



|
Listen to this story
|
Now a day, most people are familiar with AI voice assistants and use this technology in their day-to-day life. Recently at Google’s I/O 2018 event, they demonstrated a phone call conversation between the google assistant and a real person. The reason behind the realistic conversation is, of course, the intelligence but also the voice of the AI. The technology used to create a similar realistic voice is called Speed synthesis. In this article, we will be discussing one of the speech synthesis algorithms and try to learn about the architecture and working of the neural vocoder. Following are the topics to be covered.
Table of contents
- What is a Neural Vocoder?
- Where it is used
- How does it work?
- Application of Neural vocoder in speech recognition
What is a Neural Vocoder?
The artificial recreation of human speech with a computer or other technology is known as speech synthesis. Speech synthesis, the opposite of voice recognition, is usually utilized for converting text information into audio information and in applications such as voice-enabled services and mobile applications. It is also utilized in assistive technology to aid vision-impaired persons in reading written material.
A vocoder is a signal processing device that uses feature representation to synthesize the voice waveform. Classic vocoder settings are prompted by an underlying speech production model and include appropriate encodings of the fundamental frequency, spectral envelope, and other factors. Feature sequences are often created on a considerably coarser temporal scale than the target audio source. In the case of voice synthesis, the analytical technique can be replaced with a generator that generates the vocoder settings directly.
Neural vocoders are a frequent component in speech synthesis pipelines that transform the spectral representations of an audio stream into waveforms. It is primarily concerned with generating waveforms from low-dimensional representations such as Mel-Spectrograms.
There are three main categories of neural vocoders autoregressive models, GAN-based models, and diffusion models.
Autoregressive Models
The autoregressive models are distinguished by the fact that they are built as probabilistic models that forecast the likelihood of each waveform sample based on prior samples. This enables the generation of a high-quality, natural-sounding voice signal. However, the total synthesis pace is poor when compared to other approaches due to the sample-by-sample production procedure. There are two commonly used autoregressive models, WaveNet and WaveRNN.
GAN Models
GAN-based vocoders have consistently outperformed autoregressive models in terms of speed and quality of synthesised speech. They use the basic principle of GANs, employing a generator to represent the waveform signal in the time domain and a discriminator to improve the quality of the generated speech. Various GAN-based vocoder variations have been introduced. MelGAN and Parallel WaveGAN are two examples of representative models.
Diffusion Models
Diffusion probabilistic models are another generative model that includes two primary processes: diffusion and reversal. The diffusion process is described as a Markov chain process in which Gaussian noise is gradually added to the original signal until it is destroyed. In contrast, the reverse procedure is a denoising process that gradually eliminates the additional Gaussian noise and recovers the original signal. There are two commonly used diffusion-based vocoders WaveGrad and DiffWave.
Are you looking for a complete repository of Python libraries used in data science, check out here.
Where is it used?
The majority of speech-generating algorithms, such as text-to-speech and voice conversion, do not directly create waveforms. Instead, acoustic features such as Mel-spectrograms or F0 frequencies are output by the models. Waveforms can traditionally be vocoded from auditory or linguistic data using heuristic algorithms or constructed vocoders. However, the quality of the produced speech is severely constrained and degraded due to the assumptions behind the heuristic approaches.
Since Google’s Tacotron 2 used WaveNet as a vocoder to create waveforms from Mel-spectrograms, neural vocoders have steadily become the most used vocoding approach for voice synthesis. Nowadays, neural vocoders have mostly superseded previous heuristic approaches, significantly improving the quality of produced speech. WaveNet creates high-quality waveforms but requires a considerable inference time owing to its autoregressive design.
How does it work?
Two primary units in a neural vocoder are signal generation and the signal processing unit. The signal processing unit differentiates between the audio signal received as an input. The signal processing operator makes the whole model work as an auto-encoder. The model is fed control parameters (fundamental frequency) derived from a particular signal, which it must recreate by adjusting the different signal model parameters. Surprisingly, the signal parameters derived from an input signal may be changed during inference before being delivered to the front-end (signal generation). The signal generation unit has the DNN, the DNN controls the parameter of the signal generation. If the DNN controller was learnt with enough examples and the input parameter combinations remained within reasonable ranges, the DNN controller should be able to convert the input parameters into the most appropriate signal model parameters.
