



Machine learning algorithms for image processing have evolved at a tremendous pace. They can now help in the reconstruction of objects in ambiguous images, colouring old videos, detecting the depth in moving videos and much more.
One recurring theme in all these machine vision methods is teaching the model to identify patterns in images. The success of these models has a wide range of applications. Training an algorithm to differentiate between apples and oranges can eventually be used in something as grave as a cancer diagnosis or to unlock the hidden links of renaissance art.
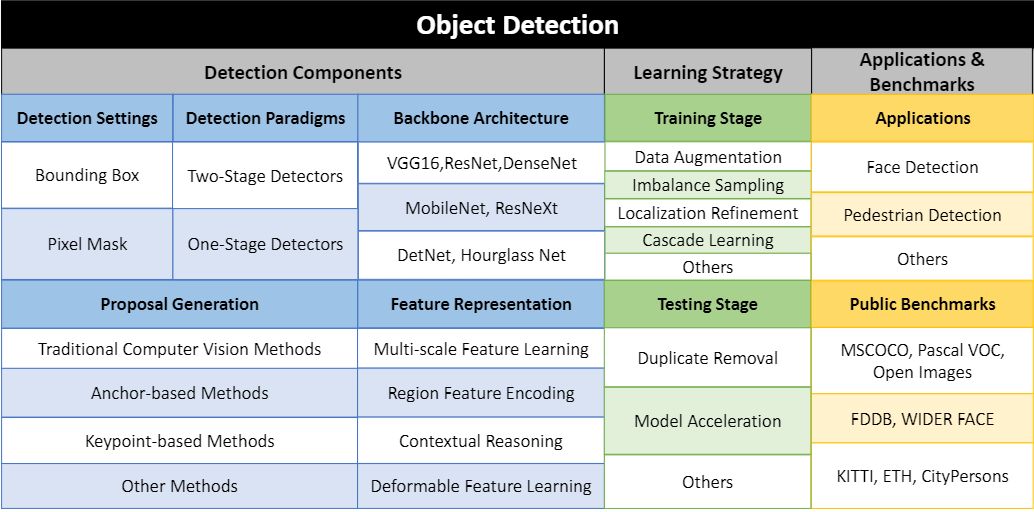
The job of any object detector is to distinguish objects of certain target classes from backgrounds in the image with precise localisation and correct categorical label prediction to each object instance. Bounding boxes or pixel masks are predicted to localise these target object instances.
Due to the tremendous successes of deep learning-based image classification, object detection techniques using deep learning have been actively studied in recent years.
In the early stages, before the deep learning era, the pipeline of object detection was divided into three steps:
- Proposal generation
- Feature vector extraction
- Region classification
Commonly, support vector machines (SVM) were used here due to their good performance on small scale training data. In addition, some classification techniques such as bagging, cascade learning and AdaBoost were used in region classification step, leading to further improvements in detection accuracy.
However, from 2008 to 2012, the progress on Pascal VOC based on these traditional methods had become incremental, with minor gains from building complicated ensemble systems. This showed the limitations of traditional detectors.
After the success of applying deep convolutional neural networks for image classification, object detection also achieved remarkable progress based on deep learning techniques.
Compared to traditional hand-crafted feature descriptors, deep neural networks generate hierarchical features and capture different scale information in different layers, and finally produce robust and discriminative features for classification. utilise the power of transfer learning.
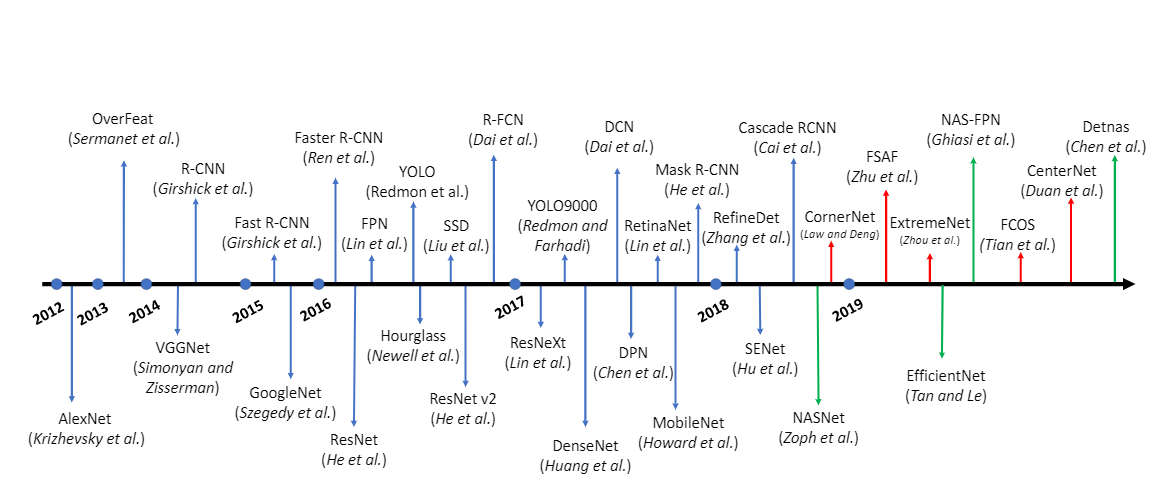
The picture above is an Illustration of Major milestone in object detection research based on deep convolutional neural networks since 2012.
Currently, deep learning-based object detection frameworks can be primarily divided into two families:
- (i) two-stage detectors, such as Region-based CNN (R-CNN) and its variants and
- (ii) one-stage detectors, such as YOLO and its variants.
Evolution Of Two-Stage Detectors
Two-stage detectors commonly achieve better detection performance and report state-of-the-art results on public benchmarks, while one-stage detectors are significantly more time-efficient and have greater applicability to real-time object.
R-CNN is a pioneering two-stage object detector proposed in 2014, which significantly improved the detection performance
R-CNN faces some critical shortcomings. For instance, the features of each proposal were extracted by deep convolutional networks separately (i.e., the computation was not shared), which led to heavily duplicated computations. Thus, R-CNN was extremely time-consuming for training and testing.
Inspired by the idea of spatial pyramid matching (SPM), SPP-net was developed to accelerate R-CNN as well as learn more discriminative features computes the feature map from the whole image using a deep convolutional network and extracts fixed-length feature vectors on the feature map by a Spatial Pyramid Pooling (SPP) layer.
In contrast to RCNN, SPP-layer can also work on images/regions at various scales and aspect ratios without resizing them.
However, the training of SPP-net was still multi-stage and thus it could not be optimised end-to-end and requires extra cache memory to store extracted features.
To address this Fast R-CNN was proposed, a multi-task learning detector which addressed these two limitations of SPP-net. Different from SPP-net, Fast R-CNN used a region of interest (ROI) Pooling layer to extract region features.
In Fast RCNN, the feature extraction, region classification and bounding box regression steps can all be optimised end-to-end, without extra cache space to store features.
Despite the progress in learning detectors, the proposal generation step still relied on traditional methods such as Selective Search or Edge Boxes, which were based on low-level visual cues and could not be learned in a data-driven manner.
To address this issue, Faster R-CNN was developed which relied on a novel proposal generator: Region Proposal Network(RPN). RPN is a fully convolutional network which takes an image of arbitrary size and generates a set of object proposals on each position of the feature map.
Faster R-CNN was able to make predictions at 5FPS on GPU and achieved state-of-the-art results on many public benchmark datasets. Currently, there is a huge number of detector variants based on Faster R-CNN for different usage.
The issue with Faster R-CNN was that it used a single deep layer feature map to make the final prediction. In particular, it was difficult to detect small objects.

