



|
Listen to this story
|
TorchRec is one of the libraries of Pytorch that is used to build sparse and large-scale recommendation systems. The library supports sharding which means that large tables can be sharded across GPUs and be trained. So the problems associated with higher dimensional entity tables and exceeding GPUs memory capability can be overcome by using TorchRec Sharding. So using TorchRec Sharding, distributed training of the model across accelerator-based platforms can be achieved. In this article, let us understand about TorchRec sharding with respect to this context.
Table of Contents
- Introduction to TorchRec Sharding
- Benefits of TorchRec Sharding
- Various schemes of TorchRec Sharding
- Summary
Introduction to TorchRec Sharding
TorchRec Sharding is one of the libraries of Pytorch structured to overcome the problems associated with large-scale recommendation systems. Some of the large-scale recommendation systems may require the representation of higher dimension embeddings. These embeddings may sometimes encounter maximum GPU memory usage.
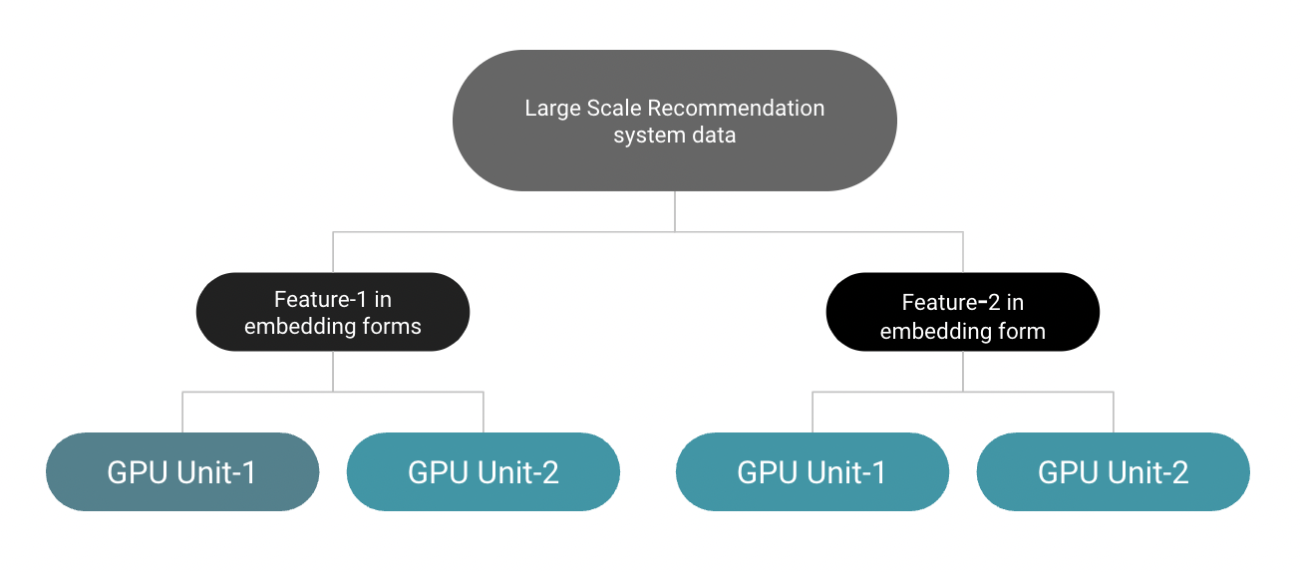
So to prevent the problems associated with higher dimensional embeddings and GPU memory constraints, PyTorch has structured a single shot library, especially for large-scale recommendation systems, where the recommendation systems can be built by sharing the training process of the recommendation model across GPUs. Different embeddings of large-scale recommendation systems of Pytorch are represented by using the inbuilt function of Pytorch named torch.nn.EmbeddingBag.
Are you looking for a complete repository of Python libraries used in data science, check out here.
An embedding Bag is basically a collection of various embeddings of the data. So this collection of Embeddings is used to configure required entities suitable for recommendation systems. So the required data entities will be sharded across different GPUs with a block size of 64 and an Embedding dimension of 4096. This benefits the required entities to be trained faster and prevents the maximum memory consumption of accelerators like GPUs.
Understanding the Sharding API
TorchRec library supports sharing higher dimensional data across accelerators and trains large-scale recommendation systems. So for distributing data across multiple accelerators and to facilitate parallel training TorchRec has formulated an API named DistributedModelParallel. The API is responsible for carrying out two functionalities. They are as follows.
i) Decision-making on how to shard the model across accelerators. The API will collect all the available sharders and come up with an optimal way to shard the embedded tables across platforms.
ii) The API will also be responsible for allocating memory across accelerator platforms and will be responsible for allocating relational tables across platforms.
Benefits of TorchRec Sharding
The benefits of TorchRec sharding are listed below.
- Modeling higher dimensional embedding tables on various accelerator-based platforms like GPUs accelerates the training process of required entities of recommendation systems.
- Optimized kernels for large-scale recommendation systems with the ability to perform sparse and quantized operations.
- Various sharders help in partitioning various tables for recommendation systems with various strategies like row-wise and column-wise sharding.
- Sharing embedding tables across distributed platforms helps in speeding up the training process of larger embedding tables.
- Regulates pipeline training through an inbuilt function named TrainPipelineSparseDist which helps to increase the performance and enable parallel processing of data across accelerator platforms.
An overview of various schemes of TorchRec Sharding
TorchRec sharding basically uses two schemes for embedding tables across platforms. The two schemes that TorchRec uses are known as EmbeddingPlanner and DistributedModelParallel. So let us try to understand the benefits of this scheme that is used by TorchRec Sharding for handling large-scale recommendation systems.
Embedding Planner
The Embedding Planner scheme of TorchRec sharding makes use of a collection of embeddings available in the EmbeddingBagCollection. In this scheme, there are two tables majorly being used known as large and small tables which are differentiated based upon the difference in the row sizes.
Some of the parameters of the table are configured to help in wise decision-making for sharding across various accelerator platforms. This scheme makes use of various sharding techniques to communicate among the various embedded tables and facilitate sharding accordingly.
DistributedModelParallel
The Distributed Model Parallel scheme operates on the principle of SPMD. SPMD abbreviates for Single Program and Multiple Data. The scheme uses some standard code to shard the model collectively among various processes and shards the tables on multiple accelerators like GPUs based upon standard specifications. This also supports multiprocessing and table-wise sharding for some of the important features of recommendation systems.
The two schemes of sharding ultimately prioritize handling larger dimension tables and distribute larger dimensions to various parallel processing accelerator platforms to accelerate the training process.
Summary
TorchRec sharding is one of the libraries of Pytorch formulated to model large-scale recommendation systems and train them on multiple GPUs to evacuate the problems associated with an overload of memory consumption of accelerator-based platforms. It facilitates training on multiple devices by splitting huge recommendation system embeddings. This enables the recommendation system to be trained faster. This library is still in the research phase, and more improvements can be expected in the future, making modeling large-scale recommendation systems easier.






































































