



|
Listen to this story
|
Wayve AI has released LINGO-2, a new model that links vision, language, and action to explain and determine driving behavior.
LINGO-2 is the first closed-loop vision-language-action driving model (VLAM) tested on public roads. The core functionality of LINGO-2 lies in its ability to generate real-time driving commentary while actively controlling a vehicle.
While LINGO-1 could retrospectively generate commentary on driving scenarios, its commentary was not integrated with the driving model. Therefore, its observations were not informed by actual driving decisions.
However, LINGO-2 can both generate real-time driving commentary and control a car. This integration of language and action allows the model to provide explanations for its driving decisions, such as slowing down for pedestrians or executing overtaking maneuvers.
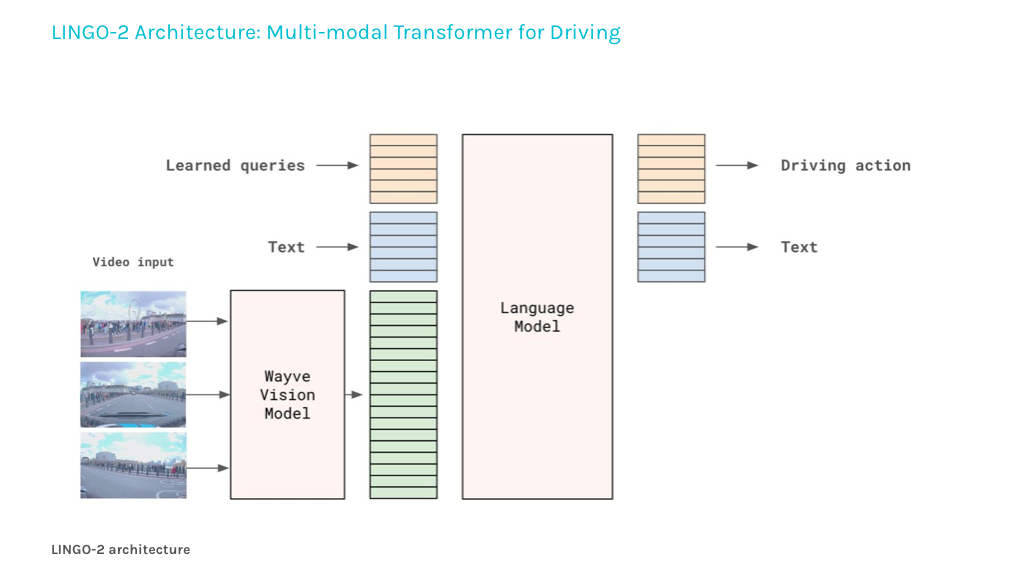
LINGO-2 comprises two modules – the Wayve vision model and an auto-regressive language model. The vision model processes camera images into token sequences, which, along with conditioning variables like route and speed, are fed into the language model.
LINGO-2’s New Capabilities
Adaptive Driving Behavior: LINGO-2 can be directed through language prompts, such as “pull over” or “turn right,” to adjust its driving behavior. This capability not only aids in model training but also enhances the interaction between humans and vehicles.
Real-time Interrogation of AI: LINGO-2 is equipped to predict and respond to queries about the surroundings and its decision-making process while on the road.
Live Driving Commentary: Through the integration of vision, language, and action, LINGO-2 can articulate its actions and reasoning in real time, offering insights into the AI’s decision-making mechanisms.














































































