



Text summarization, the creation of entirely new pieces of text, and the prediction of the next word like Google’s auto-fill, to name a few. Do you know what all of these NLP tasks have in common? Language models are at the heart of everything! To be honest, most complex NLP tasks require these language models as a first step. In this post, we’ll take a closer look at one of the language models, the Unigram model, by understanding its working concept and putting it into practice. We will also understand how to implement a unigram tokenizer using the Hugging Face package. The following are the topics that will be discussed in this article.
Points to be Covered:
- Types of Language Model
- What is the N-Gram model?
- Implementing Unigram Model using Hugging Face
Let us start by seeing what language models are available so far.
Types of Language Model
Language Models are classified into two types:
- Models of Statistical Language: To learn the probability distribution of words, these models employ classic statistical techniques such as N-grams, Hidden Markov Models (HMM), and specific linguistic rules.
- Models of Neural Language: These are newcomers to the NLP scene, and they use various types of Neural Networks to model language.
What is the N-Gram Model?
An N-gram model predicts the most likely word to follow a sequence of N-1 words given a set of N-1 words. It’s a probabilistic model that has been trained on a text corpus. Many NLP applications, such as speech recognition, machine translation, and predictive text input, benefit from such a model.
Consider the following two sentences: “Heavy rain” vs. “Heavy flood.” We know from experience that the first sentence sounds better. In the training corpus, “heavy rain” occurs substantially more frequently than “heavy flood,” according to an N-gram model. As a result, the first sentence is more likely to be chosen by the model.
An n-gram (also known as a Q-gram) is a contiguous sequence of n items from a particular text or speech sample. Depending on the application, the elements can be phonemes, syllables, letters, words, or base pairs. Typically, n-grams are extracted from a text or audio corpus. When the components are words, n-grams are sometimes referred to as shingles.
An n-gram model, also known as an (n-1) order Markov model, is a sort of probabilistic language model used to forecast the next item in a sequence. In probability, communication theory, computational linguistics (such as statistical natural language processing), computational biology (such as biological sequence analysis), and data compression, n-gram models are now commonly employed.
Simpleness and scalability are two advantages of n-gram models (and algorithms that employ them): bigger n allows a model to hold more context with a well-understood space-time tradeoff, allowing modest experiments to scale up efficiently.
Implementing Unigram Model using Hugging Face
The Unigram model solves the merging problem by assessing the likelihood of each subword combination rather than selecting the most common pattern. It computes the likelihood of each subword and then discards it using a loss function. You can then instruct the model to drop the bottom 20–30% of the subword tokens based on a particular threshold of the loss value.
Unigram is a purely probabilistic method that selects both the pairs of characters and the final choice to merge (or not) based on probability in each iteration. The tokenizers package from Hugging Face includes implementations of all of today’s most popular tokenizers. It also enables us to train models from scratch on any dataset of our choosing and then tokenize the input string of our choice. The datasets we used to train these models are free books from wikitext-103, which contains 516 million words.
Now let’s quickly set up the environment by running the following commands.
# We won't need TensorFlow here !pip uninstall -y tensorflow # Install `transformers` from master !pip install git+https://github.com/huggingface/transformers !pip list | grep -E 'transformers|tokenizers' # transformers version at notebook update --- 2.11.0 # tokenizers version at notebook update --- 0.8.0rc1
Download and unzip the dataset.
!wget https://s3.amazonaws.com/research.metamind.io/wikitext/wikitext-103-raw-v1.zip !unzip wikitext-103-raw-v1.zip
We’ll create and train a tokenizer in this tour. In this case, educating the tokenizer entails teaching it merging rules.
- To begin, use all of the characters in the training corpus as tokens.
- Combine the most common pair of tokens into a single token.
- Continue until the vocabulary (for example, the number of tokens) reaches the desired size.
The Tokenizer class is the library’s core API; here’s how one can create with a Unigram model:
from tokenizers import Tokenizer from tokenizers.models import Unigram tokenizer = Tokenizer(Unigram())
Next is normalization, which is a collection of procedures applied to a raw string to make it less random or “cleaner.” Stripping whitespace, eliminating accented characters, and lowercasing all text are all common actions. If you’re familiar with Unicode normalization, you’ll recognize it as one of the most popular normalization operations used by most tokenizers.
from tokenizers import normalizers from tokenizers.normalizers import NFD, StripAccents normalizer = normalizers.Sequence([NFD(), StripAccents()]) tokenizer.normalizer = normalizer
Pre-tokenization is the process of breaking down a text into smaller pieces in order to estimate how many tokens you’ll have at the end of training. To put it another way, the pre-tokenizer will divide your text into “words,” and your final tokens will be parts of those words.
Splitting inputs on spaces and punctuations, as done by the Whitespace pre-tokenizer, is a simple approach to pre-tokenize inputs:
from tokenizers.pre_tokenizers import Whitespace tokenizer.pre_tokenizer = Whitespace()
We’ll need to create a trainer, in this case, a UnigramTrainer, to train our tokenizer on the wikitext files also defining some special tokens to handle special characters and likewise.
from tokenizers.trainers import UnigramTrainer trainer = UnigramTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
We could want our tokenizer to add special tokens like “[CLS]” or “[SEP]” automatically. A post-processor is used to do this. The most frequent method in TemplateProcessing, which requires simply the specification of a template for the processing of single sentences and pairs of sentences, as well as the special tokens and their IDs.
Here’s how to configure the post-processing for standard BERT inputs:
from tokenizers.processors import TemplateProcessing
tokenizer.post_processor = TemplateProcessing(
single="[CLS] $A [SEP]",
pair="[CLS] $A [SEP] $B:1 [SEP]:1",
special_tokens=[("[CLS]", 1), ("[SEP]", 2)],)
Now, we are good to go now. We can now simply use the train() method with whatever list of files we want: Our tokenizer should only take a few seconds to train on the entire wikitext dataset.
files = [f"wikitext-103-raw/wiki.{split}.raw" for split in ["test", "train", "valid"]]
tokenizer.train(files, trainer)
It is now time to put the model to the test. A Tokenizer offers an API for decoding, which converts IDs created by your model back to the text, in addition to encoding the input texts. This is accomplished using the methods decode() (for a single predicted text) and decode batch() (for a batch of predictions).
output = tokenizer.encode('This code written in notebook')
print('Token ids:',output.ids)
print('Decoded Sequence:',tokenizer.decode([1, 181, 2580, 53, 545, 19, 72, 10, 447, 2]))

