



|
Listen to this story
|
Google Research recently released a paper on Patchscopes- which is a framework that looks to consolidate a range of past techniques for interpreting the internal mechanisms of large language models. It is designed to understand the behaviour and alignment of LLMs with human values.
Authored by Google researchers Asma Ghandeharioun, Avi Caciularu, Adam Pearce, Lucas Dixon, and Mor Geva, Patchscopes utilises the inherent language skills of LLMs to offer intuitive, natural language explanations of their concealed internal representations. It even offers explanations of their internal workings, addressing key questions about their operations and overcoming limitations of previous interpretability methods.
An Understanding of Hallucinations?
Though the initial focus of the application of Patchscopes is limited to the natural language domain and the autoregressive Transformer model, the potential applications are broader.
The researchers believe that Patchscopes can be potentially used for detecting and correcting model hallucinations, exploring multimodal representations (including image and text), and investigating how models formulate predictions in intricate scenarios.
Patchscopes configuration can be explained in four steps : The Setup, The Target, The Patch and The Reveal. A standard prompt is presented to the model, followed by a secondary prompt designed to extract specific hidden information. Inference is performed on the source prompt, injecting the hidden representation into the target prompt, and the model processes the augmented input, revealing insights into its comprehension of the context.
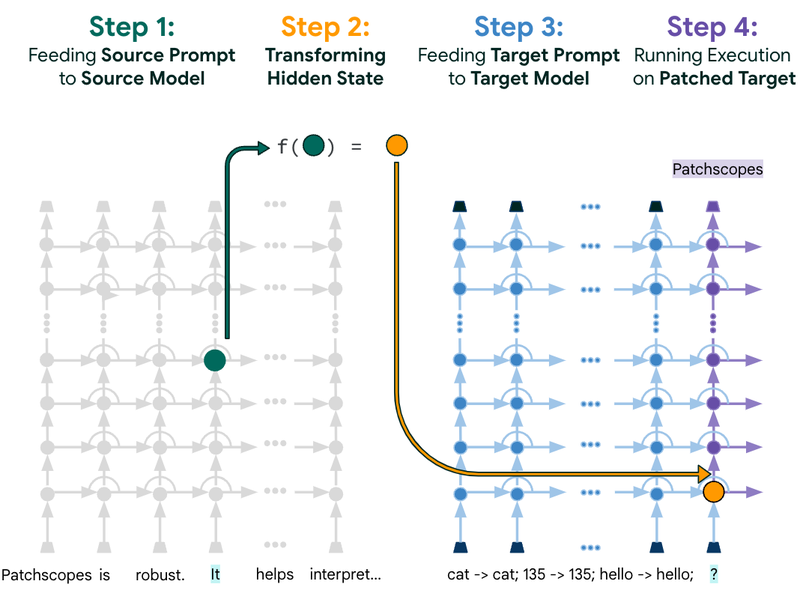
Patchscopes Illustration. Source: Google Research Blog
The paper only touches upon the surface of the opportunities this framework creates and further studies need to be done to understand its applicability across domains.














































































