


|
Listen to this story
|
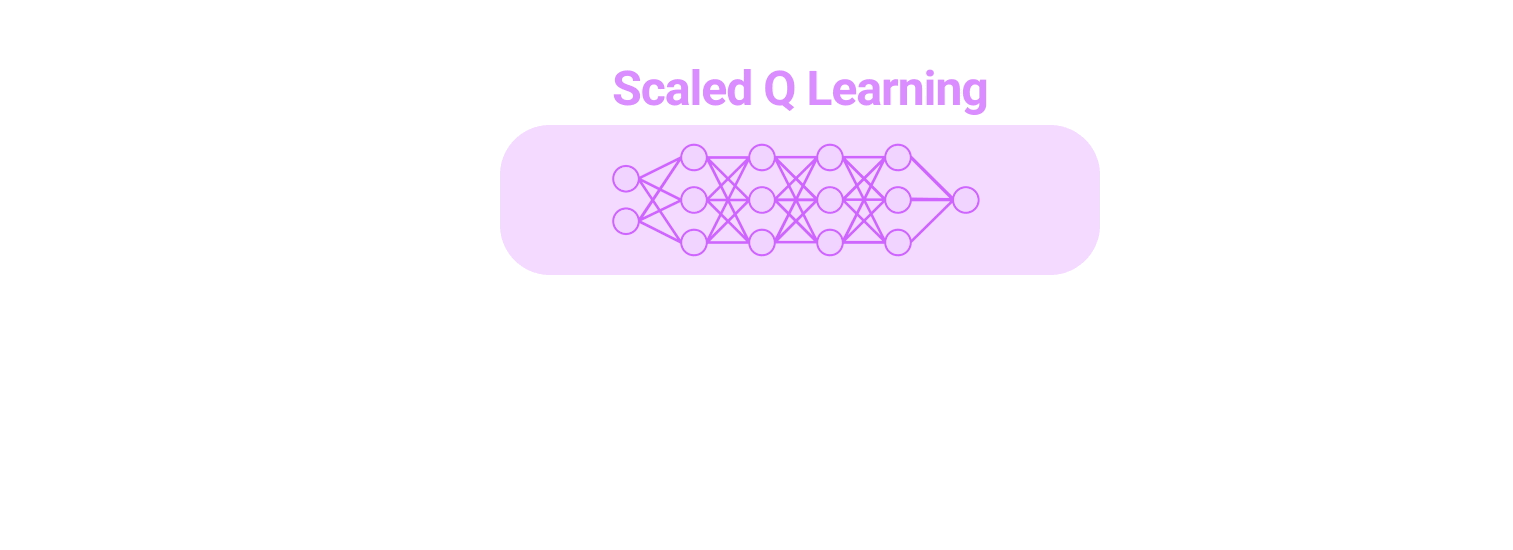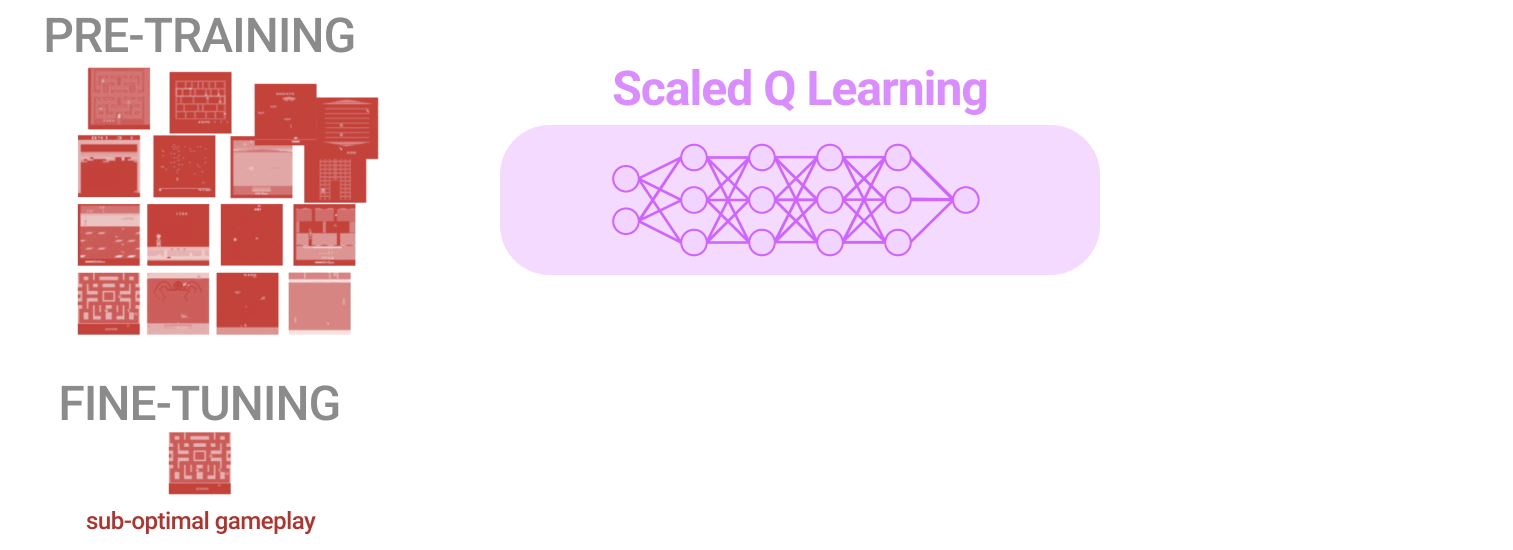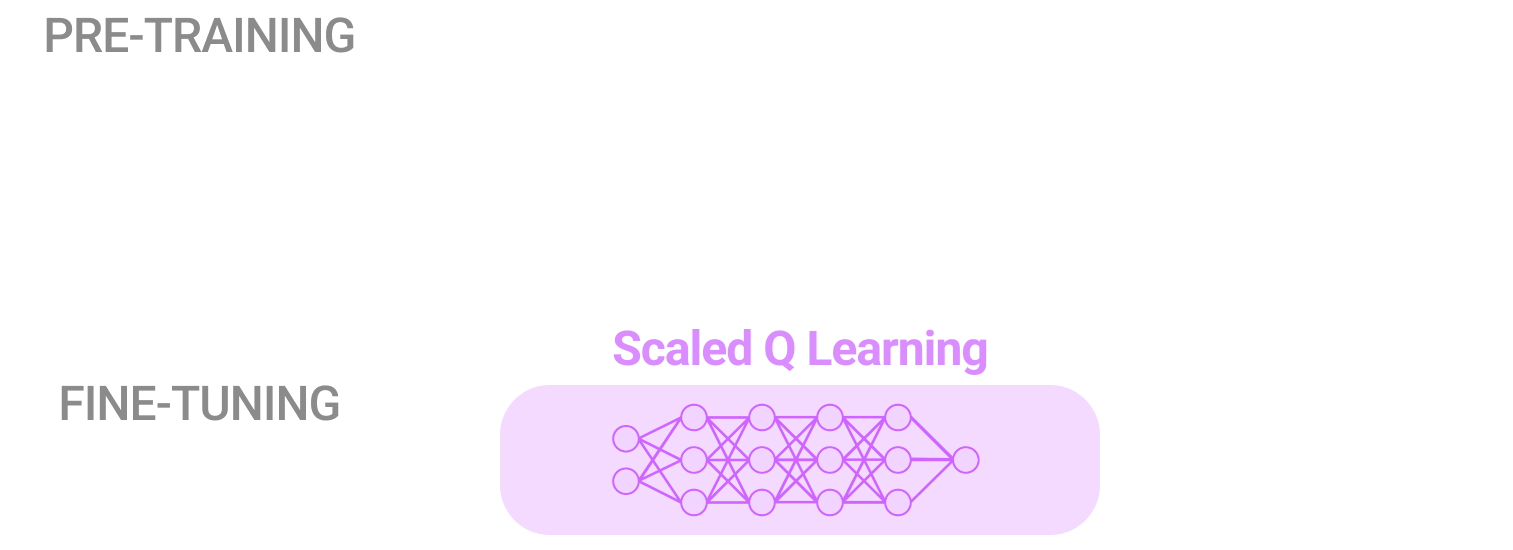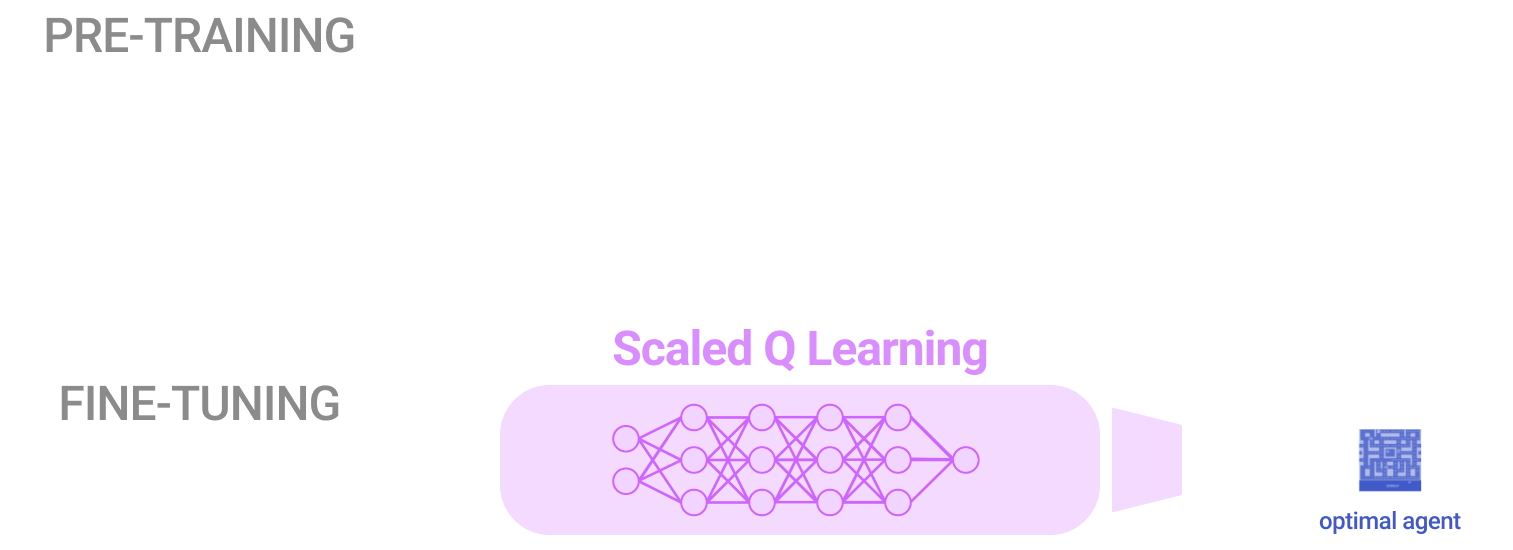
Researchers from Google have developed a pre-trained model built on the CQL algorithm for scaled offline Reinforcement Learning (RL) called Scaled Q-Learning, to efficiently train RL agents for decision-making tasks such as playing games or picking up objects.
Contrary to the traditional approach, Scaled Q-Learning uses diverse data to learn representations for quick transfer to new tasks. Moreover, it outperforms Transformer-based methods and others which use larger models. The researchers evaluated the approach on a suite of Atari games, where the goal is to train a single RL agent using data from low-quality players and then learn new variations in pre-training or completely new games.
This method made initial progress towards enabling more practical real-world training of RL agents as an alternative to costly and complex simulation-based pipelines or large-scale experiments. The team tested the method using two types of data: near-optimal data and low-quality data. They compared it to other methods and found that only Scaled Q-Learning improved on the offline data, reaching about 80% of human performance.

The study shows that pre-training RL agents with multi-task offline learning can significantly improve their performance on different tasks, even for challenging ones like Atari games with different appearances and dynamics.
The results demonstrate that the method can significantly boost the performance of RL, both in offline and online modes. In online RL, Scaled Q-Learning can provide improvements while methods like MAE yield little improvement. It can incorporate prior knowledge from pre-training games to improve the final score after 20k online interactions.
In conclusion, Scaled Q-learning suggests that it is learning the game dynamics, not just improving the visual features like other techniques. As per the blog, the work could develop generally capable pre-trained RL agents that can develop applicable interaction skills from large-scale offline pre-training. Future research will involve validating these results on a broader range of more realistic tasks, in domains such as robotics and NLP.














































































