



The exploding and disappearing gradient problems are the issues that arise when using gradient-based learning methods and backpropagation to train artificial neural networks. To address these problems, different approaches are used. ReLU is sometimes used as an activation function to address the vanishing gradient problems. But in some cases, on one hand it solves the vanishing gradient problem, on the other hand, it causes the exploding gradients problem. In this article, we will try to understand this tradeoff in detail that is caused by the ReLU function. The following are the main points that will be discussed in this article.
Table of Contents
- Understanding the Problems with Gradients
- Vanishing Gradient Problem
- Exploding Gradient Problem
- Why Does This Happen?
- How to Know the Model is Suffering from these Issues?
- ReLU can Solve the Vanishing Gradient Problem
- ReLU can Cause Exploding Gradient Problem
Let us begin with understanding the different kinds of problems with gradients.
Understanding the Problems with Gradients
Let us first understand the different problems faced by gradient-based algorithms.
Vanishing Gradient Problem
As the backpropagation method progresses downwards (or backward) from the output layer to the input layer, the gradients frequently become less and smaller until they approach zero, leaving the weights of the beginning or lower layers essentially unchanged. As a result, gradient descent never converges to the best solution. This is known as the problem of vanishing gradients.

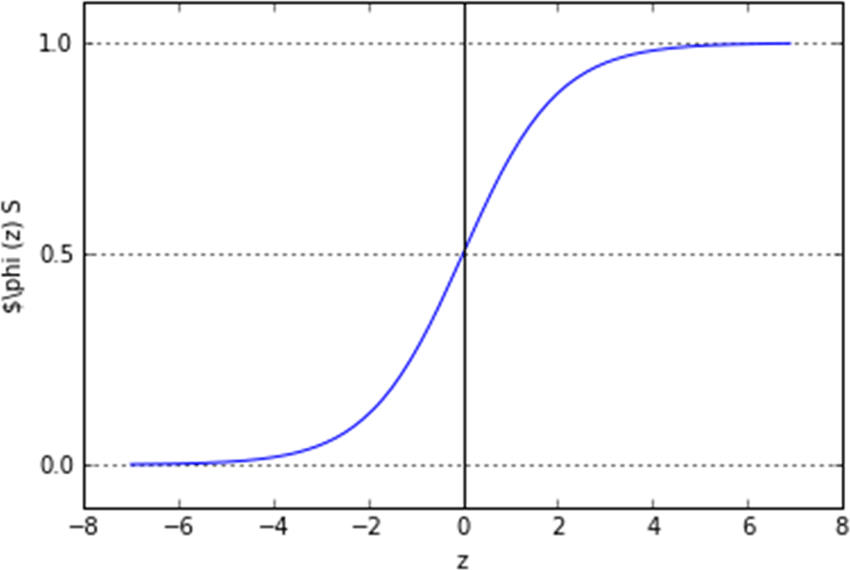
Vanishing gradients are common when the Sigmoid or Tanh activation functions are used in the hidden layer units. When the inputs grow extremely small or extremely large, the sigmoid function saturates at 0 and 1 while the tanh function saturates at -1 and 1.
In both of these examples, the derivatives are very near to zero. Let’s name these function ranges/regions saturated regions or terrible regions. As a result, if your input is located in one of the saturating regions, it has essentially no gradient to propagate back through the network.
Exploding Gradient Problem
The direction and magnitude of an error gradient are calculated during the training of a neural network and are used to update the network weights in the correct direction and by the appropriate amount.
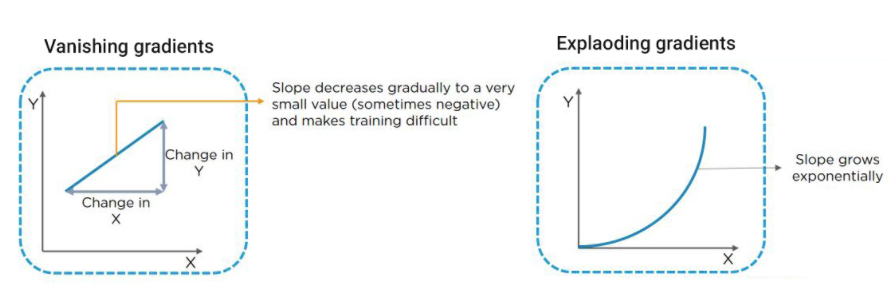
Error gradients can collect during an update in deep networks or recurrent neural networks, resulting in very high gradients. As a result, the network weights are updated often, resulting in an unstable network. Weight values can become so large that they overflow and result in NaN values if taken to an extreme. The explosion is caused by continually multiplying gradients through network layers with values greater than 1.0, resulting in exponential growth.
Exploding gradients in deep multilayer Perceptron networks can lead to an unstable network that can’t learn from the training data at best and can’t update the weight values at worst. Exploding gradients in recurrent neural networks can result in an unstable network that can’t learn from training data and, at best, can’t learn over long input sequences of data.
Why Does This Happen?
Certain activation functions, such as the logistic function (sigmoid), have a relatively large difference in variance between their inputs and outputs. To put it another way, they reduce and transform a bigger input space into a smaller output space that sits between [0,1].
