

Table of contents
Introduction
Visual Recognition and Language Understanding are two of the challenging tasks in the domain of Artificial Intelligence. A great deal of vision-and-language research focuses on a small number of independent tasks of different types. Also, it supports an isolated analysis of each of the datasets involved. But the visually dependent language comprehension skills needed for these tasks to succeed overlap significantly.
12-in-1, a multi-task vision and language representation learning approach discussed in this article is a single model run on 12 different datasets. It performs four major vision-and-language tasks on its own – visual question answering, caption-based image retrieval, grounding referring expressions and multi-modal verification.
The 12-in-1 model was proposed by Jiasen Lu, Vedanuj Goswami, Marcus Rohbach, Devi Parikh and Stefan Lee – researchers from Facebook AI Research, Oregon State University and Georgia Institute of Technology in June 2020.
Traditional models
Language is an interface for visual reasoning tasks. The field of vision-and-language research combines vision and language to perform specialized tasks such as caption generation, each of which is supported by a few datasets. Conventional models used in this field employ common architectures to learn general Visio-linguistic representations and then fine-tune for specifically supported datasets. Such models are task-specific. However, the associations between language and vision are common across many such tasks. For instance, the task of learning to ground the expression “a yellow ball” requires the same concepts as answering the question “What colour is the ball?”
Overview of 12-in-1 model
12-in-1 is a multi-task model for discriminative vision-and-language tasks based on the ViLBERT (Vision and Language BERT) model. If you are unfamiliar with the BERT and the ViLBERT model, you may refer to the following links before proceeding:
- BERT research paper
- BERT GitHub repository
- ViLBERT article
- ViLBERT research paper
- ViLBERT GitHub repository
Task-Groups in 12-in-1
The 12 datasets used by the model perform cover a variety of tasks which have been grouped into 4 categories as follows:
- Vocab based VQA
- Given an image and a natural-language question, the task is to select an answer from a fixed vocabulary.
- Datasets – (i)VQAv2 (ii)GQA (iii)Visual Genome (VG) QA
- Image retrieval
- Given a caption and a pool of images, the task is to retrieve the target image that is best described by the caption.
- Datasets – (i)COCO (ii)Flickr30K
- Referring expressions
- Given a natural language expression and an image, the task is to identify the target region that is referred to by expression (can be as simple as a noun phrase or as complex as a multi-round dialog).
- Datasets – (i)RefCOCO(+/g) (ii)Visual7W (iii)GuessWhat
- Multi-modal verification
- Given one or more images and a natural language statement, the task is to judge the correctness or predict their semantic relationship.
- Datasets – (i)NLVR (ii)SNLI-VE
Base architecture of 12-in-1
The ViLBERT model forms the basis of the 12-in-1 multi-task model. ViLBERT takes as input an image I and text segment Q. The model then outputs embeddings for each input. Internally, ViLBERT uses two BERT-type models – one working on text segments and the other on image regions.
Clean V&L multi-task setup
Since many V&L (vision-and-language) tasks overlap in terms of images, a clean setup has been designed to avoid information leakage from annotations from other tasks. The test images are removed from the train/validation set for all the tasks. The test images are thus left unmodified and the size of training data gets significantly reduced.

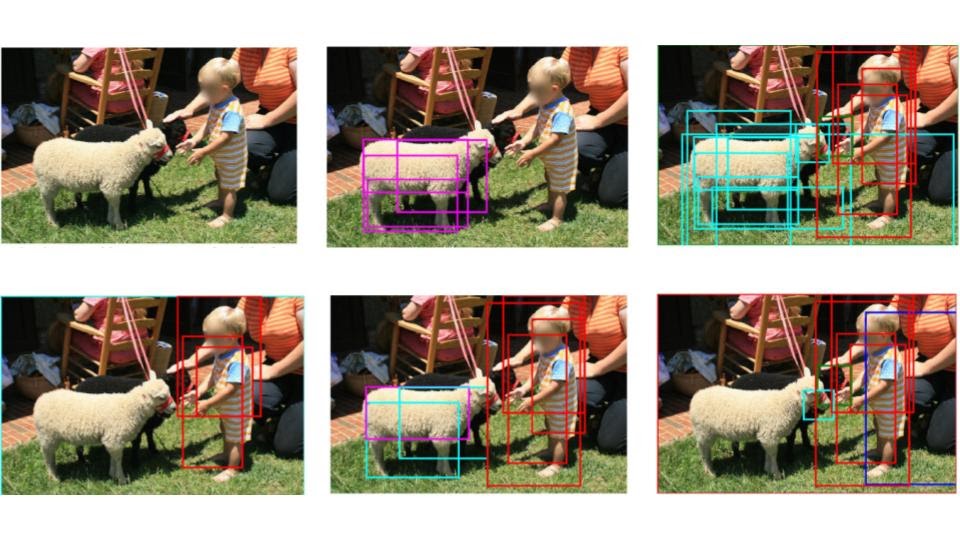
As shown in the above figure, the single 12-in-1 model performs a variety of tasks – caption and image retrieval, question answering, grounding phrases, guessing image regions based on a dialog, verifying facts about a pair of images, natural language inferences from an image, etc. It enables the exchange of information between images and text segments.
