



As a result of different interior designs and living activities, real-world indoor scenes vary greatly in terms of the number, type, and layout of objects placed in a room. Have you ever wondered how these indoor scenes are now generated by leveraging the power of AI in practical issues like object dimensions, object location, accurate mapping, and so on? In this post, we’ll take a look at a transformer, named SceneFormer, that can generate a realistic 3D indoor scene. The key points to be discussed are listed below.
Table Of Contents
- What is Indoor Scene Generation
- How SceneFormer Address the Task?
- Layout and Architectural Details
- Data Preparation
- How SceneFormer is Used?
Let’s start the discussion by understanding what is indoor Scene Generation
What is Indoor Scene Generation
For 3D content creation, creating realistic 3D indoor scenes has a wide range of real-world applications. Real estate and interior design firms, for example, can quickly visualize a furnished room and its contents without having to rearrange any physical items. Such a room can be presented using augmented or virtual reality platforms, such as a headset, allowing a user to walk through and interact with their future home.
Manually modelling indoor scenes in a room with a variety of realistic object layouts is a time-consuming task that requires professional skills. In two steps, automatic scene generation techniques attempt to model the properties and distributions of objects in real-world scenes and generate new 3D scenes.
These methods determine the layout (i.e. orientation and position) and properties (e.g. type and shape) of the objects in a room of a specific size and shape. Then, based on the object’s properties, they retrieve a Computer-Aided Design (CAD) model of each object from a 3D object database and place the resulting CAD models in the room according to their layout.
A graph is a natural representation of a scene, in which each object is a node and an edge is a relationship between objects (for example, ‘is next to’ or ‘is on top of’). Walls, doors, and windows are examples of room features that can be represented as nodes in a graph.
When the model is autoregressive on the graph and can generate one node at a time, the input is initialized with the required object nodes and then the model is expanded repeatedly. Such a representation lends itself well to graph convolutional networks processing.
A scene can be represented by a top-down view of the objects, walls, and floor. Object properties are predicted as continuous or discrete values, and walls and floors are predicted as binary images. This can be used to represent arbitrary room shapes and sizes by normalizing the room dimensions to a known maximum dimension along each axis. Modern CNN architectures, such as ResNet, can help with image representations.
Now let’s discuss how SecneFormer takes this task
How SceneFormer Address the Task?
The task of scene generation from a room layout is addressed by Xinpeng Wang et al, who generate a set of objects and their arrangements in the room. Each object is given a predicted class category, a three-dimensional location, an angular orientation, and a three-dimensional size.
The most relevant CAD model for each object is retrieved from a database and placed in the scene at the predicted location once this sequence has been generated. A CAD model’s usefulness can be determined solely by its size, shape descriptor, or other heuristics such as texture. CAD model selection reduces object collisions, allows for special object properties like symmetry, and ensures object style consistency.
SceneFormer is a set of transformers that autoregressively predict the class category, location, orientation, and size of each object in a scene, based on the idea that a scene can be treated as a sequence of objects. It has been demonstrated that such a model can generate realistic and varied scenes with little domain knowledge or data preparation. Furthermore, it does not use any visual information as input or as an internal representation, such as a 2D rendering of the scene.
In summary, SceneFormer converts scene generation into a sequence generation task by producing an indoor scene as a sequence of object properties. It relies on the self-attention of transformers to learn implicitly the relationships between objects in a scene, obviating the need for manually annotated relationships.
It can also create complex scenes by predicting their 3D locations using discretized object coordinates based on the room layout or text descriptions. It constructs conditional models using the Transformer decoder’s cross-attention mechanism.
Layout and Architectural Details

The layout of SceneFormer (source)
It takes as input the room layout, which describes the shape of the room and the locations of doors and windows, as shown in the above layout. The SceneFormer model sequentially generates the properties of the next object before inserting it into the existing scene. The final output scene can be seen on the right.
Data Preparation
Each scene is treated as a sequence of objects in the data preprocessing, ordered by the frequency Fci of their class categories Ci in the train set. This object ordering, up to the ordering within objects of the same class, is required to produce a unique representation of each scene.
The object’s location is then normalized by the maximum room size and quantized into the range [0, 255], yielding the object’s new coordinates (x, y, z). Similarly, the length, width, and height of each object are scaled and quantized. They then added start and stop tokens to each sequence, indicating the start and end, before padding the sequence to the maximum length available in the train set.
How SceneFormer is used?
The model architecture is depicted in the diagram below. To generate object property sequences, we use the transformer decoder. Researchers trained a separate model to predict the corresponding token of the current object for each of the four properties. The properties of objects are predicted in an autoregressive way, with each object’s properties conditioned on the properties of previously predicted objects.
