



|
Listen to this story
|
Sepp Hochreiter, the inventor of LSTM, has unveiled a new LLM architecture, featuring a significant innovation: xLSTM which stands for Extended Long Short-Term Memory. The new architecture addresses a major weakness of previous LSTM designs, which were sequential in nature and unable to process all information at once.
Register for Rakuten Product Conference 2024 >
The weaknesses of LSTMs, compared to Transformers, include the inability to revise storage decisions, limited storage capacities, and the lack of parallelizability due to memory mixing. Unlike LSTMs, Transformers parallelise operations across tokens, significantly improving efficiency.
The main components of the new architecture include a matrix memory for LSTM, eliminating memory mixing, and exponential gating. These modifications allow the LSTM to revise its memory more effectively when processing new data.
The xLSTM architecture boasts O(N) time complexity and O(1) memory complexity as the sequence length increases, making it much more efficient than Transformers, which have quadratic time and memory complexity (O(N^2)).
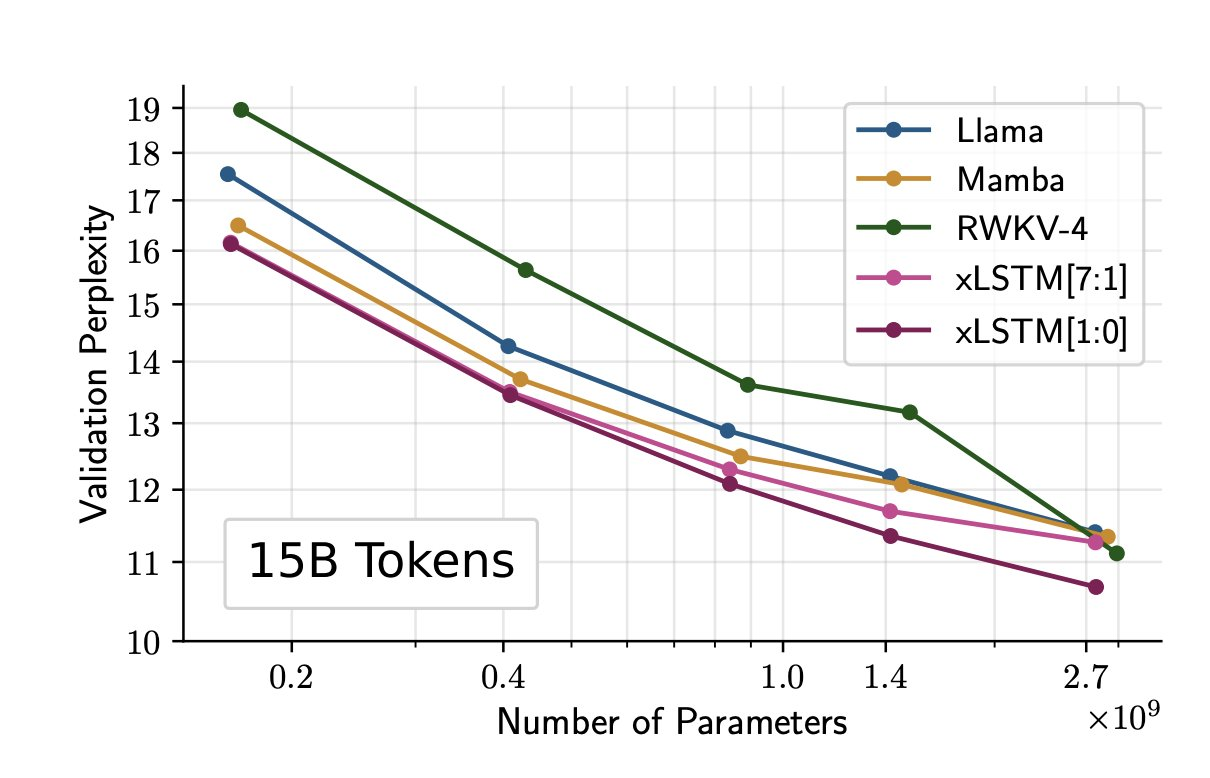
In evaluations comparing Transformer LLM, RWKV, and xLSTM trained on 15 billion tokens of text, the xLSTM[1:0] (1 mLSTM, 0 sLSTM blocks) performed the best. Moreover, xLSTM architecture follows scaling laws similar to traditional Transformer LLMs.
One of the most important aspects of the xLSTM architecture is its flexible ratio of MLSTM and SLSTM blocks. MLSTM, which stands for matrix memory parallelizable LSTMs, can operate over all tokens at once, similar to Transformers. On the other hand, SLSTM, while not parallelizable, enhances state tracking ability but slows down training and inference.
