


In this article, we will discuss how Convolutional Neural Networks (CNN) classify objects from images (Image Classification) from a bird’s eye view.

First, let us cover a few basics. Let us start with the difference between an image and an object from a computer-vision context.
What we see above is an image. We can see 3 objects inside – 1 cat and 2 dogs. If you wish, we can count the ribbon on the head of the left one as 4th object.
There are mainly 2 types of images – Red Green Blue (RGB) scale and grayscale (black & white) as illustrated below. RGB has 3 channels – Red, Green and Blue while Grayscale has only 1 channel.

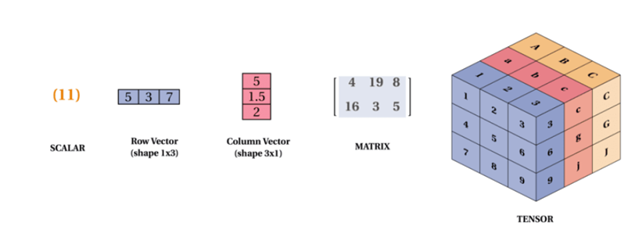
Computers only understand the language of mathematics. Hence we will convert images to tensors using libraries like Python Imaging Libraries (PIL). We can imagine tensors as n-dimensional matrices as illustrated below.
Now let us understand how computers classify images using CNN. Below is a high-level representation of how CNNs work.
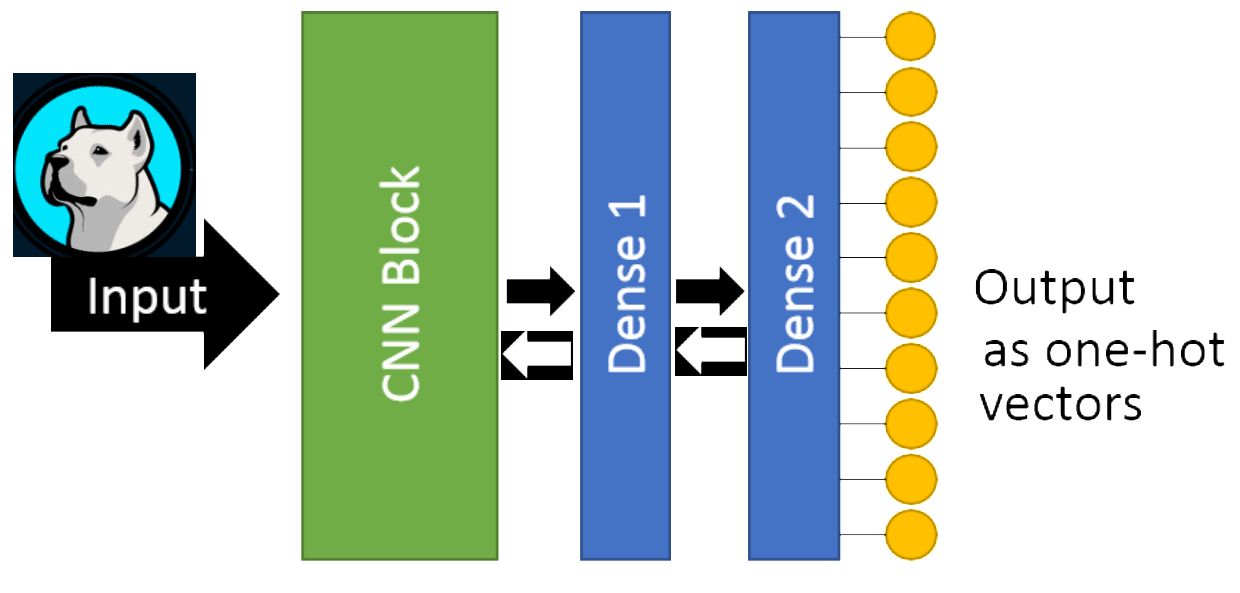
Let us understand the above flow block-by-block. Please note that information is flowing back and forth. Black arrows represent forward pass while white arrows represent a backward pass.
Forward Pass
This is where the image is broken down into features, reconstructed and predicted at the end. Let us examine each step involved.
- Input:
Images will be fed as input which will be converted to tensors and passed on to CNN Block.
2. CNN Block
This is the most important block in the neural networks. The following steps will happen inside the CNN block.
- Input tensor will be broken down into basic channels. Imagine this like dismantling an assembled lego board to smaller pieces.
- The features inside these channels are then used to construct edges and gradients.
- Using these edges and gradients, we construct textures and patterns.
- From these textures and patterns, we build parts of objects.
- These parts of objects will be used to reconstruct objects.
The below image shows these steps.

