




As technology gets smarter and powerful, computer vision applications are getting omnipresent and are pushing limits as to what can be achieved at a broader level. Computer vision (CV) is no longer restricted to a narrow range of inspection and automation evident in shop floors, or the manufacturing sector.
Be it autonomous driving or medical diagnosis, CV is exploring every critical and non-critical practical elements to resolve complexities associated with them. With areas such as artificial neural networks growing significantly, the field of CV can be coupled with them to augment applications such as facial recognition and video processing.
In this article, we will discuss a recent research study that has come up with detecting eye information in facial images through Convolutional Neural Networks (CNN). This will lay down a path in aiding CV applications that rely on facial features like eyes, in the future.
Current Eye Detection Methods
Eye detection in CV has been a subject of interest in the research community off late. Even though there are plenty of eye detection methods available, many of them lag at obtaining high-efficiency and accuracy in eye detection. Be it the standard oculography techniques, or detection through grey-level images of human faces, the results are not precisely accurate or robust.
In fact, algorithms such as ensemble regression trees, Viola-Jones algorithm etc., have also looked into capturing eye positions and made noteworthy progress. But, then again, they face trouble due to certain factors like illumination and image noises (colour, contrast etc.) innate in the pictures.
Now, a recent study by researchers Bin Li and Hong Fu, has worked on eye detection by adopting CNNs for the technique. Their method will help determine eye locations from images of human faces. Focussing on regions surrounding the eye for analysis, the CNNs would identify the exact eye details (right/left eye and centre of the eye)
How It Works
For the study, the researchers consider databases from GI4E and BioID apart from their own created datasets, for facial image data. Using these data, the method is divided into three steps. The first step entails the calculation of extreme points and gradient values in the images, to generate candidate eye regions. The second step involves deploying a set of CNNs which identifies the eye class (left/right eye) while the third step has another set of CNNs to locate the centre position of the eyes.
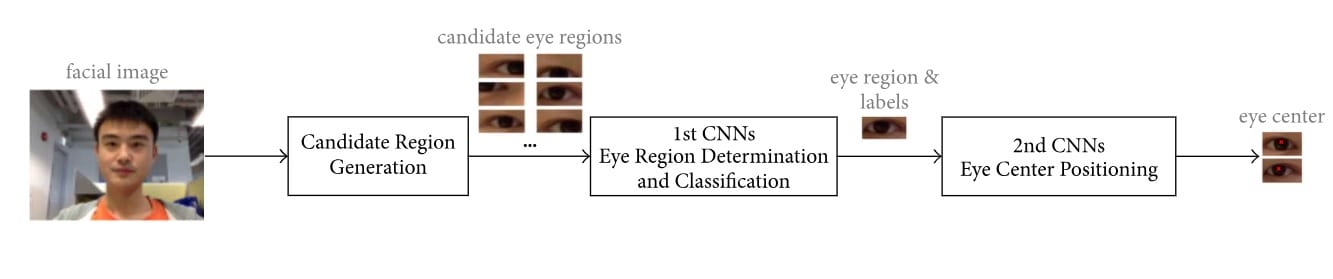
At the candidates region generation stage, the researchers choose image regions surrounding eyes to mitigate innate problems such as light variations, occlusion etc. in face images captured through face-detector software and algorithms. This is the reason they narrow it down to eye parts like pupil and iris. Li and Fu say:
“We need to quickly propose the valid eye candidate regions that can significantly reduce the search space of the accurate eye location. In our observation, we found that the pupil and iris were darker than other parts of the eye. The locations of the local extreme points in the image are more likely to be the rough centre positions of the eyes.”
In order to do this eye generation process, they use three Gaussian kernels to obtain Gaussian images so that each pixel in the image serves as the reference point amongst themselves for concatenating eye features.
Creating CNNs, Training and Evaluation
Once eye regions are generations, two sets of CNN are built to analyse these Gaussian images for eye classification (right/left eye) and eye centre detection respectively. The CNN architectures are given below.
