



The size of the world wide web is growing rapidly and at the same time, the number of queries that are handled has also grown incredibly. With the increasing number of users on the web, the number of queries submitted to the search engines is also growing exponentially. Therefore, search engines must be able to process these queries efficiently. Thus, the web mining techniques are applied in order to extract only relevant documents from the database and provide intended information to the users.
The goal of information retrieval is to find the documents that are relevant for a user query in a collection of documents. Decades of research in information retrieval were successful in developing and refining techniques that are solely word-based.
The collections of documents that are connected by hyperlinks have existed. A web page has a hyperlink which is a reference to a web page that is contained in. On a web browser, when the hyperlink is clicked, the browser displays a page. A link from one page to another page is a recommendation of the page by the author of the page. If one page and the other page are connected by a link, the probability of having them on the same topic is higher than they are not connected.
Hyperlinks in a document provide a valuable source of information for information retrieval. Link analysis has been successful in deciding which pages are important. It is also been used for categorizing webpages, finding pages related to given pages and to find duplicated websites.
Link analysis makes the following assumptions –
- A link from page A to page B is a recommendation of page A to the author of page B.
- If page A and page B are connected by a link the probability that they are on the same topic is higher than if they are not connected.

Link analysis has been used successfully for deciding which web pages to add to the collection of documents, here web crawling plays an important role. The documents which are collected together are known as the web crawler. The link analysis algorithm is based on the links structure of the documents. The quality of results from search engines is generally lower than what the user expects and this quality can be improved greatly if pages are ranked according to some criteria based on links between the pages.
During the years 1997-98, two algorithms exploited the hyperlinks of the web to rank the pages, they are Page Rank and HITS. Both these algorithms utilize the hyperlinks of the web to rank the pages. At the same time, Sergey Bin and Larry Page devised a Page Rank algorithm. The Page Rank of each page depends on the Page Rank of the pages pointing to it. PageRank is a probability distribution used to represent the likelihood that a person randomly clicking on links will arrive at any particular page. PageRank can be calculated for collections of documents of any size. A probability is expressed as a numeric value between 0 and 1.
Another two methods to find a ranking of web graphs are Kleinberg’s HITS (Hyperlink Induced Topic Search) algorithm (for smaller web graphs) and the SALSA (Stochastic Approach for Link-Structure Analysis) algorithm due to Lempel and Moran(2000). HITS was developed little after page rank. SALSA is a combination of both algorithms. These two algorithms are evaluated on a very large web graph induced by 463 million crawled web pages, a set of 28,043 queries and 485,656 results labeled by human judges.
Page Rank Algorithm
Links from a page to itself, or multiple outbound links from one single page to another single page, are ignored. The PageRank theory holds the idea that an imaginary surfer who is randomly clicking on any links will eventually stop clicking at some point in time.
The probability, at any step, that the person will continue with a damping factor d. Various studies have tested different damping factors. It is generally assumed that the damping factor will be set around 0.85.
The formula for calculating the Page Rank of any page, A is –
Next iteration = Previous Iteration/Number of outgoing links.
PR (node)=(1-d)+d*(PR(Ti)/C(Ti)…+PR(Tn)/C(Tn))
One has to refer to firstly incoming links and then outgoing links of the specific node. Ti is from where incoming links are shown onto node and C is the count of how many outgoing links are seen from Ti.
Assuming there is a web graph given as below –

d is a damping factor; its value is 0.85.
PR(A) = (1-d)+d*(PR(B)/1)
PR(B) = (1-d)+d*(PR(A)/1)
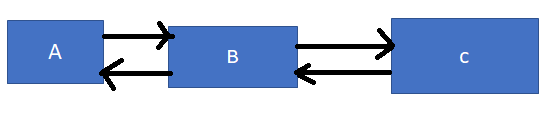
PR(A) = (1-d)+d*(PR(B)/2)
B has an incoming link onto A and B’s 2 outgoing links are onto C and onto A respectively.
PR(B) = (1-d)+d*(PR(A)/1)+(PR(C)/1))
B and C have incoming links and even they have each one outgoing link
PR(C) = (1-d)+d*(PR(B)/1)
Finally, while solving the PageRank calculations, the values at each iteration have not been rounded at all. One can go through the number of iterations until one gets constant value.
Google Panda Algorithm
Google Panda algorithm is one of Google’s ranking algorithms which was launched in February 2011. It appears on the sites to measure their quality and adjust their rankings. Google Panda Algorithm first launched on February 23, 2011. The goal of Google Panda algorithm is to reward attractive websites. The other very important goal is to reduce the presence of inappropriate sites in search results.
Goals of Google Panda algorithm –
- Very low content – web pages that have very little relevant pages or irrelevant pages or very small in terms of text.
- Duplicate content – copied contents are available in many places on the internet.
- Poor content – webpages that may contain very little information about the concerned subject.
- Lack of authorship and credibility.
- Content not relevant to the search term.
According to Google, Panda’s initial launch in the first few months affected 12 percent of search results in English.
Another difference between the searches in these web sites is not the underlying algorithm, but rather the data they use and search.
Finally, we can say that web mining is used to extract useful information from a very large amount of web data. The usual search engines show the result in a large number of pages in response to user’s queries. The ranking algorithm which is an application of web mining, play a major role in making user search navigation easier. Weighted Page Rank (WPR) algorithm is an extension of the standard Page Rank algorithm of Google. The PageRank and Weighted PageRank algorithm give importance to links more rather than the content of the pages, whereas the HITS algorithm stresses on both, the content of the web pages as well as links. Depending upon the techniques used, the ranking algorithms give a different order to the resultant pages. The PageRank and Weighted Page Rank return the important pages on the top of the result list while others return the relevant ones on the top.
References –
- Duhan, Neelam, A. K. Sharma, and Komal Kumar Bhatia. “Page ranking algorithms: a survey.” 2009 IEEE International Advance Computing Conference. IEEE, 2009.
- Manning, Christopher D., Prabhakar Raghavan, and Hinrich Schütze. Introduction to information retrieval. Cambridge university press, 2008.
This article is presented by AIM Expert Network (AEN), an invite-only thought leadership platform for tech experts. Check your eligibility.







































































