



|
Listen to this story
|
Last week, OpenAI held its first-ever developers’ conference in which it announced GPT-4 Turbo, an enhanced iteration of GPT-4. It features an expansive 128k context window, enabling it to process the equivalent of over 300 pages of text in a single prompt.
This upgrade comes with knowledge extending up to April 2023. Several announcements were made, spanning open source models and developer tools, addressing areas where the generative capabilities of OpenAI previously faced competition gaps.
These announcements drew the attention of the AI world as they seemingly sounded the death knell for many AI startups out there.
A week later, however, the hype is on the slide and nothing much has changed. Maybe, GPT-4 Turbo was not as revolutionary as it sounded.
Context Length Extn Issue
In a late July study, Stanford University, UC Berkeley, and Samaya AI researchers revealed a phenomenon in large language models termed ‘Lost in the Middle’, where information retrieval accuracy is high at the document’s start and end but declines in the middle, especially with increased input processing.
Building on this, Greg Kamradt, Shawn Wang, and Jerry Liu tested if GPT-4 Turbo exhibited this effect. Using YC founder Paul Graham’s essays, they inserted a random statement at different document points and evaluated GPT-4’s recall.
Findings showed decreased recall above 73,000 tokens, particularly affecting mid-document statements, emphasizing context length’s impact on accuracy. It means that the accuracy typically drops off as you get to 60-70% of the context length supported by an LLM.
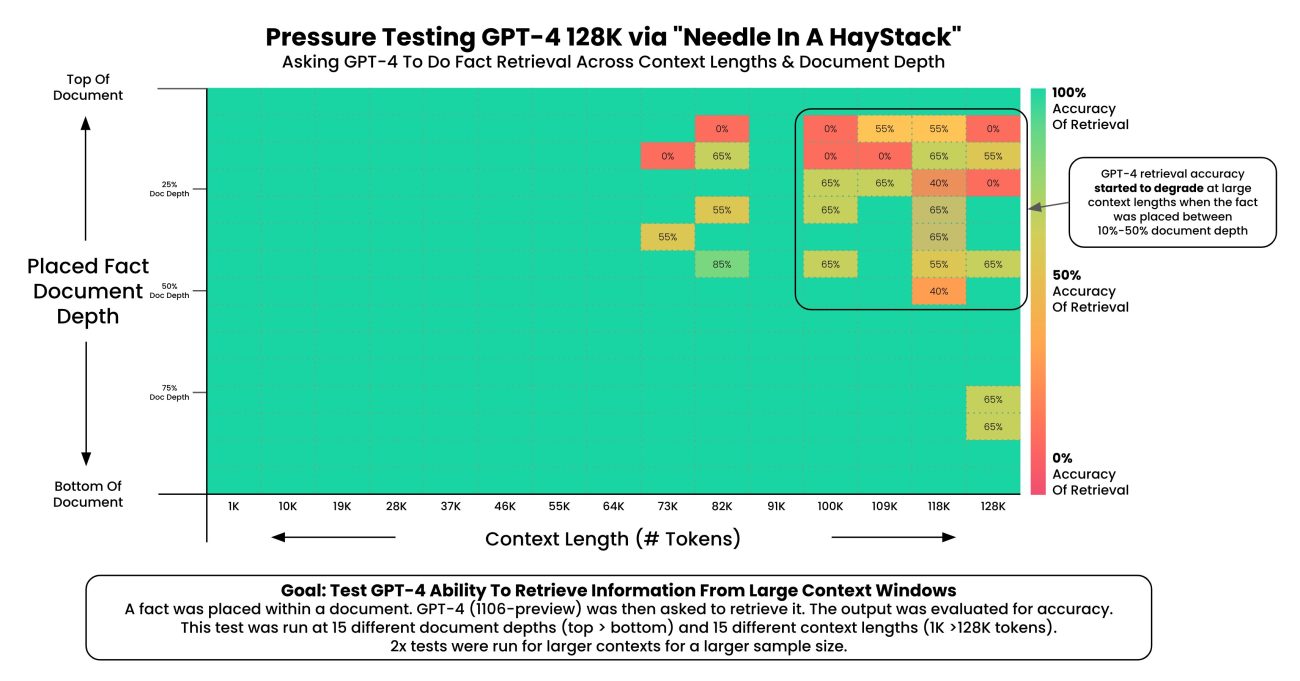
Opting for smaller context-length inputs is recommended for accuracy, even with the advent of long-context LLMs. Notably, facts at the input’s beginning and end are better retained than those in the middle.
Comparatively, a 128K context-length LLM performs better than a 32K context-length one for a given context, suggesting the use of large context-length LLMs with relatively smaller documents. The “forgetting problem” remains a challenge, requiring ongoing development in LLM applications with multiple components and prompt engineering.
While larger context windows, such as those offered by advanced language models like GPT-4, allow for more extensive data processing in a single prompt, embedded search functions or vector databases remain superior in terms of accuracy and cost-effectiveness, particularly for specific information retrieval tasks.
Vector databases specialise in organising and retrieving information based on semantic similarities, offering a more targeted and efficient approach. These systems are designed to excel in precision, ensuring that the retrieved information aligns closely with the user’s query.
Additionally, the focused nature of embedded search functions often results in reduced computational costs, making them an optimal choice for specific and precise data retrieval needs.
OpenAI’s Retrieval APIs Not the Ultimate Solution
While OpenAI’s introduction of retrieval APIs is noteworthy, it’s crucial to highlight the limitation of exclusively working with GPT-4. Despite a price reduction, the scalability of usage remains a significant challenge due to its high cost.
There are open-source retrieval APIs that are revolutionising enterprise LLM adoption.
These APIs come equipped with open-source LLMs tailored for enterprise applications, featuring expansive 32K contexts and specialization in specific enterprise use cases like Q/A and summarization.
The cost-effectiveness of these open-source APIs is noteworthy, being 20 times more economical than GPT-4. Additionally, developers have the flexibility to switch to closed-source LLMs from OpenAI, Anthropic, or Google if that better aligns with their preferences.
Furthermore, if a customized fine-tuned LLM is essential and a developer possesses labeled data, they provide the service of fine-tuning the LLM to meet their specific requirements. In many instances, the combination of Retrieval-Augmented Generation (RAG) with fine-tuning proves to yield optimal results.
In the ever-evolving landscape of an enterprise’s internal knowledge base, the challenge is avoiding the hassle of repeatedly uploading new data each time the database undergoes changes. Typically, enterprise clients store their data in cloud repositories such as Azure, GCP, and S3.
The open-source retrieval APIs facilitate a seamless connection to these cloud buckets, ensuring regular updates without manual intervention. Moreover, this functionality extends to pulling in data from various sources, including Confluence or any cloud database like Snowflake, Databricks, and others, enhancing versatility and adaptability.
While the intricacies are abstracted for a seamless experience, the open-source retrieval API allows users the flexibility to delve into the details and fine-tune parameters as needed. Despite the API’s intelligent approach in making decisions on chunking and embedding strategies based on dataset and API requests, users retain the ability to make manual adjustments.
In the realm of enterprise operations, establishing pipelines and robust monitoring systems is indispensable. Connecting to diverse data sources, ensuring regular updates to vector stores, and meticulous indexing are vital components.
The Retrieval API fundamentally streamlines the development of LLM applications on your data, offering a quick start within a few hours. It emerges as the optimal choice, especially for those emphasising cost-effectiveness and scalability in Retrieval/RAG processes.








































