Similarly, suppose that the initial weights supplied to the network result in a high loss in some circumstances. Gradients can now collect during an update, resulting in very big gradients, which eventually results in huge modifications to network weights, resulting in an unstable network. The parameters can occasionally become so enormous that they overflow and produce NaN values.
How to Know Whether Model is Suffering from these Issues?
The following are some indicators that our gradients are exploding or disappearing can be identified:
For vanishing;
- The parameters of the higher layers vary dramatically, whereas the parameters of the lower levels do not change significantly for Vanishing (or not at all).
- During training, the model weights may become zero.
- The model learns slowly, and after a few cycles, the training may become stagnant.
For Exploding:
- The model parameters are growing exponentially.
- During training, the model weights may become NaN.
- The model goes through an avalanche learning process.
ReLU can Solve the Vanishing Gradient Problem
The sigmoid activation function, as we saw in the previous section, is prone to disappearing gradients, especially when several of them are coupled together. This is because the sigmoid function saturates at zero for large negative values and at one for large positive values.
As you may be aware, rather than the logistic sigmoid function, most neural network topologies now use the rectified linear unit (ReLU) as an activation function in the hidden layers. If the input value is positive, the ReLU function returns it; if it is negative, it returns 0.
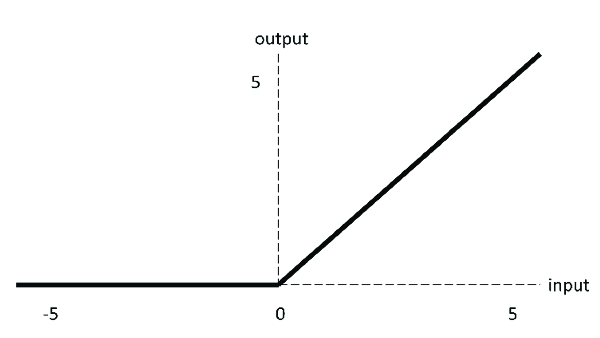
The ReLU’s derivative is 1 for values larger than zero. Because multiplying 1 by itself several times still gives 1, this basically addresses the vanishing gradient problem. The negative component of the ReLU function cannot be discriminated against because it is 0. As a result, negative values’ derivatives are simply set to 0.
ReLU can Cause Exploding Gradient Problem
The sigmoid and Tanh activation functions were used as the default activation function for a long time. For modern deep learning neural networks, the rectified linear activation function is the default activation function. The ReLU can be used with almost any kind of neural network. It is suggested that Multilayer Perceptron (MLP) and Convolutional Neural Network (CNN) models make it the default (CNNs). The use of ReLU with CNNs has been extensively researched and almost always results in improved results, which may surprise you at first.
When combined with CNNs, ReLU can be used as the activation function on the filter maps, followed by a pooling layer. LSTMs have traditionally used the Tanh activation function to activate the cell state and the sigmoid activation function to activate the node output. ReLU was thought to be unsuitable for Recurrent Neural Networks (RNNs) such as the Long Short-Term Memory Network (LSTM) by default due to their careful design.
ReLU is an activation function that is well-known for mitigating the vanishing gradient problem, but it also makes it simple to generate exploding gradients if the weights are large enough, which is why weights must be initialized to very small values. The exploding gradient is the inverse of the vanishing gradient and occurs when large error gradients accumulate, resulting in extremely large updates to neural network model weights during training. As a result, the model is unstable and incapable of learning from your training data.
Although using He initialization in combination with any variant of the Relu activation function can significantly reduce the problem of vanishing/exploding gradients at the start of the training, it does not guarantee that they will not reappear later.
The bias on the node is the input with a fixed value. The bias has the effect of altering the activation function, and the bias input value is traditionally set to 1.0. Consider setting the bias to a low value, such as 0.1, when utilizing ReLU in your network. The weights of a neural network must be initialized to small random values before training. When you use ReLU in your network and set the weights to small random values centred on zero, half of the units will output a zero value by default.
For example, following uniform weight initialization, almost half of the continuous output values of hidden units are genuine zeros. The output of ReLU is unbounded in the positive domain by design. This means that the output can, in some situations, continue to grow in size. In this situation, if high error gradients develop in the network due to potential error, this causes the size weights to grow, causing the model to behave unstably or improperly.
To prevent this, we must employ certain regularization approaches, such as an L1 or L2 vector norm. This is an excellent approach for promoting sparse representations (e.g., with L1 regularization) and lowering the model’s generalization error.
Final Words
Through this post we have seen, what are the two major phenomena that occur often while training your neural network that is vanishing and exploding gradient. We saw the causes and effects of both phenomena. There are various methods to deal with it. Specifically, we have seen how can we handle it using the activation function ReLU. In context to the ReLu, we have seen how it can tackle both problems. If you try to rethink on it may cause to explode gradient quickly if your model encountered the increasing positive trend because as discussed the is unbounded in the positive region that’s why we need have to regularize the behaviour.














































































