


In machine learning, Convolutional Neural Networks (CNN or ConvNet) are complex feed forward neural networks. CNNs are used for image classification and recognition because of its high accuracy. It was proposed by computer scientist Yann LeCun in the late 90s, when he was inspired from the human visual perception of recognizing things. The CNN follows a hierarchical model which works on building a network, like a funnel, and finally gives out a fully-connected layer where all the neurons are connected to each other and the output is processed.

We will construct a new ConvNet step-by-step in this article to explain it further. In this example, we will be implementing the (Modified National Institute of Standards and Technology) MNIST data set for image classification. This data set contains ten digits from 0 to 9. It has 55,000 images — the test set has 10,000 images and the validation set has 5,000 images. We will be building a ConvNet made of two hidden layers or convolutional layers. Now let us look at one of the images and the dimensions of the images. Here is an image, which is the number 7.

This image’s dimensions are 28×28 which are represented in a form of a matrix (28, 28). And the depth or the number of channels this image has is 1, since it is a grayscale image. If it was a colour (for example, RGB) image, the number of channels would have be three.
Now, the first step is to define all the functions which we are going to use in building the model. TensorFlow is a beautiful computational graph which helps build these functions and the variables by just giving them the shape or size and not storing data in them. It’s like drawing a blueprint of a bridge before you start placing the bricks.
Once we have an input image (28×28), a filter is run along all the pixels (rows, columns) of the image which captures the data like in the picture below. This is passed on to the pooling layer where it performs a mathematical computation and gives out a specific result.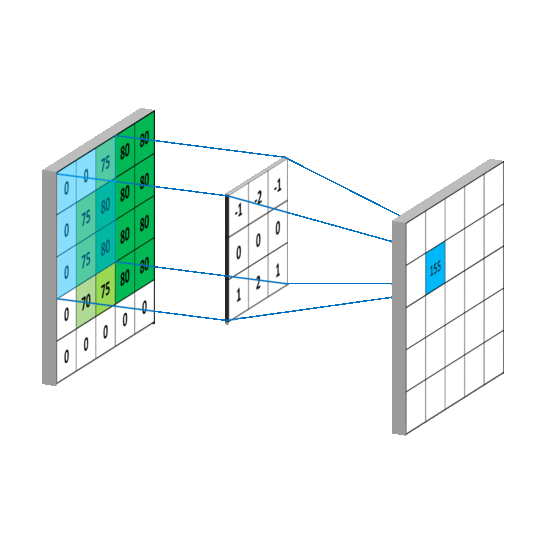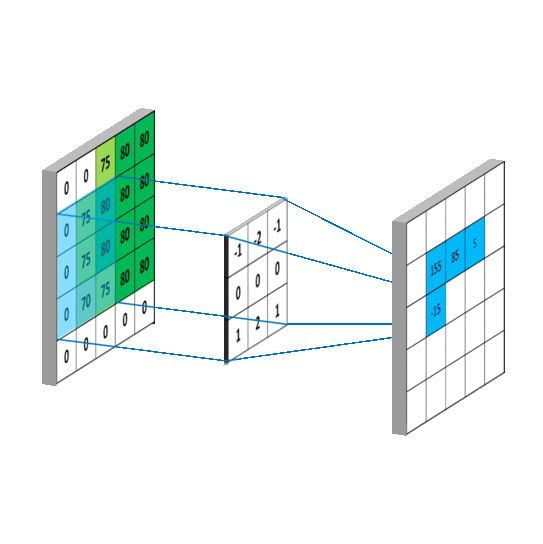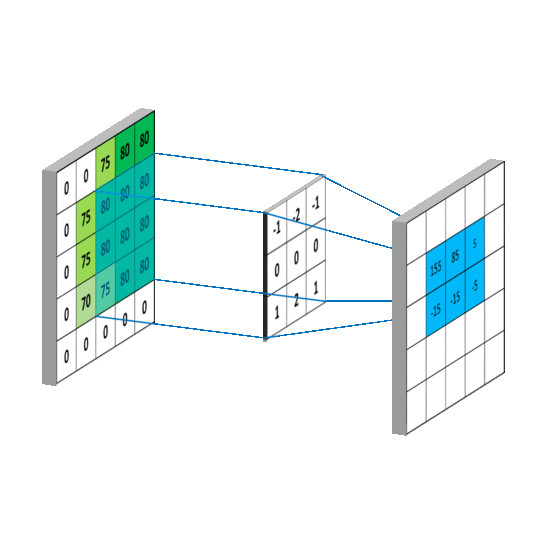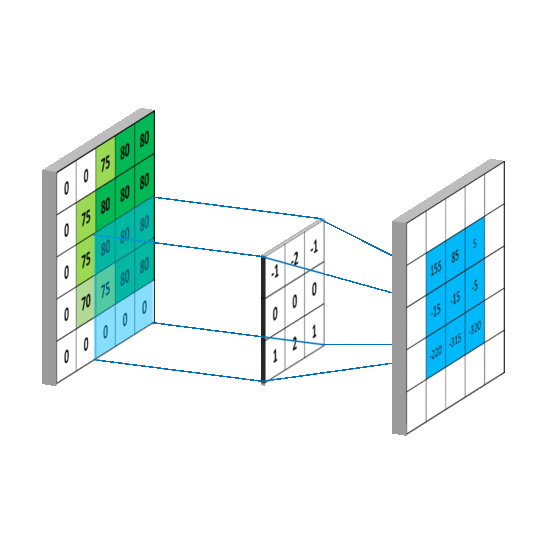
Here, a filter is a weight matrix of shape nxn (3×3) in the figure above. The weight is initialised as random numbers with some standard deviation to form normally distributed values. This filter is run across all the values in the matrix and a dot product of the weights and the pixels is calculated.
Let us define a function for our weights and biases. Tensorflow provides functions like the ‘variable’ which helps to store it as an object and you can go through different predefined commands in this page.

