



|
Listen to this story
|
Diffusion models have been gaining popularity in the past few months. These generative models have been able to outperform GANs on image synthesis with recently released tools like OpenAI’s DALL.E2 or StabilityAI’s Stable Diffusion and Midjourney.
Recently, DALL-E introduced Outpainting, a new feature which lets users expand the original borders of an image, adding visual elements of the same style by natural language description prompts.
Fundamentally, generation models that work on the diffusion method can generate images by first randomising the training data by adding Gaussian noise, and then recovering the data by reversing the noise process. The diffusion probabilistic model (diffusion model) is a parameterised Markov chain trained using different inferences to produce images matching the data after a given time.
The genesis
Image synthesis came into existence in 2015 when Google Research announced the Super Resolution diffusion model (SR3) that could take low-resolution input images and use the diffusion model to create high-resolution outputs without losing any information. This worked by gradually adding pure noise to the high-resolution image and then progressively removing it with the guidance of input-low resolution image.
The Class-Conditional Diffusion Model (CDM) is trained on ImageNet data to create high-resolution images. These models now form the basis for text-to-image diffusion models to provide high-quality images.
The rise of text-to-image models
Launched in 2021, DALL.E2 was developed with the idea of zero-shot learning. In this method, the text-to-image model is trained against billions of images with their embedded caption. Though the code is not yet open, DALL.E2 was announced simultaneously with CLIP (Contrastive Language-Image Pre-training) which was trained on 400 million images with text, scraped directly from the internet.
The same year, OpenAI launched GLIDE, which generates photorealistic images with text-guided diffusion models. DALL.E2’s CLIP guidance technique can generate diverse images but at the stake of high fidelity. To achieve photorealism, GLIDE uses classifier-free guidance, which adds the ability to edit in addition to zero-shot generation.
GLIDE, after training on text-conditional diffusion methods, is fine-tuned for unconditional image generation by replacing the training text token with empty sequences. This way the model is able to retain its ability to generate images unconditionally along with text-dependent outputs.

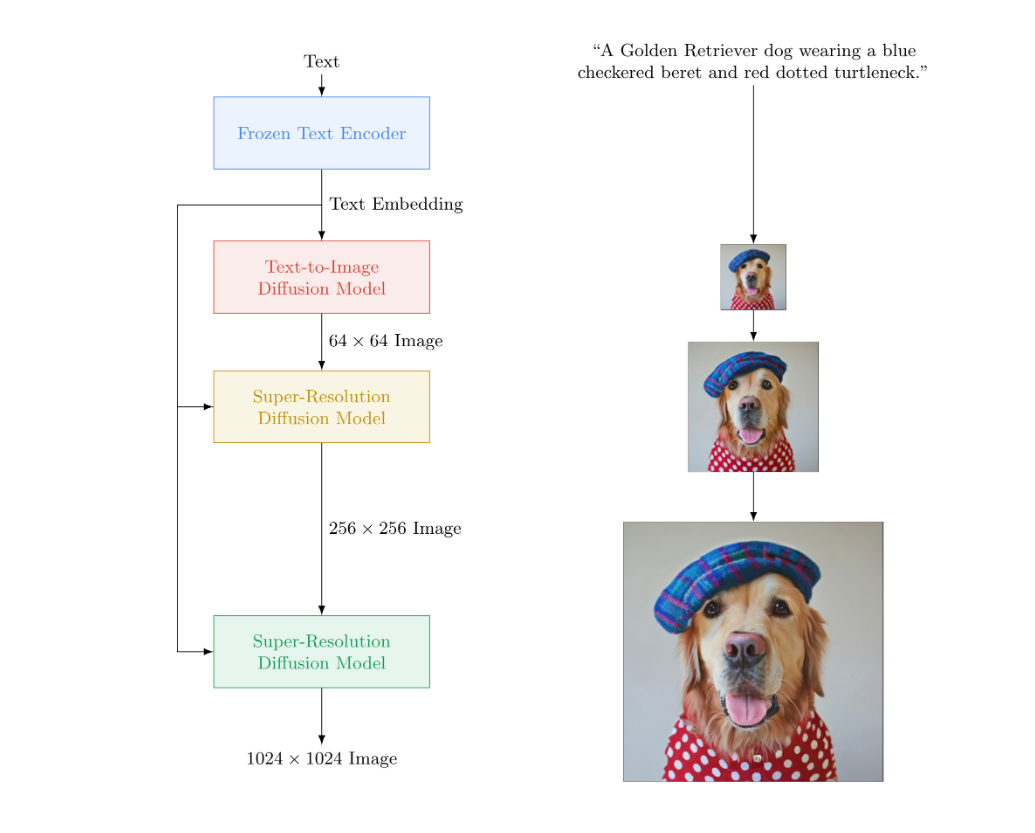
On the other hand, Google’s Imagen expands on a large transformer language model (LM) and understands text to combine it with high-fidelity diffusion models like GLIDE, de-noising diffusion probabilistic methods, and cascaded diffusion models. This then results in the production of photorealistic images with deep level language understanding in text-to-image synthesis.
Recently, Google expanded on Imagen with DreamBooth, which is not just a text-to-image generator but allows upload of a set of images to change the context. This tool analyses the subject of the input image, separates it from the context or environment and synthesises it into a new desired context with high-fidelity.
Latent Diffusion Models, used by Stable Diffusion, employ a similar method to CLIP embedding for generation of images but can also extract information from an input image. For example, an initial image will be encoded into an already information-dense space called the latent space. Similar to GAN, this space will extract relevant information from the space and reduce its size while keeping as much information as possible.
Now with conditioning, when you input context, which can be either text or images, and merge them in the latent space with your input image, the mechanism will understand the best way to mould the image into the context input and prepare the initial noise for the diffusion process. Similar to Imagen, now the process involves decoding the generated noise map to construct a final high-resolution image.
Future perfect (images)
Training, sampling and evaluating data has allowed diffusion models to be more tractable and flexible. Though there are major improvements in image generation with diffusion models over GANs, VAE, and flow-based models, they rely on the Markov chain to generate samples, making it slower.
While OpenAI has been running towards the perfect image-generation tool, there has been a massive leap in the making of multiple diffusion models, where they use various methods to improve the quality of the output, alongside increasing the fidelity, while reducing the rendering time. This includes Google’s Imagen, Meta’s ‘Make-A-Scene’, Stable Diffusion, Midjourney, etc.
Additionally, diffusion models are useful for data compression since they reduce high-resolution images on the global internet allowing wider accessibility for the audience. All this will eventually lead to diffusion models becoming viable for creative uses in art, photography and music.














































