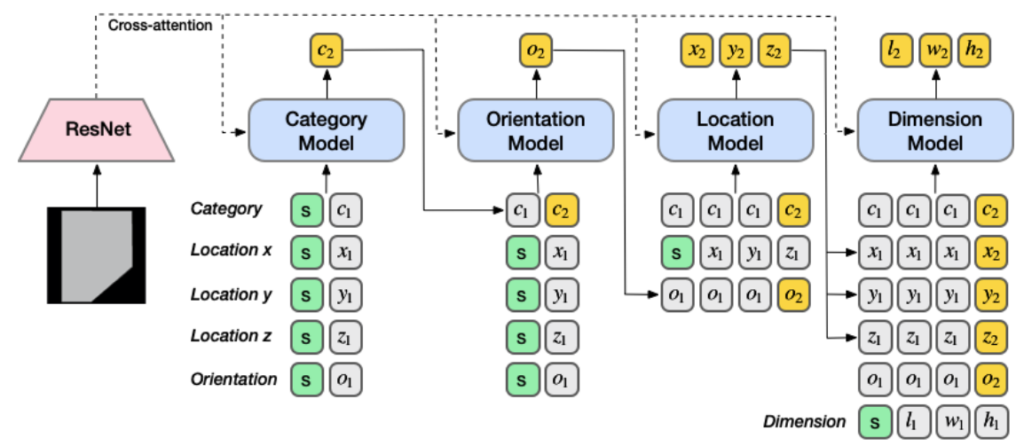
Architecture SceneFormer (Source)
In the above-mentioned architecture Start tokens are shown in green, existing object tokens are shown in grey, and new object tokens are shown in yellow. Padding and stop tokens are not included. As input, all models take three types of sequences: category, orientation, and location. Except in the case of the dimension model, their outputs are appended to the existing sequence before being passed on. A model with N output tokens is run N times, with each step producing one token.
Now let’s quickly discuss how the above transformer represents the sequence, embedding, and inference procedure.
Sequence Representation
Multiple sequences are fed into each model. Because each object’s location (x, y, z) and dimension (l, w, h) are three-dimensional, the input sequences for location and dimension are constructed by concatenating tuples of (xi, yi, zi)i and (li, wi, hi)i. As a result, the remaining input sequences should be repeated three times. The corresponding input sequence is shifted to the left by one token to condition on properties of the current object during training.
Embedding Procedure
For each model, it employs learned position and value embeddings of the input sequences. The object’s position in the sequence is indicated by the position embedding. The token’s value is indicated by the value embedding.
Researchers have added another embedding layer to the location and dimension models to indicate whether the token is an x, y, or z coordinate for the location sequence and whether the token is l, w, or h for the dimension sequence.
The embeddings of all sequences are then added together. With a linear layer, the output embedding is converted to N logits, where N is the number of possible quantized values. With a cross-entropy loss, each network is trained independently.
Inference Procedure
Object properties are generated in the order of class category, orientation, location, and dimension during inference. The corresponding sequence is appended with the new token and given as input to the next model once a new token is generated. Each of the location and dimension models is run three times, yielding three different output tokens (x, y, z) and (l, w, h), respectively.
The model selects the token with the highest score from the other three models using probabilistic nucleus sampling on the category model outputs with p = 0.9. The sequence is terminated if any model outputs a stop token.
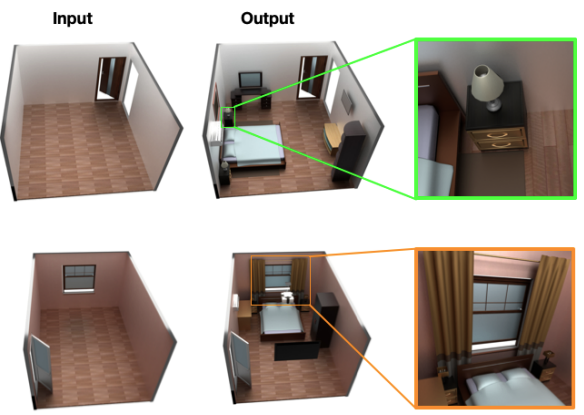
The below example shows How SceneFomer generates an indoor scene by supplying the layout of your room.
Final Words
We have seen a transformer-based model SceneFormer in this post, which aims to generate 3D realistic indoor scene results in real-time applications by leveraging a combination of transformer models. SceneFormer allows for flexible data learning, implicit object relations learning, and quick inference. This may make it possible to generate interactive scenes from partial scenes.














































































