


 Most corporations wake up and find themselves in spreadsheet Hell. They have huge amounts of data on spreadsheets and none of it is believable. There is a path out of spreadsheet Hell. The path takes selected spreadsheets and turns the selected spreadsheets into corporate data. Once spreadsheets data has been submitted to corporate data, the data becomes disciplined and believable.
Most corporations wake up and find themselves in spreadsheet Hell. They have huge amounts of data on spreadsheets and none of it is believable. There is a path out of spreadsheet Hell. The path takes selected spreadsheets and turns the selected spreadsheets into corporate data. Once spreadsheets data has been submitted to corporate data, the data becomes disciplined and believable.
There already is a lot of data that has been put into corporate data coming from sources other than spreadsheet data.
Fig 1 shows the different paths to corporate data.

Getting spreadsheet data into the form of corporate data addresses the problem of the unbelievability of data in spreadsheet Hell. But there are some important and fundamental differences in the data coming from spreadsheets and the data coming from other sources as the data is transformed into corporate data. Those differences are shown in Fig 2 –
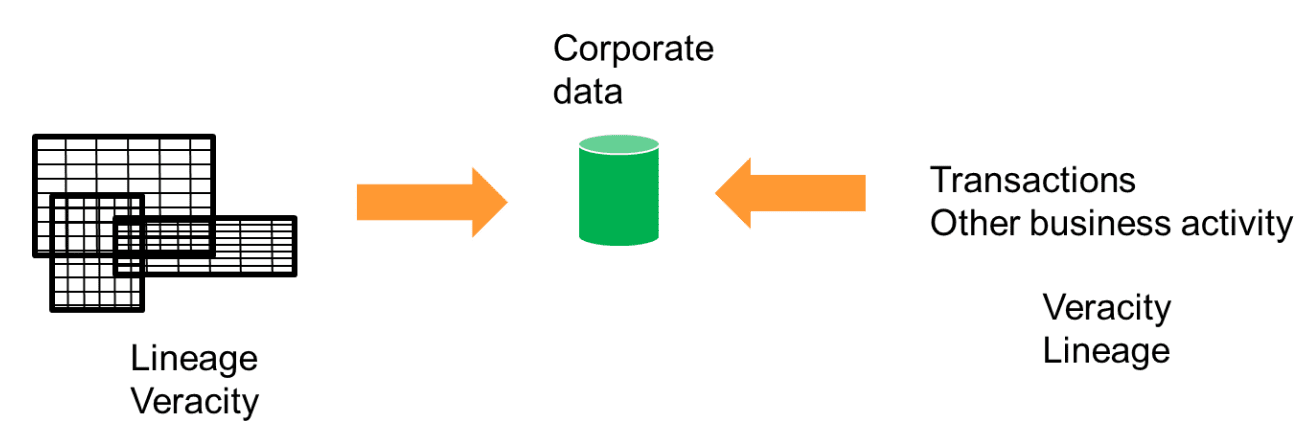
Data whose source is not a spreadsheet has as a priority as it lands in corporate data veracity and then lineage. Data whose source is a spreadsheet has as its priority as it lands in corporate data lineage and then veracity. This subtle difference between the two types of data has some very real and some very serious implications.
In order to understand what is being said here it is necessary to take a look at how spreadsheet data gets into corporate data and how transaction and other business data gets into corporate data. Consider the following flow of data for spreadsheet data, as seen in Fig 3.
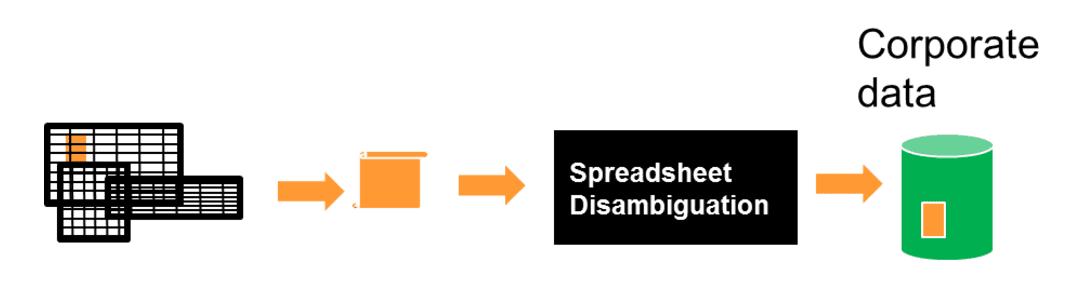
Data coming from a spreadsheet begins its journey on a spreadsheet, naturally. Once the spreadsheet has been vetted and selected as input for corporate data, the spreadsheet is submitted for corporate data processing. The spreadsheet goes through a “log in” process. From the “log in” process the spreadsheet passes through spreadsheet disambiguation. From there the spreadsheet is entered into corporate data. This is the journey of the spreadsheet data into corporate data.
The moment of veracity for spreadsheet data is simple. It is the moment when the end user enters the data into the spreadsheet. Either the end user enters the data correctly or he doesn’t.
Now consider the path that transaction and other business data takes in order to get into corporate data. Fig 4 depicts this path.

