



|
Listen to this story
|
German research lab Max Planck Institute recently released a research paper for Moûsai, a text-to-music model to generate long-context high-quality 48kHz stereo music beyond the minute-mark based on context exceeding the minute-mark and generate various music.
The team came up with a new, more efficient way to generate real-time audio. They created a 1D U-Net architecture that can run on a single consumer GPU. This means that it can be trained and run even in universities that don’t have access to huge resources.
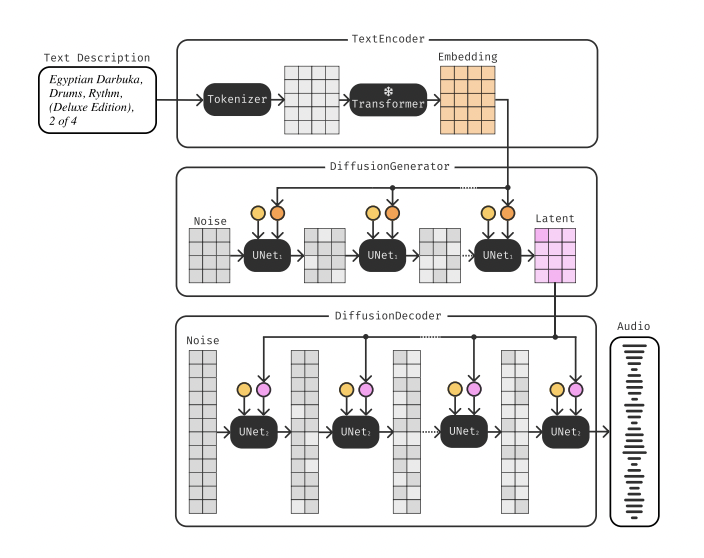
The team also introduced a new diffusion magnitude autoencoder to shrink the audio signal 64 times smaller while still keeping the quality mostly the same. This tool is used in the new architecture’s generation stage to improve the audio sound.
Read the full paper here.

Generating music involves multiple elements such as temporal dimension, long-term structure, multiple sound layers, and subtleties that only trained ears can pick up.
Joining Meta, last week, big tech Google also unveiled MusicLM, a generative model for creating high-fidelity music from text descriptions, such as “a calming violin melody supported by a distorted guitar riff”. MusicLM makes music at 24 kHz that holds steady for several minutes by modelling the process of conditional music synthesis as a hierarchical sequence-to-sequence modelling problem.
Read more: Google Unveils MusicLM, a Music DALL-E
Diffusion models are becoming increasingly popular. They’re not just used for images anymore. With the power of these models, anything can be created from text — videos, speech, and even music.
Music synthesis is the latest arena for diffusion models. While there has been some progress, there’s still much more to discover and explore in this exciting field.














































































