



|
Listen to this story
|
At NVIDIA GTC 2024, CEO Jensen Huang, while announcing their ‘very big GPU’, Blackwell, sort of bid adieu to the ‘good old days of Moore’s law’.
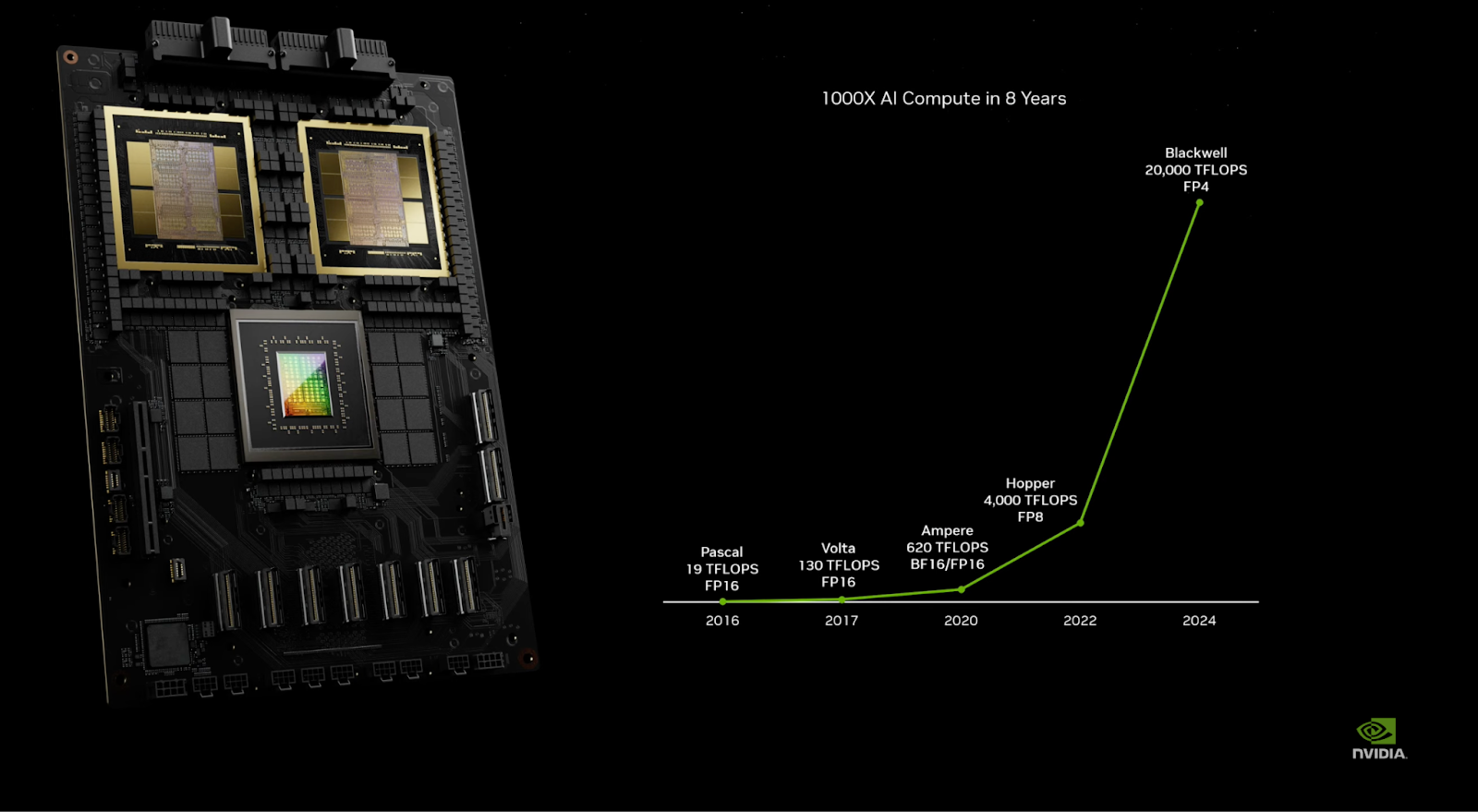
Reflecting on the rapid advancement in computing power, Huang said that in just eight years, NVIDIA has increased computational capacity by a thousandfold, a progress that far exceeds the benchmarks set during the heyday of Moore’s Law. However, he rued that even after this remarkable growth, the industry’s accelerating demands are far from being met.
