



|
Listen to this story
|
Highly accurate machine learning models can be heavy, requiring a lot of computational power and thus reducing inference time. Speeding up the inference time of these models by compressing them into smaller models is a widely practised technique. By making the parameters smaller or fewer, based on the technique, the models can be made to use less RAM. This can also simplify the model, reducing the latency compared to the original model, thus increasing the inference speed.
There are four heavily researched techniques popular for compressing machine learning models –
- Quantisation
- Pruning
- Knowledge distillation
- Low-rank tensor decomposition
Quantisation
One of the most widely used methods for compressing models, quantisation, involves decreasing the size of the weights to improve efficiency. The smaller representations of the model weights by reducing them into smaller sizes reduces the size of the model along with increasing the speed of its processing and inference.

Simply put, the technique involves mapping values from the larger set into a smaller set, which results in the output consisting of a smaller range of values than the input set, ideally losing as little information as possible. For example, reducing images from 32-bit into 8-bit might result in the loss of information, but can achieve the goal of reducing the size of the machine learning model, thus increasing efficiency.
The goal of this technique is to reduce the size and precision of the network without reducing the noticeable difference in efficacy.
You can read more about quantisation techniques for neural networks here.
Pruning
Unlike quantisation that reduces the weights of the weights, pruning involves reducing the number of weights, by removing connection between channels, filters, and neurons. Pruning was introduced because oftentimes networks can be over-parameterised resulting in multiple nodes encoding the same information.
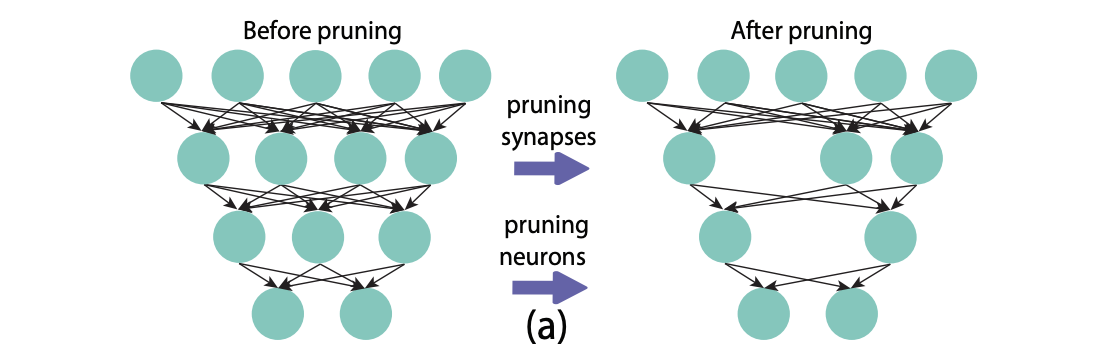
In simple words, the process is about removing nodes to decrease the number of parameters. Depending on the task, there are two classification of pruning –
Unstructured pruning is about removing individual neurons or weights. This process removes neurons and connections with zeros in the weights matrix, increasing the network’s sparsity, which is the ratio of zero to non-zero weights.
Structured pruning involves removing complete filters and channels. Since it is about removing blocks of weights in the matrices, it does not occur in matrices with sparse connectivity patterns problems.
Read more about pruning here.
Knowledge Distillation
Researchers from Cornell University figured out that the training model is usually larger than the inference model since they are trained without restriction on computational resources. The whole purpose of a trained model is to extract information and structure from the dataset as much as possible. But inference models face latency and resource consumption because they have to be deployed for results, therefore ways to compress them is a requirement.

The researchers proposed that all the information gathered by the large training model can be transferred to a smaller model by training it to copy or mimic the larger model, which was later named as distillation.
How this technique works is that the trained model is called the “teacher” and the smaller model is called the “student”. The student is taught to minimise the loss function by training on ground truths and labelled truths in the network by the teacher, based on the distribution of class probabilities and the softmax function.
Click here to check out a research paper about knowledge distillation.
Low-rank tensor decomposition
Over-parameterisation is one of the well-known issues in deep neural networks. A lot of repetitive, similar, and redundant outcomes can occur between different layers while training, especially in convolution neural networks for computer vision tasks. This technique involves reducing the number of repetitive images by approximating the numerous layers, thus reducing the memory footprint of the network, resulting in highly efficient systems.

Also known as low-rank factorisation, this technique demonstrates itself as an effective means to achieve significant size and reduce latency by compression size of the parameters. The biggest advantage of using this technique for compression is that it does not require specialised hardware since it concerns only about reducing the parameter count.
Click here to read more about low-rank factorisation.






































