Performance comparison of 12-in-1
Compared to a set of independent state-of-the-art models each used for a specific V&L task, the improved ViLBERT model represents a reduction from ∼3 billion parameters to ∼270 million. It has also been found to have improved the average performance by 2.05 points. Multi-task training is useful even in cases of single task scenarios. Fine-tuning the multi-task model for single tasks gives better results than the baseline single-task trained models.
Practical implementation of 12-in-1
Here’s a demonstration of the multi-task model implemented using Python 3 in Google colab.
The steps to be followed for the implementation are as follows:
1) Clone the GitHub repository
!git clone 'https://github.com/facebookresearch/vilbert-multi-task'
2)Import the required libraries and classes.
import sys import os import torch import yaml #for data serialization
Here we have used easydict Python library which allows dictionary values to be used as attributes. (weblink)
from easydict import EasyDict as edict
The class PreTrainedTokenizer of PyTorch has common methods for loading/saving a tokenizer. Learn about PyTorch transformers from here.
from pytorch_transformers.tokenization_bert import BertTokenizer
The ConceptCapLoaderTrain and ConceptCapLoaderVal classes have been defined here. The former one combines a dataset and a sampler and provides single or multi-process iterators over the training dataset. The latter class does the same for the validation set.
from vilbert.datasets import ConceptCapLoaderTrain, ConceptCapLoaderVal
The configuration parameters and tasks to be done by the BERT model have been defined in the following imported classes.
from vilbert.vilbert import VILBertForVLTasks, BertConfig, BertForMultiModalPreTraining
The LoadDatasetEval class loads the dataset for evaluating the model.
from vilbert.task_utils import LoadDatasetEval import numpy as np import matplotlib.pyplot as plt import PIL (imaging library PIL to deal with the image sections)
Here, we have used Mask R-CNN model for object instance segmentation.
from maskrcnn_benchmark.config import cfg from maskrcnn_benchmark.layers import nms from maskrcnn_benchmark.modeling.detector import build_detection_model from maskrcnn_benchmark.structures.image_list import to_image_list from maskrcnn_benchmark.utils.model_serialization import load_state_dict from PIL import Image import cv2 #OpenCV library import argparse #argparse library for parsing the text segments import glob # glob library for unix-style pathname expansion from types import SimpleNamespace #types module used for dynamic type creation for built-in types import pdb #Python debugger
3)Define feature extractor
class FeatureExtractor:
MAX_SIZE = 1333
MIN_SIZE = 800
def __init__(self):
self.args = self.get_parser()
self.detection_model = self._build_detection_model()
def get_parser(self):
parser = SimpleNamespace(model_file=
'save/resnext_models/model_final.pth',
4) Set configuration path for the ResNet model.
config_file='save/resnext_models/e2e_faster_rcnn_X-152-32x8d-FPN_1x_MLP_2048_FPN_512_train.yaml', batch_size=1, num_features=100, feature_name="fc6", confidence_threshold=0, background=False, partition=0) return parser
5)Build the detection model
def _build_detection_model(self):
cfg.merge_from_file(self.args.config_file)
cfg.freeze()
#Build the model using the defined configurations
model = build_detection_model(cfg)
checkpoint = torch.load(self.args.model_file, map_location=torch.device("cpu"))
#Know about the torch.load() function here.
