



|
Listen to this story
|
In the area of conversational technology, the recently released ChatGPT has taken all the accolades. But, another player in the market released long before OpenAI’s stint with AI chatbot—which many still tout to be the better of the two—deserves considerable attention. LaMDA, Google’s conversational chatbot, was very much in the news for being called “sentient” by its own engineer. However, in his latest tweet, Blake Lemoine said that with all the buzz of ChatGPT, Google is still a few years ahead with their advanced dialogue system.
LaMDA vs ChatGPT
The Language Model for Dialog Applications (LaMDA) is a Transformer-based neural language model consisting of up to 137B parameters and pre-trained on 1.56T words of publicly available dialogue data and web documents. In addition, the model is fine-tuned on three metrics: Quality, Safety, and Groundedness.
In this regard, LaMDA’s progress is quantified by collecting responses from the pre-trained model, fine-tuned model, and human raters (i.e., human-generated responses) to multi-turn two-author dialogues—the responses are then evaluated by a different set of human raters on a series of questions against the above defined metrics.
On the other hand, ChatGPT is based on the GPT-3.5 architecture, having 175B parameters. The GPT-3.5 series consists of three models: code-davinci-002, the base model for code completion tasks, text-davinci-002, which is trained by supervised fine-tuning on human-written demonstration and samples rated 7/7 by human labellers on overall quality scores, and the most recently released text-davinci-003, the new and improved version that includes reinforcement learning with human feedback (RLHF), a reward-based model trained on comparisons by humans. The training data is a mixture of text and code from before Q4 2021.
Similar to LaMDA, ChatGPT uses a supervised-learning model, where human AI trainers are given access to model suggestions to craft responses and train the model playing both sides—the user and AI assistant. Following which, the trainers ranked the responses from the chatbot’s conversation with them as well as the sampled alternative completions based on quality.
Is Google really way ahead?
Scale AI’s Riley Goodside compares the responses generated from ChatGPT and LaMDA—calling the former as an “unlovable C-3PO”—with the responses reading almost like a Q&A platform, compared to the latter which is friendly and, in real terms, “conversational”. This can be directly correlated to the fact that LaMDA is trained on dialogues, whereas ChatGPT is said to be highly trained on web texts.
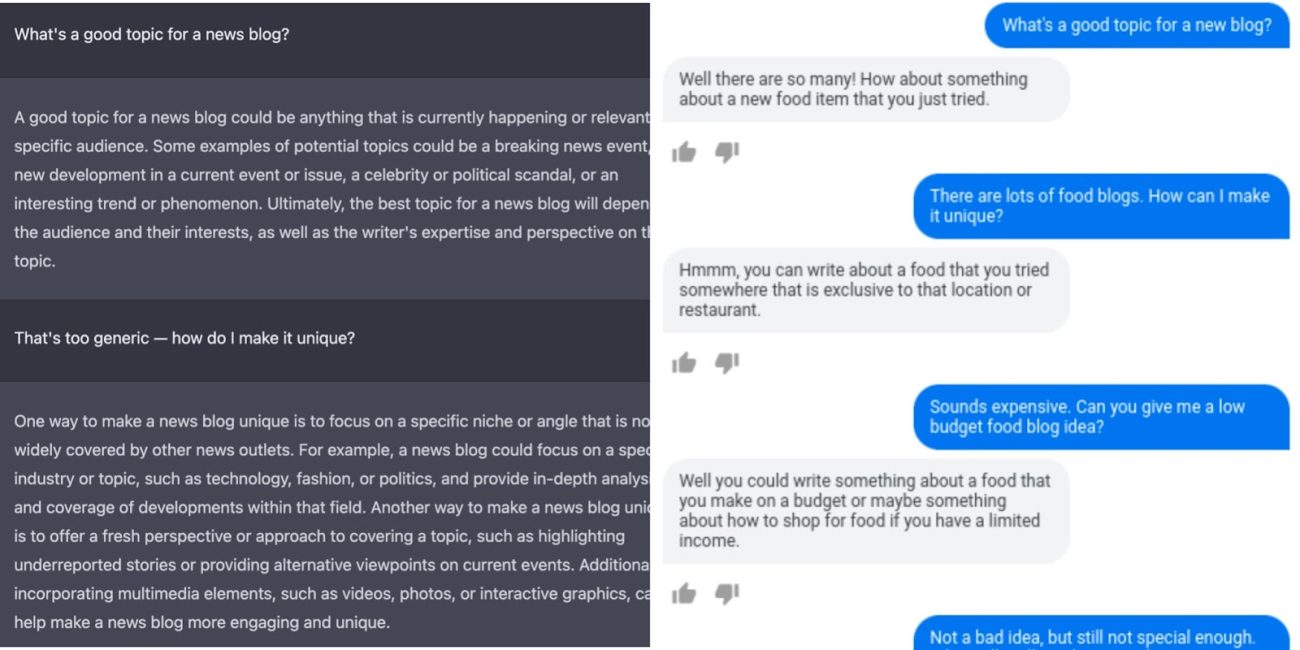
Further, OpenAI’s conversational AI is also described by many to be producing shallow content, almost as if regurgitated from Wikipedia. However, the AI has also been receiving much flak for various things including producing incorrect information, fake quotes, and non-existing references.
