



While the world is hell-bent on getting their hands on NVIDIA GPUs such as H100, Databricks has made a strategic move towards utilising AMD GPUs to elevate their LLM training capabilities, and it is working marvellously for the company.
Last year, Databricks partnered with AMD for using its 3rd Gen EPYC Instance processors. In June, Databricks acquired MosaicML, which was using AMD MI250 GPUs for training AI models. The enterprise software company has observed the potential of AMD, and is banking on the chip-making companies’ next release of MI300X to rise up in the generative AI space.
AMD GPUs seem to have witnessed a surge in community adoption, proving their mettle in the field of AI. Prominent AI startups, including Lamini and Moreh, have embraced AMD MI210 and MI250 systems to fine-tune and deploy custom LLMs. Lamini revealed its big secret just a week ago that it is running its LLMs on AMD’s Instinct GPUs.
Moreh, for instance, succeeded in training a language model with a staggering 221B parameters using 1200 AMD MI250 GPUs. Moreh was recently also backed by AMD in a $22 million series B fund. Open-source LLMs like AI2’s OLMo have also embraced the power of large clusters of AMD GPUs for their training needs.
Databricks had announced that they had received early access to a groundbreaking multi-node MI250 cluster as part of the AMD Accelerator Cloud (AAC). This cluster comprises 32 nodes, each housing 4 AMD Instinct MI250 GPUs, and features an 800Gbps interconnect. This setup is tailor-made for rigorous LLM training at scale on AMD hardware.
Now the company has scaled up to using 128 MI250 GPUs.
The reason is simple — software
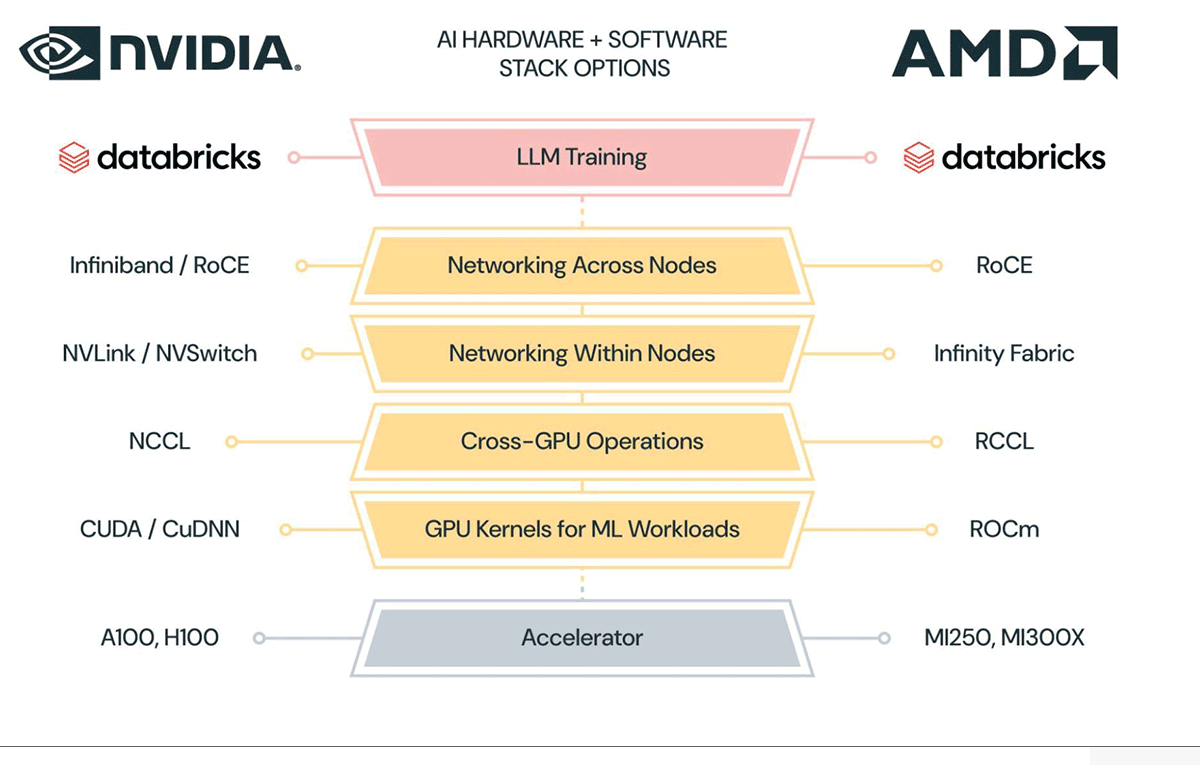
We all know about NVIDIA’s real moat being CUDA, its software behind all of its AI prowess. AMD also has realised this and has been at the forefront of software innovation, notably with the AMD Radeon Open eCosystem (ROCm) software platform, which is AMD’s alternative to CUDA.
Recently, Vamsi Boppana, senior VP of AI at AMD, said that ROCm is the company’s number 1 priority at the moment. “We have much larger resources actually working on software, and CEO Lisa Su has been very clear that she wants to see significant and continued investments on the software side,” he said.