#Load model’s parameter dictionary using a deserialized state_dic. (load_state_dict())
load_state_dict(model, checkpoint.pop("model"))
model.to("cuda")
model.eval()
return model
6)Perform image transformation
def _image_transform(self, path):
img = Image.open(path)
im = np.array(img).astype(np.float32)
# IndexError: too many indices for array, grayscale images
if len(im.shape) < 3:
im = np.repeat(im[:, :, np.newaxis], 3, axis=2)
im = im[:, :, ::-1]
im -= np.array([102.9801, 115.9465, 122.7717])
im_shape = im.shape
im_height = im_shape[0]
im_width = im_shape[1]
im_size_min = np.min(im_shape[0:2])
im_size_max = np.max(im_shape[0:2])
# Scale based on minimum size
im_scale = self.MIN_SIZE / im_size_min
# Prevent the biggest axis from being more than max_size
# If bigger, scale it down
if np.round(im_scale * im_size_max) > self.MAX_SIZE:
im_scale = self.MAX_SIZE / im_size_max
im = cv2.resize(
im, None, None, fx=im_scale, fy=im_scale,
interpolation=cv2.INTER_LINEAR
)
img = torch.from_numpy(im).permute(2, 0, 1)
im_info = {"width": im_width, "height": im_height}
return img, im_scale, im_info
7) Define the feature extraction process.
def _process_feature_extraction( self, output, im_scales, im_infos, feature_name="fc6", conf_thresh=0 ): batch_size = len(output[0]["proposals"]) #number of bounding boxes per detected image n_boxes_per_image = [len(boxes) for boxes in output[0]["proposals"]] score_list = output[0]["scores"].split(n_boxes_per_image) score_list = [torch.nn.functional.softmax(x, -1) for x in score_list] feats = output[0][feature_name].split(n_boxes_per_image) cur_device = score_list[0].device feat_list = [] info_list = [] for i in range(batch_size): dets = output[0]["proposals"][i].bbox / im_scales[i] scores = score_list[i] max_conf = torch.zeros((scores.shape[0])).to(cur_device) conf_thresh_tensor = torch.full_like(max_conf, conf_thresh) start_index = 1 # Column 0 of the scores matrix is for the background class if self.args.background: start_index = 0 for cls_ind in range(start_index, scores.shape[1]): cls_scores = scores[:, cls_ind] keep = nms(dets, cls_scores, 0.5) max_conf[keep] = torch.where( # Better than max one till now and minimally greater than conf_thresh (cls_scores[keep] > max_conf[keep]) & (cls_scores[keep] > conf_thresh_tensor[keep]), cls_scores[keep], max_conf[keep], ) sorted_scores, sorted_indices = torch.sort(max_conf, descending=True) num_boxes = (sorted_scores[: self.args.num_features] != 0).sum() keep_boxes = sorted_indices[: self.args.num_features] feat_list.append(feats[i][keep_boxes]) bbox = output[0]["proposals"][i][keep_boxes].bbox / im_scales[i]
8)Predict the class label using the scores
#Return the indices of the maximum value of all elements in the input tensor using torch.argmax() and torch.max() objects = torch.argmax(scores[keep_boxes][start_index:], dim=1) cls_prob = torch.max(scores[keep_boxes][start_index:], dim=1) info_list.append( { "bbox": bbox.cpu().numpy(), "num_boxes": num_boxes.item(), "objects": objects.cpu().numpy(), "image_width": im_infos[i]["width"], "image_height": im_infos[i]["height"], "cls_prob": scores[keep_boxes].cpu().numpy(), } ) return feat_list, info_list
9)Get Detectron model’s features
def get_detectron_features(self, image_paths):
img_tensor, im_scales, im_infos = [], [], []
for image_path in image_paths:
im, im_scale, im_info = self._image_transform(image_path)
img_tensor.append(im)
im_scales.append(im_scale)
im_infos.append(im_info)
/* Image dimensions should be divisible by 32, to allow convolutions
in detector to work*/
current_img_list = to_image_list(img_tensor, size_divisible=32)
current_img_list = current_img_list.to("cuda")
with torch.no_grad():
output = self.detection_model(current_img_list)
feat_list = self._process_feature_extraction(
output,
im_scales,
im_infos,
self.args.feature_name,
self.args.confidence_threshold,
)
return feat_list
def _chunks(self, array, chunk_size):
for i in range(0, len(array), chunk_size):
yield array[i : i + chunk_size]
10)Save the extracted features
def _save_feature(self, file_name, feature, info):
file_base_name = os.path.basename(file_name)
file_base_name = file_base_name.split(".")[0]
info["image_id"] = file_base_name
info["features"] = feature.cpu().numpy()
file_base_name = file_base_name + ".npy"
np.save(os.path.join(self.args.output_folder, file_base_name),
info)
11) Perform tokenization and detokenization of the text segments
def tokenize_batch(batch):
return [tokenizer.convert_tokens_to_ids(sent) for sent in batch]
def untokenize_batch(batch):
return [tokenizer.convert_ids_to_tokens(sent) for sent in batch]
def detokenize(sent):
""" Roughly detokenizes (mainly undoes wordpiece) """
new_sent = []
for i, tok in enumerate(sent):
if tok.startswith("##"):
new_sent[len(new_sent) - 1] = new_sent[len(new_sent) - 1] + tok[2:]
else:
new_sent.append(tok)
return new_sent
#Print the tokenization results
def printer(sent, should_detokenize=True):
if should_detokenize:
sent = detokenize(sent)[1:-1]
print(" ".join(sent))