Read: Why is Everyone Bashing ChatGPT?
But, LaMDA, on the other hand, carries an edge in this context because of the various metrics it produces in its responses. For example, the groundedness metric verifies the responses based on authoritative external sources. Similarly, the quality metric measures responses based on dimensions like Sensibleness, Specificity, and Interestingness (SSI). That is, it ensures that the responses make sense in the context they are asked, are non-generic, and are also insightful, unexpected or witty.

Goodside also adds that while one can prompt-inject ChatGPT into behaving the way however one likes, this would mean that users put their own disclaimer accepting that they understand that it’s not real. If not, users will be talking to the protocol droid.
Does this imply a lost cause for ChatGPT? Not Quite.
RLHF shedding light on ChatGPT’s path
While there have been several errors reported by users on the output produced by ChatGPT, one of the more interesting aspects about OpenAI’s model is that the GPT-3.5 architecture uses a reinforcement learning model (RLHF), a reward-based mechanism based on human feedback, thereby making it better and better. LaMDA, on the other hand, doesn’t use RLHF.
Take, for instance, the post by Google’s Cassie Kozyrkov which received a lot of traction on social media for pointing out the inaccuracies with which ChatGPT produces information. To her prompt asking the usefulness of ChatGPT and its relation to GANs, it produced a wild output not really rooted in reality, stating that, “It [ChatGPT] uses GANs to generate responses to input text, allowing it to engage in natural-sounding conversations with humans.” The claim made it an object of ridicule by many.
However, while everyone did their fair share of bashing, what was omitted from the conversation was that the model learns from its behaviour. When the same prompt was used again, the response generated was entirely different and accurate. It writes, “ChatGPT uses a neural network architecture known as a transformer, which is designed to process and analyse large amounts of data.”
That being said, the model still fails on many fronts. The response to the prompt, for example, fails to produce the answer to how it relates to GANs, and needs more layers of verification to source information better.
With the release of ChatGPT, there is a growing belief that Google will soon integrate the latest version of the model into its search engine. In addition, Google effectively has a monopoly on search. A twitter user by name Uncle Ari writes, “LaMDA can be embedded in search such that it not only answers the questions asked, but cites its sources.” The integration will hugely change how we interact with search. The flip side of the coin is that OpenAI’s partnership with Microsoft also allows them to access ChatGPT in their own search engine—Bing. Ultimately, who will win the search engine war is something to wait for.
The game is not over
Besides Google and OpenAI, Meta also has its own chatbot called Blenderbot, the third iteration of which was released a few months ago. The conversational AI prototype is based on 175B parameters, and has its own long-term memory. The model uses dialogue history, the internet, and memory to produce output. Meta and Google have been keeping information about their chatbots increasingly under the wraps, but we can expect them to make an announcement when they are completely ready—especially, considering what Google had to go through last time they released prematurely.
















































