“In the past eight years, we’ve increased computation by 1000 times, and we have two more years to go. So that puts it into perspective [the fact that] the rate at which we’re advancing computing is insane. And it’s still not fast enough,” said Huang.
Huang said that the future is generative, which is why we call it ‘generative AI’, marking the start of a brand new industry. He agreed that their approach to computing is fundamentally different from their competitors. “We’ve created a processor specifically for the generative era,” he said, and added, “A critical component of this is what we call ‘content token generation’, which we format as FP4.”
Further, he said that this involves a significant amount of computation – 5x the token generation and 5x the inference capability of Hopper. “That might seem sufficient, but we asked ourselves, why stop there?” pondered Huang, and said that the answer is that it is not enough.
On the contrary, Intel is still hooked on Moore’s Law.
Right after the announcement, many experts and folks from the ecosystem took to social media to declare that this was the new Moore’s law, or the era of Huang’s Law, as you may call it.
Unleashing Blackwell, the GPU Beast
NVIDIA’s latest GPU architecture is named after David Harold Blackwell, an eminent American statistician and mathematician – who has made significant contributions to various fields, including game theory, probability theory, information theory, and statistics.
NVIDIA’s Blackwell is a game-changing AI platform for trillion-parameter scale generative AI. The B200 GPU delivers 20 petaflops of power, and the GB200 offers 30x LLM inference workload performance, enabling efficiency to reach new heights.
Blackwell features a second-gen Transformer Engine to double AI model sizes with new 4-bit precision. The 5th-gen NVLink interconnect also enables up to 576 GPUs to work seamlessly on trillion-parameter models. An AI reliability engine maximises supercomputer uptime for weeks-long training runs.
The new Tensor Cores and TensorRT-LLM Compiler in the Blackwell platform significantly reduce the operating cost and energy consumption for LLM inference, by up to 25 times compared to its predecessor.
Major tech giants like Amazon, Google, Microsoft, and Tesla have already committed to adopting Blackwell.
Huang said that training a GPT model with 1.8 trillion parameters [GPT-4] typically takes three to five months using 25,000 amperes. The Hopper architecture would require around 8,000 GPUs, consume 15 megawatts of power, and take about 90 days to complete.
In contrast, Blackwell would need just 2,000 GPUs and significantly less power (only four megawatts) for the same duration. He said that NVIDIA aims to reduce computing costs and energy consumption, thereby facilitating the scaling up of computations necessary for training next-generation models.
To showcase Blackwell’s scale, NVIDIA also unveiled the DGX SuperPOD, a next-gen AI supercomputer with up to 576 Blackwell GPUs and 11.5 exaflops of AI compute. Each DGX GB200 system packs 36 Blackwell GPUs coherently linked to Arm-based Grace CPUs.
NVIDIA vs Intel vs AMD
In contrast, Intel recently launched its Ponte Vecchio GPU based on the Xe-HPC architecture under the Data Center Max GPU branding. The company is facing delays with its discrete GPU roadmap for gaming and consumer products, which could impact its future AI training capabilities.
On the other hand, AMD’s latest offering is the Instinct MI300 accelerator series based on its CDNA 3 architecture. The flagship MI300X promises up to 1.6x higher AI inference performance per chip than NVIDIA’s H100. However, for the crucial AI training workloads, the MI300X still trails the H100 in raw performance metrics like FP8 throughput.
In comparison, for AI training performance, the B200 offers up to 2.5x higher FP8 throughput per GPU over the previous Hopper generation. But its real strength lies in inference – the new FP6 numeric format effectively doubles throughput over FP16, enabling up to 30x higher performance for large language model inference compared to Hopper.
Blackwell also packs a massive memory bandwidth of 8TB/s and up to 192GB per B200 GPU.
While Intel and AMD are making progress, NVIDIA’s Blackwell platform raises the bar significantly through architectural innovations tailored to the unique demands of trillion-parameter AI models.
Given that Moore’s law has been declared officially dead, it would be interesting to see how this space evolves in the coming months. “GPU prices will drop once AMD becomes usable,” said Abacus.AI chief Bindu Reddy, sharing interesting predictions on compute for the next five years.














































































