


 Image Source: marcobarcelon.deviantart.com
Image Source: marcobarcelon.deviantart.com
Disclaimer: The aim of the article is to convey why GPU is better than a CPU.
The use of GPUs in the 3D gaming realm has given rise to a high-definition gaming experience for gamers all over the world. Now, these mighty devices are being used in the world of deep learning to produce robust results — exactly 100 times faster than a CPU.
The reason why GPU is so powerful is because the number of cores inside it are three to five times more than the number of cores in a CPU, all of whom work parallelly while computing. In this article, we shall be comparing two components of the hardware world — a CPU, an Intel i5 4210U vs a GPU, a GeForce Nvidia 1060 6GB. With the help of one basic high-dimensional matrix multiplication, the famous MNIST dataset, we shall compare the computation power and speed of these devices.
Benchmarks
The first benchmark we are considering is a matrix multiplication of 8000×8000 data. Both the matrices consist of just 1s. We shall run it on both the devices and check the training speed on both the Intel CPU and Nvidia GPU.
High Dimensional Matrix Multiplication
The G ops idea for the benchmark was taken from one of the StackOverflow posts.
https://gist.github.com/analyticsindiamagazine/4ae1f5dcf7ab3a839e6d10e6a4ee6089
After running this code on the Intel CPU, it took about 16 seconds to complete the 8000×8000 multiplication. And the number of G ops/sec (Giga operations or billions operation per second) is 63.36. The number of cores on the Intel CPU is just 2, with a memory frequency of 1.7Ghz which can run on a Turbo boost up to 2.7Ghz. This benchmarking is based on the stock product and not overclocked ones.
Now let us look at the performance of the GeForce Nvidia 1060 6GB GDDR5.
https://gist.github.com/analyticsindiamagazine/e129ab277290a58d2fd52cd5b38ce1df
Nvidia 1060 performed or computed the whole code in milliseconds. It took about 0.29 seconds with 3588.87 G ops/sec to complete the matrix multiplication of 8000×8000 dimensions. This was a real eye-opener. With 1280 CUDA-enabled cores and with a memory speed of 8 Gbps this machine can run the most advanced data in seconds.
MNIST With Tensorboard
This code was taken from one of github’s repo while we were trying to understand the working CNNs.
https://gist.github.com/analyticsindiamagazine/4e3fe007ff0f3ba2257ac21958996b88
Training the famous MNIST for 10000 iterations, the CPU took about 27 minutes 52 seconds to complete the training with an accuracy of around 98 percent which is quite decent, considering the MNIST dataset. The batch size was of 64 with a softmax activation function.
Let us look at the accuracy and the loss on the tensorboard scalar graphs.


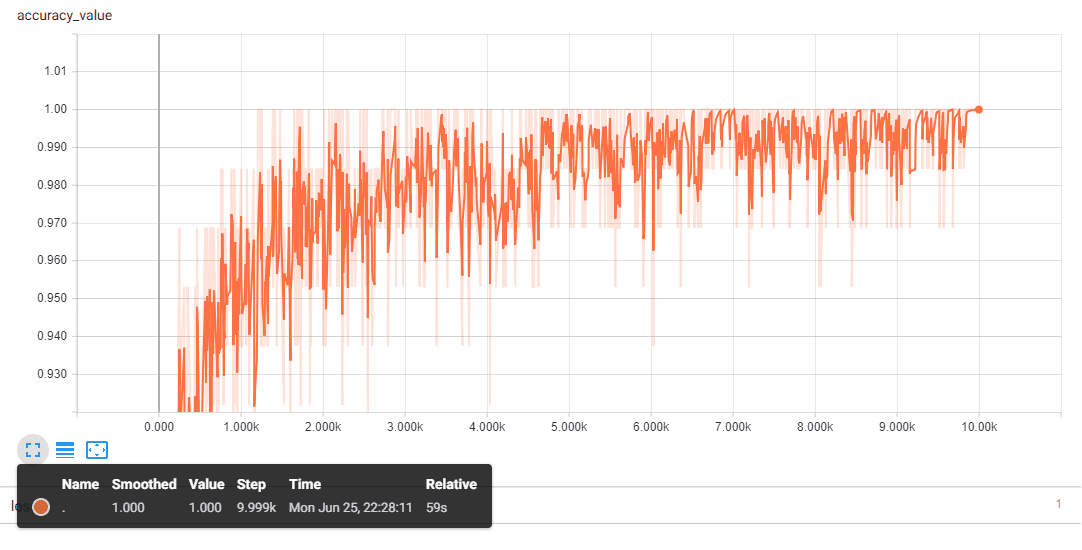
Let us look at the performance of GeForce Nvidia 1060 GPU.
The same code was run on the machine, with the same batch size, activation function and learning rate. Here is the code:
https://gist.github.com/analyticsindiamagazine/bc753dda564ca0a7cc55a28322d3a936
The GPU took only 59 seconds to train the whole dataset consisting of 60,000 images of handwritten digits which is fascinating. Let us look at the accuracy and the loss graphs visualised on the tensorboard.

| Time Taken | Intel i5 – 4210U 1.7GHz | GeForce Nvidia 1060 6GB GDDR5 |
| Matrix Multiplication of 8000×8000 | 16 seconds at 63.36 G ops/sec | 0.29 seconds at 3588.87 G ops/sec |
| Training of MNIST (60,000 images) | 27 minutes 47 seconds | 59 seconds |
Conclusion
As we have had access to compare these two devices with respect to deep learning aspects, we recommend having an additional GPU which supports the CUDA and cuDNN for artificial intelligence application. With this benchmarking, we are looking forward to the release of Intel GPUs which are going to be out in 2020.















































































