



|
Listen to this story
|
Researchers from South Korea recently released DarkBERT, a dark web domain-specific language model based on the RoBERTa architecture.

This new model is said to show promising applicability in future research in the dark web domain and in the cyber security industry. It also outperformed existing language models with evaluations on dark web domain tasks and datasets.
But, how did they do it? To allow DarkBERT to adapt well to the language used in the Dark Web, the researchers have pre-trained the model on a large-scale dark web corpus collected by crawling the Tor network. In addition to this, they also polished the pre-training corpus through data filtering and deduplication, alongside data pre-processing to address the potential ethical concerns in Dark Web texts related to sensitive information.
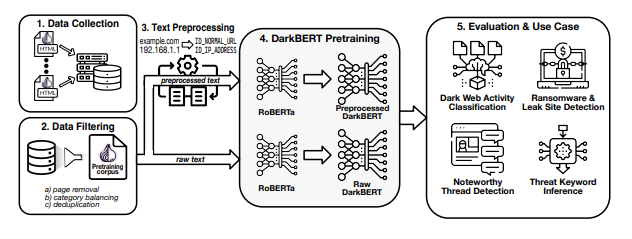
Showcasing DarkBERT pretraining process and the various use case scenarios for evaluation. (Source: arXiv)
The same group of researchers last year worked on ‘Shedding New Light on the Langauge of the Dark Web,’ where they introduced CoDA, a dark web text corpus collected from various onion services divided into topical categories. Another notable study includes – ‘The Language of Legal and Illegal Activity on the Darknet,’ done by Israeli researchers, where they identified several distinguishing factors between legal and illegal texts, taking a variety of approaches. This includes predictive (text classification), and application-based (named entity Wikification), along with an approach based on raw statistics.
All of this research work and more has inspired the researchers to develop DarkBERT.
What next?
In the coming months, the researchers said that they plan to improve the performance of dark web domain-specific pre-trained language models using more latest architectures and crawl additional data to allow the construction of multilingual language models.















































































