



|
Listen to this story
|
Meta might have just upped its multimodal and multilingual offering with the latest release of SeamlessM4T — Massively Multilingual & Multimodal Machine Translation model.
SeamlessM4T is a foundational speech/text translation and transcription model, and an all-in-one system that performs multiple tasks such as speech-to-speech, speech-to-text, text-to-text translation, and speech recognition. The model facilitates input and output in 100 languages, and speech output in 35 languages (including English). However, what does it offer that sets it apart from existing translator models?
Meta’s SeamlessM4T vs OpenAI Whisper vs Google AudioPaLM
With speech-to-text translation models by tech companies already prevalent in the market, Meta seems to be pushing to carve a niche for itself. OpenAI and Google have developed their own speech-to-text models, namely Whisper and AudioPaLM-2, respectively. Whisper, an open-sourced multilingual speech recognition model, can translate and transcribe speech from over 97 diverse languages, and has been trained on over 680,000 hours of multilingual data. Whereas, Google’s AudioPaLM is a multimodal language model built on the capabilities of PaLM-2 and its generative audio model AudioLM.
When evaluated with other Speech-to-Text (S2T) and Speech-to-Speech translation (S2ST) models via ASR BLEU (Automatic Speech Recognition Bilingual Evaluation Understudy), a metric for evaluating the quality of machine-generated translations, SeamlessM4T (shown in blue) scores better than the others.
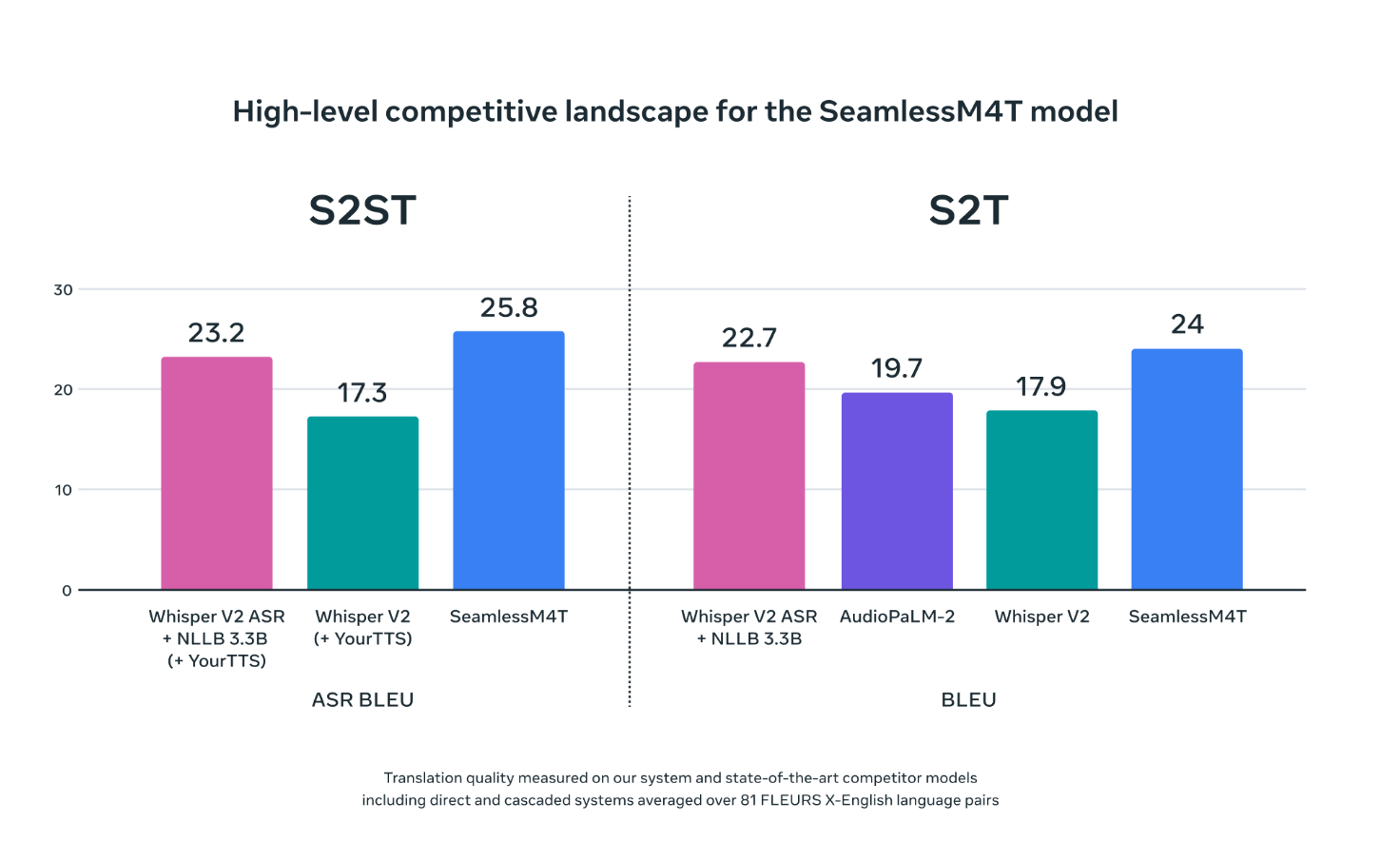
Source: Meta AI Blog
Companies are now actively seeking to incorporate multi-language translation as the next major development. Addressing the diverse vernacular markets worldwide, language translation and transcription are emerging as essential product offerings.
Indian IT giant Tech Mahindra is working on an indigenous LLM that would have the ability to speak in a number of Indic languages with different dialects, most notably Hindi. With Project Indus the model will have the ability to speak in 40 different Indic languages, to begin with. More languages that have originated in the country will also be added subsequently.
Recently, Eleven Labs, a research lab that explores frontiers of Voice AI, introduced Eleven Multilingual v2, an AI speech model that supports 28 languages with enhanced conversational capability and higher output quality.
Not For Everyone
Meta’s SeamlessM4T is made publicly available under CC BY-NC 4.0 licence — a non-commercial licence which means that people can remix, adapt and build on it but cannot use it for commercial purposes. This has been critically debated by users on how Meta is limiting adoption and deviating from the conventional way of offering on Apache. A user on Hacker News, spoke about how restricting others from engaging with models, providing enhancements, offering input and developing an ecosystem, while only benefiting oneself doesn’t align with good community conduct.
There are also few who have called the move of holding back such models from open sourcing as a move against competitor companies. However, with Meta’s Llama 2 that concern seems unwarranted. A user even mentioned that there’s ‘nothing particularly special about the weights or training data.’
Chasing ‘Multimodal’
‘Multimodality’ is a coveted feature big tech companies are going after. However, not all deliver on their promises. OpenAI’s GPT-4 which was released earlier this year as a multimodal platform was said to allow inputs via images, voice and text, however it has not been able to fulfil all the offerings. Image integration is still not available for users and voice inputs can be given only via ChatGPT app.
Meta has released other multimodal models in the past. The company released CM3leon last month which generates both text-to-image and image-to-text, however, the model code was not released to the public. Being categorised as a multimodal offering, SeamlessM4T offers both text and speech, thereby fulfilling the tag. However, with the non-commercial licence that comes with the product, it is to be seen to what extent the adoption happens.













































