This signal processing and signal creation arrangement is extensively utilised for two reasons:
- It addresses a long-standing issue with high-level control of complex signal processing models.
- Training the model with fewer data may be accomplished by forcing some structure into the DNN. The fundamental challenge is to design a structure that is well fitted to the target domain without limiting the model’s expressivity.
The source-filter architecture is a strong contender for dividing a vocoder into signal processing operators and DNN modules. The addition of a filter component to a neural vocoder does not imply any restrictions on the signals that the vocoder may represent. Linear predictive coding (LPC), which can be applied to arbitrary input signals, is one of the most fundamental source-filter models.
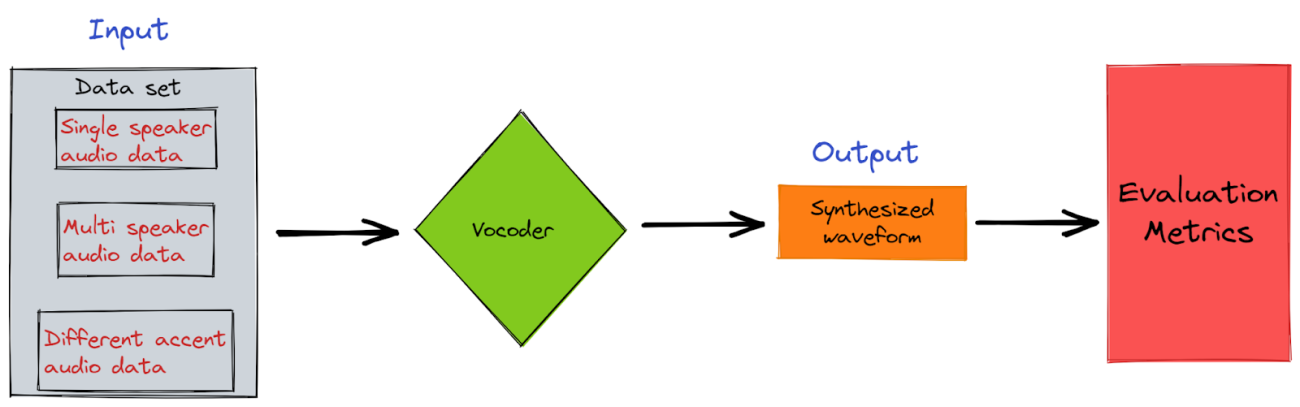
In the above pictorial representation, a typical training process of a vocoder is shown. The dataset used has different variations like a single speaker data sampled at a certain rate with different gender and age types, multi speaker with different ascents and other variations. These waveforms are provided as input for the vocoder. Inside the vocoder, the signals are processed, and filtered and as a result, a synthesized waveform is generated which is evaluated based on different metrics like Mean Opinion Score (MOS) to rate the quality of the generated speech, Log spectral distance.
Application of Neural vocoder in speech recognition
In general, speech recognition tries to enable spoken communication between humans and computers. The goal is to harmonize information from several disciplines of expertise and to acquire an appropriate interpretation of an auditory message despite potential ambiguities and inaccuracies.
The famous neural vocoder used for acoustic speech recognition is Wavenet. WaveNet is a combination of two different ideas: wavelet and Neural networks. Wavenet is an autoregressive convolutional neural network model. The wavenet processes the raw audio which is represented as a sequence of 16 bits samples. The problem with these 16 bits of raw sampled audio is the quantization value which makes it expensive to process through the softmax distribution. So the first step done by the wavenet model is to downsample or compress the audio signal to 8bit by using the μ transformation law.
As the Wavenet follows the feed-forward architecture, the raw audio is processed in the causal convolution layer and then sent ahead in the gated activation unit which acts as a filter for the amount of information to be passed to the next layer. The final output from these layers is fed to the ReLU, and at last, the signal is processed through the Softmax distribution.
Conclusion
Instead of employing standard approaches that feature audible artefacts, neural vocoders based on deep neural networks may produce human-like voices. The neural vocoder is different from the autotuner used for tuning the voices. With this article, we have understood the Neural vocoder and its application in speech recognition.
