We perform the above steps with the help of a mathematical operation called convolution. Input tensors that CNN blocks receive are comprised of numerical values that represent the pixel amplitudes from the original image. The convolution operation is performed on these input channels using kernels to extract features. Kernels are also tensors with values in each cell. We call kernel values as weights.
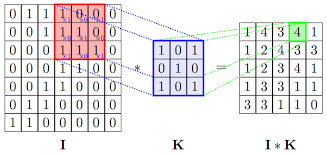
Below is an example of a convolution operation performed on a 7×7 input channel (I) using a 3×3 kernel (K) to extract a 5×5 feature (I * K). Values appearing in output are sum-product of each convolution.
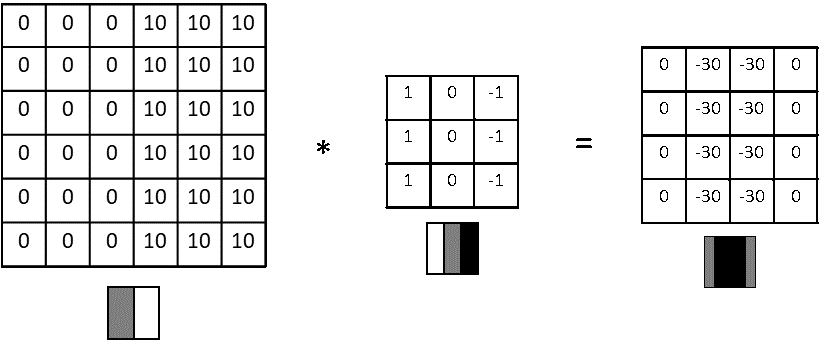
Below is another example that shows how a vertical edge is extracted using convolutions. An edge is detected when there is a sharp change in pixel values. Please note that higher numbers in tensor represent brighter pixels i.e. 10 will be brighter than 0.
CNN block will have multiple convolutional layers stacked one after another with the objective of extracting edges and gradients -> textures & patterns -> parts of object -> object.
- Dense 1, Dense 2
Towards the final convolution layers, we can expect channels to resemble the original object that we are attempting to classify. These channels will be multi-dimensional. We need to flatten this to a 1-D array to make it compatible for a logistic regression classifier. First step in this process represented as Dense 1 is an operation called Global Average Pooling (GAP) as shown below. Here we are reducing the channel of size 6x6x3 to 1x1x3.
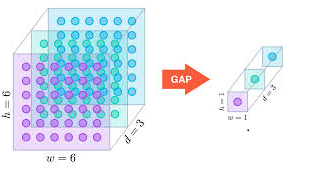
Next, we will flatten our 1x1x3 channel to a one-dimensional array with 3 elements. We either use 1×1 convolution operations or functions like nn.linear in Pytorch to achieve this. This step is represented as Dense 2 in forwarding flow. The below image depicts this operation.
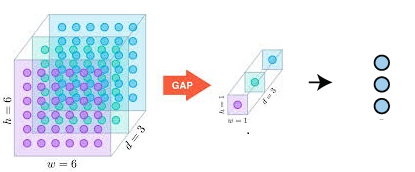
A number of elements in the 1-D array must be exactly equal to the classes involved in the image classification problem. For example, if we are trying to predict digits, then a number of classes and hence a number of elements in the 1-D array will be 10 to accommodate digits from 0-9.
2. Output as One-Hot Vector
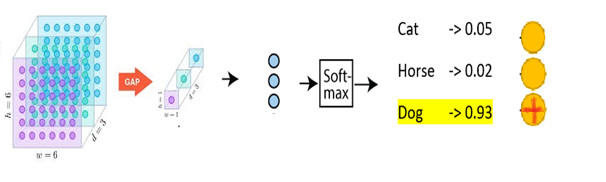
Final step in the forward pass is classifying the image. We will feed flattened 1-D array to a logistic regression classifier to predict the image class. The most commonly used classifier for this task is Softmax. Softmax gives the probability distribution of the list of classes. The class with the highest probability will be selected as the predicted class. In the below example dog will be predicted class. We call the output as One-Hot Vector because only one of the nodes (predicted class) will have value.
Backward Pass
We covered how an image is classified via forward pass. Next, let us inspect what happens backward. We call this back propagation. This is where CNN collects feedback and improves itself.
- After prediction, each layer will receive feedback from its preceding layer. Feedback will be in the form of losses incurred at each layer during prediction.
- Aim of the CNN algorithm is to arrive at optimal loss. We call this as local minima.
- Based on the feedback, network will update the weights of kernels.
- This will make the output of convolutions better when next time forward pass happens.
- When the next forward pass happens, loss will come down. Again, we will do back prop, the network will continue to adjust, a loss will further come down and process repeats.
- This forward pass followed by back prop keeps happening the number of times we choose to train our model. We call it epochs.
I hope this gave you a high-level understanding of how a deep learning Convolutional Neural Network (CNN) works and classifies objects from an input image.
This article is presented by AIM Expert Network (AEN), an invite-only thought leadership platform for tech experts. Check your eligibility.







































































