



|
Listen to this story
|
Researchers from Meta recently introduced MEGABYTE, a scalable architecture for modeling long sequences. This new architecture outperforms existing byte-level models across a range of tasks and modalities, allowing large models of sequence of over 1 million tokens.
The researchers also said that it gives competitive language modeling results with subword models, which may allow byte-level models to replace tokenisation. Simply put, this new architecture allows for the simulation and modeling of long sequences of bytes without the need for tokenisation. Tokenisation is a process where sequences are divided into smaller units called tokens. However, it has limitations and can make certain tasks more challenging.
Here’s how it works
MEGABYTE consists of three components: a local module that predicts bytes within a patch, a patch embedder that encodes patches by combining byte embeddings, and a global module that uses a transformer to input and output patch representations.
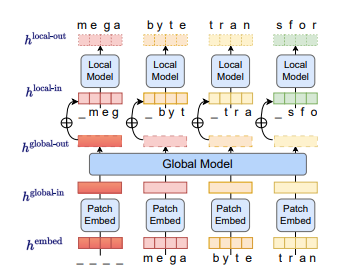
An overview of MEGABYTE (Source: arXiv)
This new architecture by Meta claims to offer several advantages over traditional transformers for handling long sequences. Firstly, it reduces the computational cost of self-attention from a quadratic to sub-quadratic form, making it more feasible to process lengthy sequences. Secondly, it allows for larger and more expressive models by using large feedforward layers per path instead of per position, thereby leading to more efficient use of computational resources.
Lastly, it enables greater parallelism during generation, resulting in faster sequence generation without hampering the performance.
Further, the researchers believe that byte-level models can achieve SOTA results in tasks such as density estimation on ImageNet, competitive performance in extended context language modeling, and audio modeling from raw audio data. In other words, these findings demonstrate the scalability and effectiveness of tokenisation-free autoregressive sequence modeling.
All in all, MEGABYTE is a novel method that enables the modeling of long sequences of bytes without the need for tokenization, offering advantages in terms of computational efficiency and performance in various tasks.
What’s Next?
The researchers believe that the scale of experiments here is far below those of state-of-the-art language models such as few shot learners, and future work should explore scaling the architecture to much larger models and datasets.






































