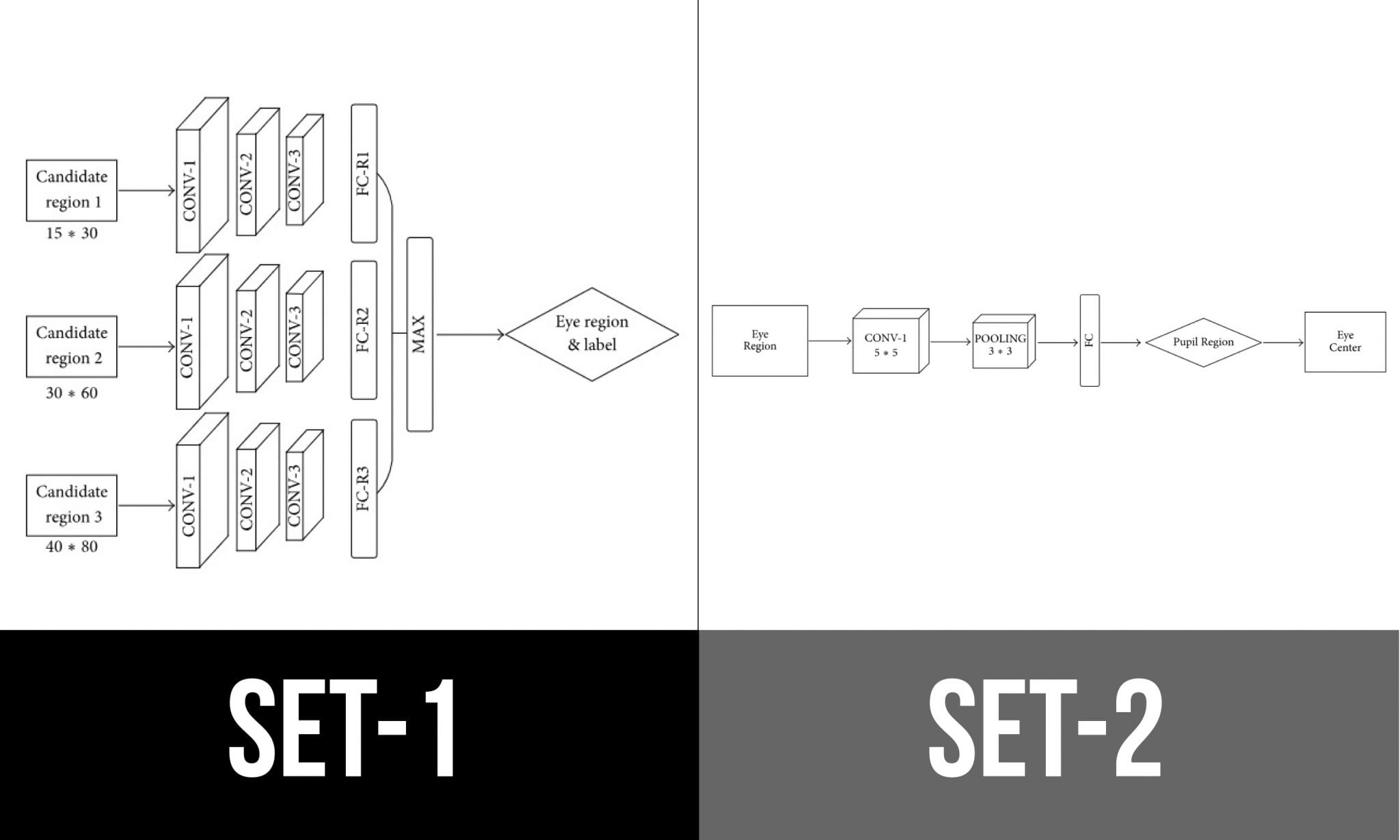
The first set of CNN has three convolutional layers with each layer accommodating a specified kernel size. This is to input the generated eye regions for classification. On the other hand, the second set of CNN consists of four layers i.e. a convolution layer, an average pooling layer, a fully connected layer, and a logistic perceptron. The outputs from the first set serves as the input for these CNNs.
Once the CNNs are created, they are ready for training. The researchers consider three ‘candidate boxes’ for ascertaining candidate eye regions. Furthermore, Li and Fu manually label images required for creating training samples. Now, training is carried out for both sets of CNNs.
To evaluate the performance, they test the method/algorithm on an Intel(R) Core(TM) i5-6600 desktop computer with 16GB RAM and NVIDIA GeForce GTX 745 GPU. All of the algorithm structure was made available through MATLAB.
The accuracy in detecting eye regions was accounted to be 99 percent and 90 percent respectively for eye classification and eye centre location.
Conclusion
Compared to earlier research in eye detection methods, Li and Fu’s study fare really good in accuracy as well as in terms of efficiency for eye detection. In addition, their study was quick and reduced training time significantly (just four hours). Although, their implementation needs to be tested on a large scale nonetheless the study offers a benchmark status for niche facial feature recognition such as eyes.
















































