Read: AMD Focuses on Software Ahead of MI300X Release
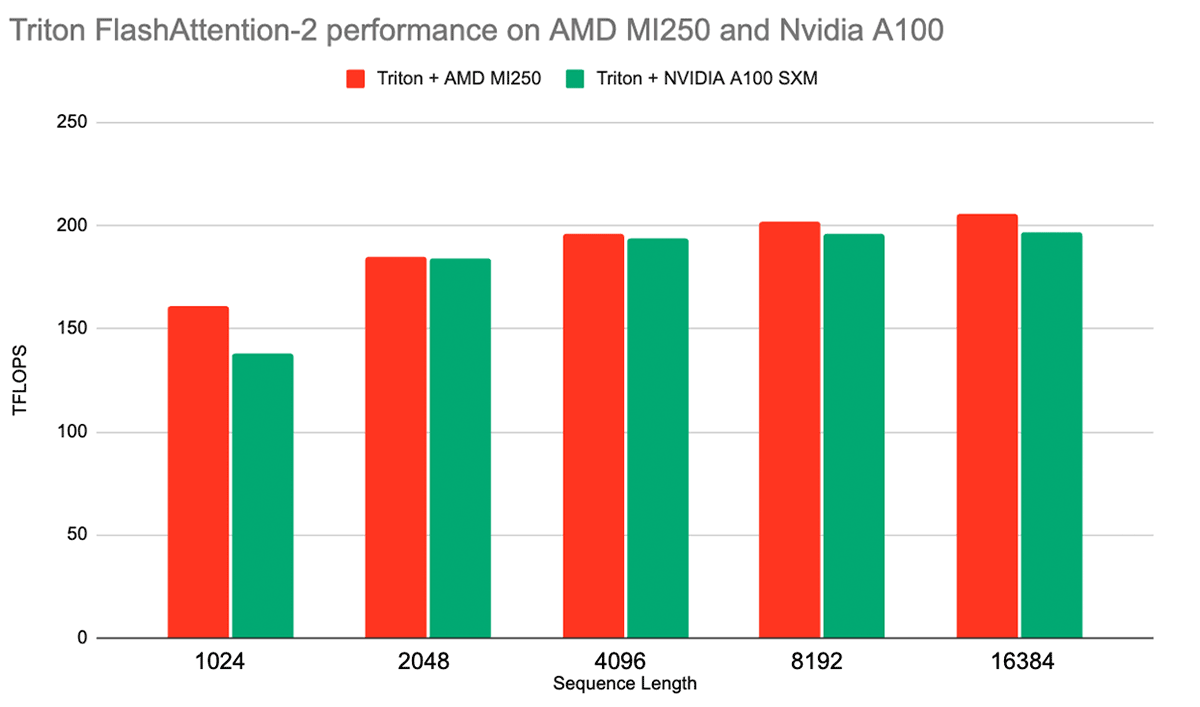
ROCm has seen significant upgrades, progressing from version 5.4 to 5.7. What’s more, the ROCm kernel for FlashAttention has been elevated to FlashAttention-2, delivering substantial performance gains, as Databricks highlighted.
Lamini also says that AMD’s ROCm is production ready and claims that it “has enormous potential to accelerate AI advancement to a similar or even greater degree than CUDA for LLM finetuning and beyond”.
Databricks also applauded AMD’s active involvement in the OpenAI’s Triton compiler. This contribution enables machine learning engineers to develop custom kernels that run efficiently across diverse hardware platforms, including both NVIDIA and AMD systems.
How good is AMD for Databricks
Databricks has achieved a noteworthy 1.13x improvement in training performance when employing ROCm 5.7 and FlashAttention-2 in comparison to previous results with ROCm 5.4 and FlashAttention. Moreover, Databricks demonstrated robust scaling, with performance escalating from 166 TFLOP/s/GPU on a single node to 159 TFLOP/s/GPU on 32 nodes, all while maintaining a consistent global train batch size.
On successful training of MPT models with 1B and 3B parameters from the ground up on 64 x MI250 GPUs, the training process remained stable, and the final models exhibited evaluation metrics on par with renowned open-source models, such as Cerebras-GPT-1.3B and Cerebras-GPT-2.7B.
For training, Databricks capitalised on open-source training libraries like LLM Foundry, built upon Composer, StreamingDataset, and PyTorch FSDP. This was made possible thanks to PyTorch’s support for both CUDA and ROCm, enabling seamless operation on both NVIDIA and AMD GPUs without the need for code modifications.
Databricks says that it is looking ahead with anticipation towards the next-generation AMD Instinct MI300X GPUs, which is expected to launch soon. It expects their PyTorch-based software stack to continue performing seamlessly and scaling effectively.
Moreover, the integration of AMD and Triton is set to simplify the process of porting custom model code and kernels, eliminating the need for ROCm-specific kernels.
Abhi Venigalla, researcher at Databricks said, “The H100 still tops the charts, but we are looking forward to profiling AMD’s new MI300X soon, which we believe will be very competitive!”
Lamini is also eagerly waiting for the launch of MI300X with 192GB of High-Bandwidth Memory (HBM), which will allow its models to run even better.
Conclusively, Databricks’ shift to AMD GPUs signifies a significant stride in the realm of LLM training. This particular development also testifies to AMD’s position, which has been gradually gaining in the GPU space.




