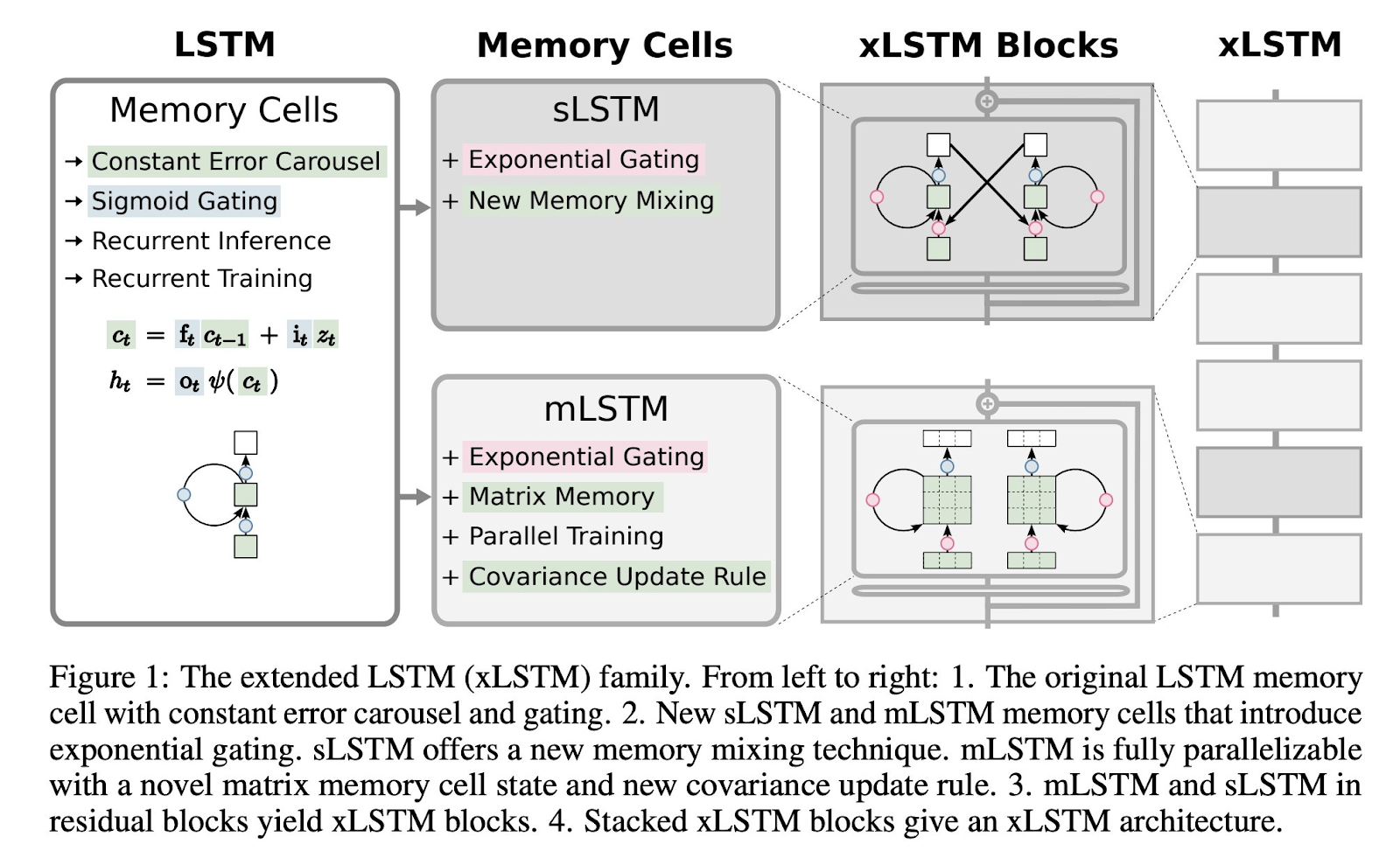
The xLSTM architecture builds upon the traditional LSTM by introducing exponential gating with memory mixing and a new memory structure. It performs favorably in language modeling compared to state-of-the-art methods such as Transformers and State Space Models.
The scaling laws suggest that larger xLSTM models will be significant competitors to current Large Language Models built with Transformer technology. Additionally, xLSTM has the potential to impact various other deep learning fields including Reinforcement Learning, Time Series Prediction, and the modelling of physical systems.




































