



|
Listen to this story
|
Apple has open sourced OpenELM, a collection of Efficient Language Models (ELMs). OpenELM utilises a layer-wise scaling approach to efficiently distribute parameters within each layer of the transformer model, resulting in improved accuracy.

Click here to check out the model on Hugging Face.
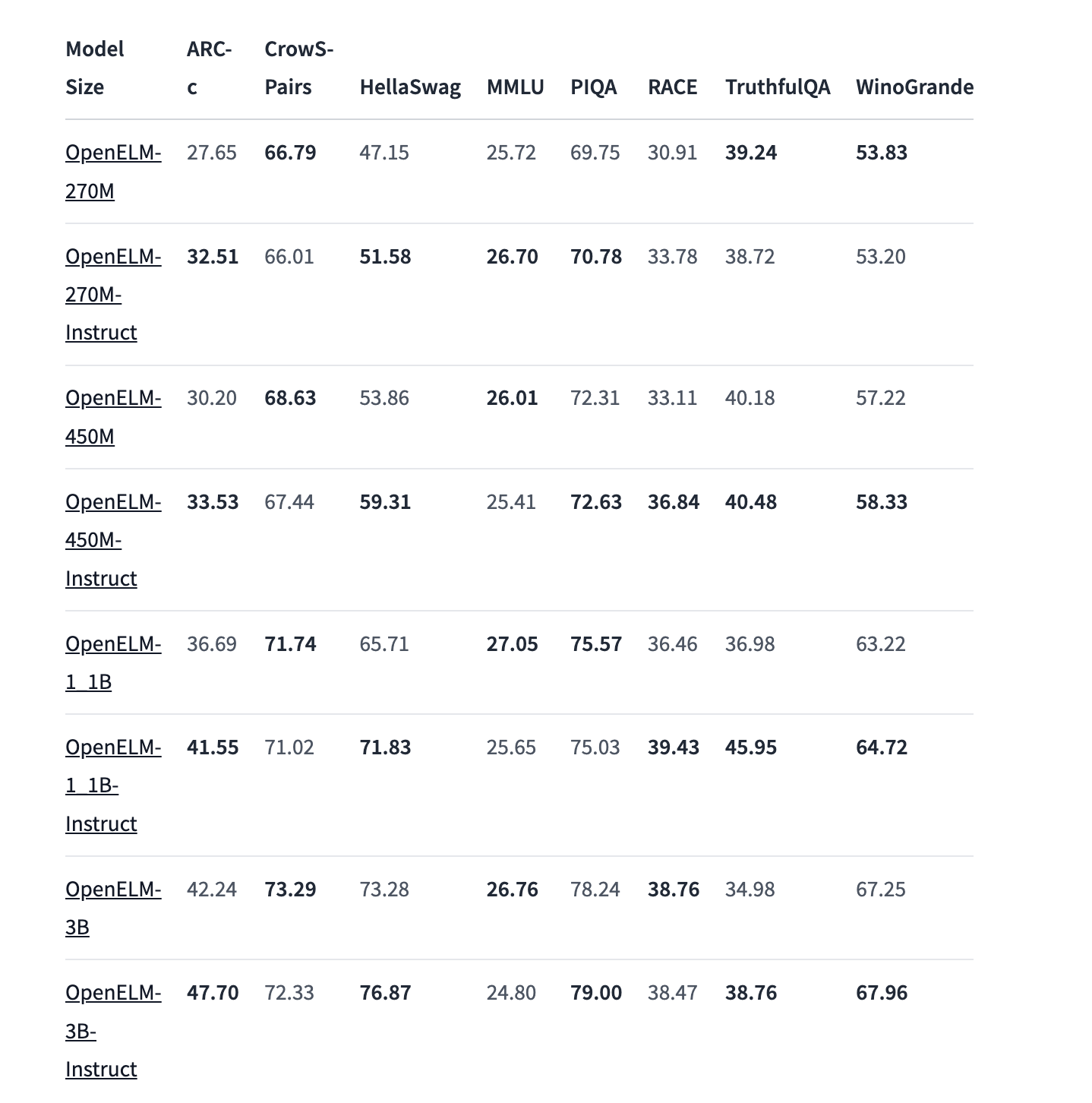
OpenELM models were pre-trained using the CoreNet library. The models come in 270M, 450M, 1.1B, and 3B parameters, both pre-trained and fine-tuned according to instructions.
The pre-training dataset consists of RefinedWeb, deduplicated PILE, a subset of RedPajama, and a subset of Dolma v1.6, totaling approximately 1.8 trillion tokens. Please review the licence agreements and terms of use for these datasets before utilising them.
For instance, with a parameter budget of around one billion parameters, OpenELM demonstrates a remarkable 2.36% increase in accuracy compared to OLMo, while requiring only half the pre-training tokens.
In benchmarking, modern, consumer-grade hardware was used, with BFloat16 as the data type. CUDA benchmarks were conducted on a workstation equipped with an Intel i9-13900KF CPU, 64 GB of DDR5-4000 DRAM, and an NVIDIA RTX 4090 GPU with 24 GB of VRAM, running Ubuntu 22.04.
To benchmark OpenELM models on Apple silicon, an Apple MacBook Pro with an M2 Max system-on-chip and 64GiB of RAM, running macOS 14.4.1, was employed.
Token throughput was measured in terms of tokens processed per second, including prompt processing (pre-fill) and token generation. All models were benchmarked sequentially, with a full “dry run” generating 1024 tokens for the first model to significantly increase the throughput of generation for subsequent models.
The entire framework, including training logs, multiple checkpoints, pre-training configurations, and MLX inference code, has been made open-source, aiming to empower and strengthen the open research community, facilitating future research efforts.















































