Detecting at different scales was addressed by Feature Pyramid Networks(FPN). FPNs achieved significant progress in detecting multi-scale objects and has been widely used in many other domains such as video detection and human pose recognition.
To make the whole process more flexible, Mask R-CNNs were developed, which predicted bounding boxes and segmentation masks in parallel based on the proposals and reported state-of-the-art results
How One Stage Detectors Got Better

Different from two-stage detection algorithms which divide the detection pipeline into two parts: proposal generation and region classification; one-stage detectors do not have a separate stage for proposal generation (or learning a proposal generation).
They typically consider all positions on the image as potential objects and try to classify each region of interest as either background or a target object
First, a real-time detector called YOLO(You Only Look Once) was developed. YOLO considered object detection as a regression problem and spatially divided the whole image into a fixed number of grid cells
However, YOLO could detect up to only two objects at a given location, which made it difficult to detect small objects and crowded objects
In 2016, another one-stage detector Single-Shot Multibox Detector (SSD) was introduced, which addressed the limitations of YOLO.
SSD also divided images into grid cells, but in each grid cell, a set of anchors with multiple scales and aspect-ratios were generated to discretise the output space of bounding boxes (unlike predicting from fixed grid cells adopted in YOLO).
SSD achieved comparable detection accuracy with Faster R-CNN but enjoyed the ability to do real-time inference. The class imbalance between foreground and background is a severe problem in the one-stage detector.
The imbalance problem was tackled with the introduction of RetinaNet. RetinaNet used focal loss which suppressed the gradients of easy negative samples instead of simply discarding them.
Going Beyond Convolutions

The advent of large datasets and compute resources made convolution neural networks (CNNs) the backbone for many computer vision applications. The field of deep learning has in turn largely shifted toward the design of architectures of CNNs for improving the performance on image recognition.
Poor scaling properties in convolutional neural networks (CNNs) make capturing long-range interactions for convolutions challenging, especially with respect to large receptive fields.
In the paper titled Stand-Alone Self-Attention in Vision Models, the authors try to exploit attention models more than as an augmentation to CNNs. They describe a stand-alone self-attention layer that can be used to replace spatial convolutions and build a fully attentional model.
The initial layers of a CNN, sometimes referred to as the stem, plays a critical role in learning local features such as edges, which the later layers use to identify global objects.
Due to input images being large, the stem typically differs from the core block and only focuses on lightweight operations with spatial downsampling.
Selective attentional mechanism tries to ignore irrelevant objects in a scene and spatially-aware attention mechanisms have been used to augment CNN architectures to provide contextual information for improving object detection.
Every improvement in machine vision algorithms also relies on the learning strategies used. There are quite a good number of learning strategies. Here are few:
- Data Augmentation: A more intensive data augmentation strategy is used in one-stage detectors including rotation, random crops, expanding and color jittering.
- Imbalance Sampling: To address difficulty imbalance, most sampling strategies are based on carefully designed loss functions. And, adopt a similar idea from focal loss and propose a novel gradient harmonising mechanism (GHM).
- Cascade Learning: Cascade learning is a coarse-to-fine learning strategy which collects information from the output of the given classifiers to build stronger classifiers in a cascaded manner.
- Adversarial Learning: In this case, the detectors could receive more adversarial examples and thus become more robust. For examples check GANs.
Future Challenges
According to the researchers at Salesforce, the improvement of object detection relies on addressing the following challenges:
- Current anchor priors are mainly manually designed which is difficult to match multi-scale objects and the matching strategy based on IoU is also heuristic.
- Developing anchor-free methods becomes a very hot topic in object detection, and thus designing an efficient and effective proposal generation strategy is potentially a very important research direction in the future.
- Incorporating contexts for object detection effectively can be a promising future direction.
- Batch size is a key factor in DCNN training but has not been well studied in the detection task.
- Making AutoML more affordable.















































