Let’s see the tokenized form of our corpus
print('Tokenized form:',output.tokens)

To handle a batch of sentence pairs, pass two lists to the encode batch() method: the list of sentences A and the list of sentences B: As a result, we have a collection of Encoding objects that are comparable to those we saw earlier. You can combine as many texts as you want as long as they fit in your memory.
output = tokenizer.encode_batch(["Hello there all!", "How are you ?"])
print('Tokens of 2nd sentence:',output[1].tokens)
Pass two lists to the encode batch() method to handle a batch of sentence pairs: the list of sentences A and the list of sentences B like below.
output = tokenizer.encode_batch(
[["Hello there all!", "How are you ?"]])
print('Tokens of 1st batch:',output[0].tokens)
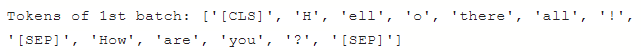
Final Words
Unigram appears to generate subword tokens that are more typically seen in the English language based on the type of tokens generated, however, this observation is not universal. These algorithms differ from one another yet do a comparable job of generating a good NLP model. However, the performance of your language model is heavily influenced by the use case, vocabulary quantity, speed, and other aspects. In this post, we have seen what kind of language models exist right now. Based on it we narrowed our discussion towards the Unigram model in which we have seen the working of the algorithm and implemented the same with the support of hugging face.














































































