



|
Listen to this story
|
Microsoft researchers have challenged the traditional approach to language model (LM) pre-training, which uniformly applies a next-token prediction loss to all tokens in a training corpus. Instead, they propose a new language model called RHO-1, which utilises Selective Language Modeling (SLM).
Click here to check out the GitHub Repository.
This method selectively trains on useful tokens that align with the desired distribution, rather than attempting to predict every next token.
They have introduced Rho-Math-v0.1 model with Rho-Math-1B and Rho-Math-7B which achieve 15.6% and 31.0% few-shot accuracy on MATH dataset, respectively — matching DeepSeekMath with only 3% of the pretraining tokens.
Rho-Math-1B-Interpreter is the first 1B LLM that achieves over 40% accuracy on MATH.
Rho-Math-7B-Interpreter achieves 52% on MATH dataset, using only 69k samples for fine-tuning.
RHO-1’s SLM approach involves scoring pre-training tokens using a reference model and training the language model with a focused loss on tokens with higher excess loss. This selective process allows RHO-1 to improve few-shot accuracy on 9 maths tasks by up to 30% when continually pre-training on a 15B OpenWebMath corpus.
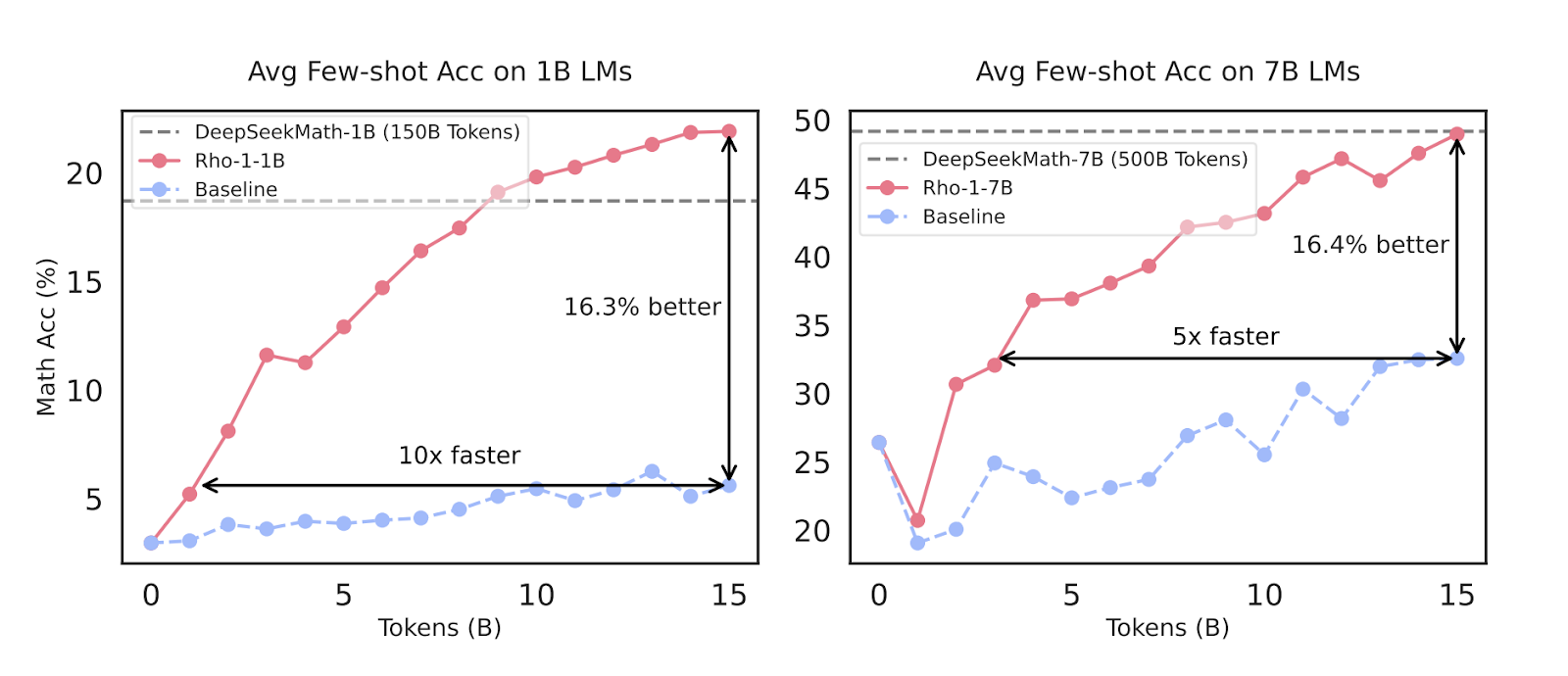
The model also achieves state-of-the-art results on the MATH dataset after fine-tuning and shows an average enhancement of 6.8% across 15 diverse tasks when pre-training on 80B general tokens.
Traditional training methods often filter data at the document level using heuristics and classifiers to improve data quality and model performance. However, even high-quality datasets may contain noisy tokens that negatively impact training.
The SLM approach directly addresses this issue by focusing on the token level and eliminating the loss of undesired tokens during pre-training.
SLM first trains a reference language model on high-quality corpora to establish utility metrics for scoring tokens according to the desired distribution. Tokens with a high excess loss between the reference and training models are selected for training, focusing the language model on those that best benefit downstream applications.
In the study, tokens selected by SLM during pre-training were closely related to mathematics, effectively honing the model on the relevant parts of the original corpus. Investigating token filtering across various checkpoints, the researchers found that tokens selected by later checkpoints tend to have higher perplexity towards the later stages of training and lower perplexity in earlier stages.
The discussion section highlights future work, including potential generalisation of SLM beyond mathematical domains, scalability of the technique to larger models and datasets, and exploration of whether training a reference model is necessary for scoring tokens.
Improvements upon SLM may include reweighting tokens instead of selecting them and using multiple reference models to reduce overfitting.
SLM could be extended to supervised fine-tuning to address noise and distribution mismatches in datasets, and to alignment tasks by training a reference model that emphasises helpfulness, truthfulness, and harmlessness to obtain a natively aligned base model during pre-training.














































































