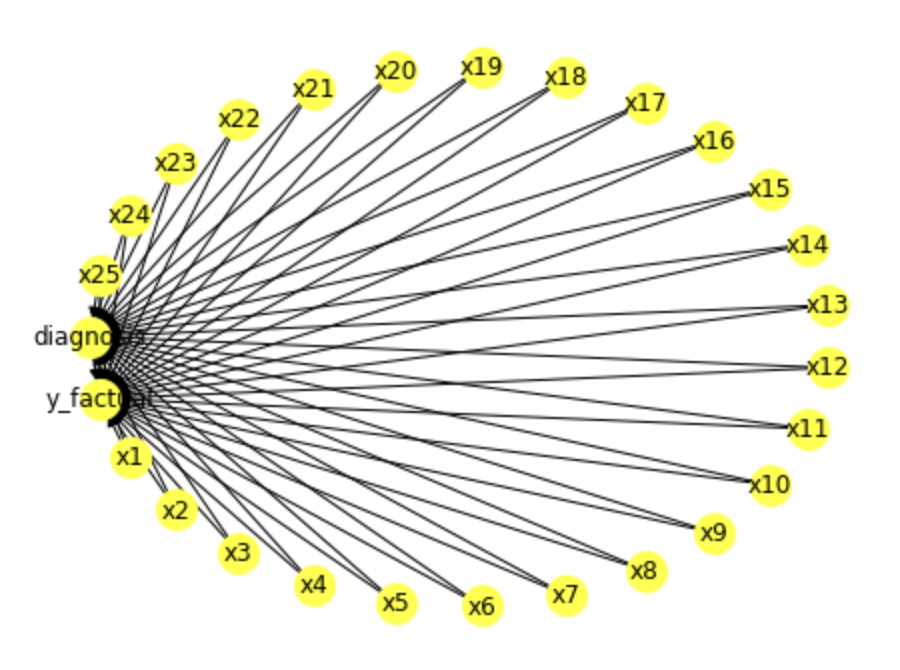
Now as causal modeling is done, the next step is to identify the parameters or the estimators that account for causality. So we will use identify_effect() inbuilt function of causal models for the identification stage.
est_ident = model.identify_effect(proceed_when_unidentifiable=True, method_name='exhaustive-search') print(est_ident)

Here we can see that some of the parameters that account for causality are being identified by the backdoor estimator by using the exhaustive search method. The exhaustive search method is used here to determine thoroughly and completely all the possible casualties.
Now as the possible causalities are being identified let us now use the standard estimation techniques of causal models to estimate the values accounting for causality.
First, let us use the Linear Regression technique to estimate the value that accounts for causality.
## Linear Regression est_lin=model.estimate_effect(est_ident,method_name='backdoor.linear_regression',test_significance=True) print(est_lin)

Now let us use another estimation technique named the Propensity matching technique which uses a quasi principle to estimate the parameters responsible for causality.
est_psm = model.estimate_effect(est_ident,method_name="backdoor.propensity_score_matching") print(est_psm)

Now let us look into another technique named Propensity Score Stratification and estimate the parameters that account for causality.
est_pss = model.estimate_effect(est_ident,method_name="backdoor.propensity_score_stratification",
method_params={'num_strata':50, 'clipping_threshold':5})
print(est_pss)

Now let us look into another technique named Propensity Score Weighting and estimate the parameters that account for causality using this technique.
est_psw = model.estimate_effect(est_ident,method_name="backdoor.propensity_score_weighting") print(est_psw)

Now as we have estimated the parameters that account for causality let us validate the estimated parameters through the standard techniques of causal models.
val_est_rcc=model.refute_estimate(est_ident,est_psw,method_name="random_common_cause") print(val_est_rcc)

The new effect must be closer to 0 but here we can see that by using the random cause technique we are obtaining a higher magnitude. So these parameters of the random cause models cannot be considered for causal modeling as it would lead to wrong predictions.
Now let us look into the next technique for estimating the parameter named Placebo treatment and validate the parameter magnitude that accounts for causality.
val_est_placebo=model.refute_estimate(est_ident,est_psw,method_name="placebo_treatment_refuter", placebo_type="permute",num_simulations=20) print(val_est_placebo)

Here we can see that the parameters validated by the Placebo treatment technique fall in the reliable range and the new effect is almost close to 0. This means that this causal model will remain robust and does not get affected by causality.
So this is how a causal problem has to be formulated using DoWhy and this is how a causal model has to be developed using the DoWhy framework.
Summary
Causal inference is very crucial for developing models in critical domains. DoWhy is one such framework that can be used for building an end-to-end causal inference model. The framework uses standard estimation techniques to correctly identify the parameters that account for causality. Models developed for critical domains have to be very robust and should not be affected by causality, and this can be easily done using the DoWhy framework where the magnitude of effects can also be measured and validated for building robust models for critical domains.






































