In this path, first some business activity occurs that is notable to the corporation. This business activity could be a purchase, a change of address, a phone call, or any one of many activities. The business transaction is captured electronically and is entered into a system. Once the transaction is entered into a system, the data passes through many intermediary systems. There may be ETL processing. The data may have been captured in Australian dollars and the final reporting system is in US dollars. The data may have been captured in an application then sent to SAP. There are many movements of data that could have occurred to the data. Finally, the data arrives in the corporate data store.
This is the typical path that business transaction data takes to arrive in the form of corporate data.
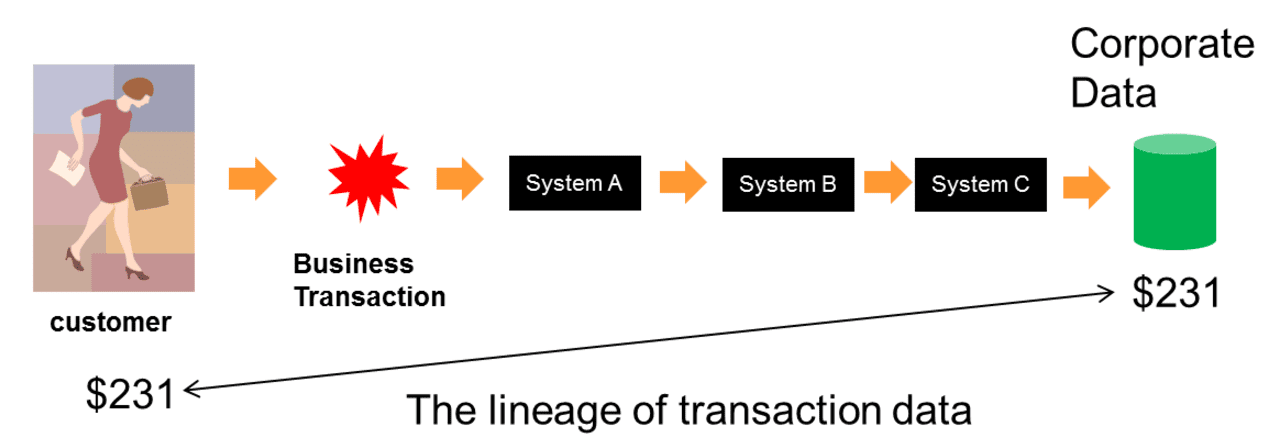
The moment of veracity arrives when the data in the corporate database is compared to the data as it was originally transacted, as seen in Fig 5 –

The moment of veracity for spreadsheet data then is quite different than the moment of veracity for business transaction data. The moment of veracity merely asks the question – did the data arrive in the corporate data store exactly as it was entered into the spreadsheet or electronic system.
The lineage of spreadsheet data refers to the many steps in the path that there are from the spreadsheet to the corporate database. Fig 6 shows the lineage of spreadsheet data.

The lineage of business transaction data refers to the path that business transaction data takes in order to get to corporate data, as seen in Fig 7 –
There is a difference then in the data that arrives in the corporate database, depending on whether the data is sourced from spreadsheets or whether the data is sourced from business transactions. Fig 8 shows these differences –

With business transaction data the emphasis is on – is the data correct as it arrives in the corporate data environment. But with spreadsheet data the emphasis is on – can we find the source of the data – the spreadsheet – accurately and easily. The reason why veracity of data for spreadsheet data is not the most important thing is that ultimately the spreadsheet data was placed there some person, and if the person who placed it there got it wrong, then it is up to the person who placed it there to make the correction. But in order to hold the person who placed it there accountable, there must be an easy and accurate way to find that person.
Bill Inmon – the “father of data warehouse” – has written 57 books published in nine languages. Bill was named by ComputerWorld as one of the ten most influential people in the history of the computer profession. Bill lives in Castle Rock, Colorado.
Bill’s latest book is TURNING TEXT INTO GOLD, Technics Publications, a book that shows how text can be turned into business value. TURNING TEXT INTO GOLD is available on Amazon.com.







































