Now let us build a function which gives out a convolutional layer. Here, we need to consider some parameters before we build it. First would be the weight matrix or the size of the filter which is going to slide over all the values of the matrix. Let us consider the filter size to be 5×5 and a stride of 2. Stride is the number of pixels you jump or slide over in every iteration. Then we have the number of channels, which is the depth of the image. Since the images are in grayscale the depth is 1. After we have this we pass this layer into the Rectified Linear Unit (ReLU) activation function.
In Python with the TensorFlow library the build is as follows, but we need to initialize the shape and length of our variables here — which are the weights and the biases.

And the image size and shape of the inputs.

Lets look at a few example images with their true class specified.

A TensorFlow input should be a four-dimensional vector. For example, [A, B, C, D]. Here, A is the number of samples to be considered in each iteration (the number of images, in this case). B and C are the shape of the images or the dimensional description of the image (B(28), C(28)). And D is the number of channels of the input image, 1 in this case, because the image is in grayscale. Now let us build a function for the convolutional layer.

In the above code, ‘dimensions’ are nothing but the shape of the weight matrix. We have assigned the padding = ‘SAME’, which means that the filtered image after the dot product of the weights will have the same dimensions as the input image. Here, a detailed explanation about padding is given by noted Chinese-American computer scientist Andrew Ng.
After we have the convoluted layers, we need to flat them into an array. For this, we take the shape of the image — the 2nd and the 3rd element in our convoluted layer as well as the 4th element which is the number of filters. Multiplying all these we get the shape of the flattened output which is 1,568.
Let us dig into to mathematics to find a suitable padding and the output dimensions for a convolutional layer.
In this data set, all the images are 28 x 28. When we pass one of these images into our first convolutional layer we will obtain 16 number of channels with the dimensions reduced from 28×28 to 14×14. This is done with the help of padding. When we add 2 layers of 0s on the outer layers of the image and pass it through a pooling layer, the output size is exactly reduced to half of the input.
Once we have convolved two of these layers we get an output of 7x7x32. This is passed into a softmax function to find the probabilities and assign the classes. The optimiser we have used here is an AdamOptimizer, which helps with reducing the cost calculated by cross entropy. The training image accuracy with 2 hidden layers, filter size of 5, padding 2, output channels of first and second layer as 16 and 32 repressively, with ReLU and softmax (cross entropy cost) is as follows:

We can change the parameters and build the network with high number of iterations and higher number of layers to yield better results. This will depend on the computational power of your system.















































