# write arbitrary string for a given sentence.
import _pickle as cPickle
12)Define a method to make prediction
def prediction(question, features, spatials, segment_ids, input_mask, image_mask, co_attention_mask, task_tokens, ):
vil_prediction, vil_prediction_gqa, vil_logit, vil_binary_prediction, vil_tri_prediction, vision_prediction, vision_logit, linguisic_prediction, linguisic_logit, attn_data_list = model(
question, features, spatials, segment_ids, input_mask, image_mask, co_attention_mask, task_tokens, output_all_attention_masks=True
)
height, width = img.shape[0], img.shape[1]
logits = torch.max(vil_prediction, 1)[1].data # argmax
# Load VQA label to answers:
label2ans_path = os.path.join('save', "VQA" ,"cache", "trainval_label2ans.pkl")
vqa_label2ans = cPickle.load(open(label2ans_path, "rb"))
answer = vqa_label2ans[logits[0].item()]
print("VQA: " + answer)
# Load GQA label to answers:
label2ans_path = os.path.join('save', "gqa" ,"cache", "trainval_label2ans.pkl")
logtis_gqa = torch.max(vil_prediction_gqa, 1)[1].data
gqa_label2ans = cPickle.load(open(label2ans_path, "rb"))
answer = gqa_label2ans[logtis_gqa[0].item()]
print("GQA: " + answer)
# vil_binary_prediction NLVR2, 0: False 1: True Task 12
logtis_binary = torch.max(vil_binary_prediction, 1)[1].data
print("NLVR: " + str(logtis_binary.item()))
# vil_entaliment:
label_map = {0:"contradiction", 1:"neutral", 2:"entailment"}
logtis_tri = torch.max(vil_tri_prediction, 1)[1].data
print("Entaliment: " + str(label_map[logtis_tri.item()]))
# vil_logit:
logits_vil = vil_logit[0].item()
print("ViL_logit: %f" %logits_vil)
# grounding:
logits_vision = torch.max(vision_logit, 1)[1].data
grounding_val, grounding_idx = torch.sort(vision_logit.view(-1), 0, True)
examples_per_row = 5
ncols = examples_per_row
nrows = 1
figsize = [12, ncols*20] # figure size, inches
fig, ax = plt.subplots(nrows=nrows, ncols=ncols, figsize=figsize)
# Define bounding boxes and images’ configurations for the output
for i, axi in enumerate(ax.flat):
idx = grounding_idx[i]
val = grounding_val[i]
box = spatials[0][idx][:4].tolist()
y1 = int(box[1] * height)
y2 = int(box[3] * height)
x1 = int(box[0] * width)
x2 = int(box[2] * width)
patch = img[y1:y2,x1:x2]
axi.imshow(patch)
axi.axis('off')
axi.set_title(str(i) + ": " + str(val.item()))
plt.axis('off')
plt.tight_layout(True)
plt.show()
#Make predictions for the text segments
def custom_prediction(query, task, features, infos):
tokens = tokenizer.encode(query)
tokens = tokenizer.add_special_tokens_single_sentence(tokens)
segment_ids = [0] * len(tokens)
input_mask = [1] * len(tokens)
max_length = 37
if len(tokens) < max_length:
# Note here we pad in front of the sentence
padding = [0] * (max_length - len(tokens))
tokens = tokens + padding
input_mask += padding
segment_ids += padding
text = torch.from_numpy(np.array(tokens)).cuda().unsqueeze(0)
input_mask = torch.from_numpy(np.array(input_mask)).cuda().unsqueeze(0)
segment_ids = torch.from_numpy(np.array(segment_ids)).cuda().unsqueeze(0)
task = torch.from_numpy(np.array(task)).cuda().unsqueeze(0)
num_image = len(infos)
feature_list = []
image_location_list = []
image_mask_list = []
for i in range(num_image):
image_w = infos[i]['image_width']
image_h = infos[i]['image_height']
feature = features[i]
num_boxes = feature.shape[0]
g_feat = torch.sum(feature, dim=0) / num_boxes
num_boxes = num_boxes + 1
feature = torch.cat([g_feat.view(1,-1), feature], dim=0)
boxes = infos[i]['bbox']
image_location = np.zeros((boxes.shape[0], 5), dtype=np.float32)
image_location[:,:4] = boxes
image_location[:,4] = (image_location[:,3] - image_location[:,1]) * (image_location[:,2] - image_location[:,0]) / (float(image_w) * float(image_h))
image_location[:,0] = image_location[:,0] / float(image_w)
image_location[:,1] = image_location[:,1] / float(image_h)
image_location[:,2] = image_location[:,2] / float(image_w)
image_location[:,3] = image_location[:,3] / float(image_h)
g_location = np.array([0,0,1,1,1])
image_location = np.concatenate([np.expand_dims(g_location, axis=0), image_location], axis=0)
image_mask = [1] * (int(num_boxes))
feature_list.append(feature)
image_location_list.append(torch.tensor(image_location))
image_mask_list.append(torch.tensor(image_mask))
features = torch.stack(feature_list, dim=0).float().cuda()
spatials = torch.stack(image_location_list, dim=0).float().cuda()
image_mask = torch.stack(image_mask_list, dim=0).byte().cuda()
co_attention_mask = torch.zeros((num_image, num_boxes, max_length)).cuda()
prediction(text, features, spatials, segment_ids, input_mask, image_mask, co_attention_mask, task)
13) ViLBERT part
#Instantiate the FeatureExtractor() class defined above
feature_extractor = FeatureExtractor()
#arguments for the ViLBERT model
args = SimpleNamespace(from_pretrained= "save/multitask_model/pytorch_model_9.bin",
bert_model="bert-base-uncased",
config_file="config/bert_base_6layer_6conect.json",
max_seq_length=101,
train_batch_size=1,
do_lower_case=True,
predict_feature=False,
seed=42,
num_workers=0,
baseline=False,
img_weight=1,
distributed=False,
objective=1,
visual_target=0,
dynamic_attention=False,
task_specific_tokens=True,
tasks='1',
save_name='',
in_memory=False,
batch_size=1,
local_rank=-1,
split='mteval',
clean_train_sets=True
)
#Set model configuration path
config = BertConfig.from_json_file(args.config_file)
with open('./vilbert_tasks.yml', 'r') as f:
task_cfg = edict(yaml.safe_load(f))
#V&L tasks to be performed
task_names = [
for i, task_id in enumerate(args.tasks.split('-')):
task = 'TASK' + task_id
name = task_cfg[task]['name']
task_names.append(name)
timeStamp = args.from_pretrained.split('/')[-1] + '-' + args.save_name
config = BertConfig.from_json_file(args.config_file)
default_gpu=True
if args.predict_feature:
config.v_target_size = 2048
config.predict_feature = True
else:
config.v_target_size = 1601
config.predict_feature = False
if args.task_specific_tokens:
config.task_specific_tokens = True
if args.dynamic_attention:
config.dynamic_attention = True
config.visualization = True
num_labels = 3129
if args.baseline:
model = BaseBertForVLTasks.from_pretrained(
args.from_pretrained, config=config, num_labels=num_labels, default_gpu=default_gpu
)
else:
model = VILBertForVLTasks.from_pretrained(
args.from_pretrained, config=config, num_labels=num_labels, default_gpu=default_gpu
)
14)Model evaluation
model.eval() cuda = torch.cuda.is_available() if cuda: model = model.cuda(0) tokenizer = BertTokenizer.from_pretrained( args.bert_model, do_lower_case=args.do_lower_case )
15)Test the model
image_path = 'IMAGE_PATH'
features, infos = feature_extractor.extract_features(image_path)
img = PIL.Image.open(image_path).convert('RGB')
img = torch.tensor(np.array(img))
#Plot the output using matplotlib
plt.axis('off')
plt.imshow(img)
plt.show()
query = "swimming elephant"
task = [9]
#pass the inputs to make the custom prediction
custom_prediction(query, task, features, infos)
Input image:

Output:

Source: GitHub
Find the Google colab notebook of above implementation here.
References
To have a detailed understanding about the 12-in-1 multitasking model, refer to the following sources: