
India’s Top Ethical AI Advocate: The Journey Of Saishruthi Swaminathan
Saishruthi is an active ethical AI practitioner and advocate based out of California. She has been a one of the top contributors to the field of Ethical AI.


Saishruthi is an active ethical AI practitioner and advocate based out of California. She has been a one of the top contributors to the field of Ethical AI.
Cloud robotics deals with low powered robots that can offload their compute to centralized servers if they are uncertain locally or want to run more accurate, compute-intensive models.
Neural network subspaces contain diverse solutions that can be ensembled, approaching the ensemble performance of independently trained networks without the training cost.

Sanmay has worked with the US Treasury department on machine learning approaches to credit risk analysis, and occasionally consults in the areas of technology and finance.
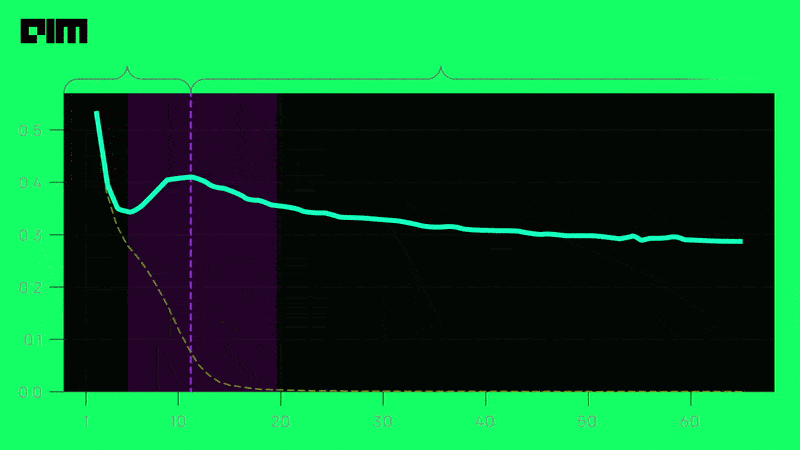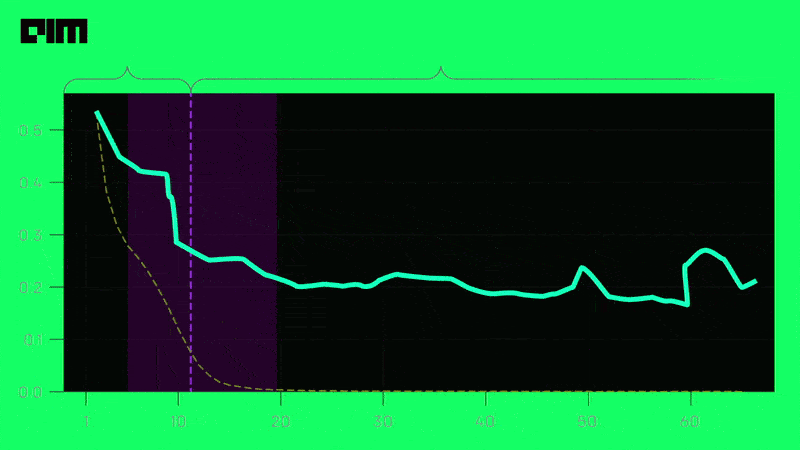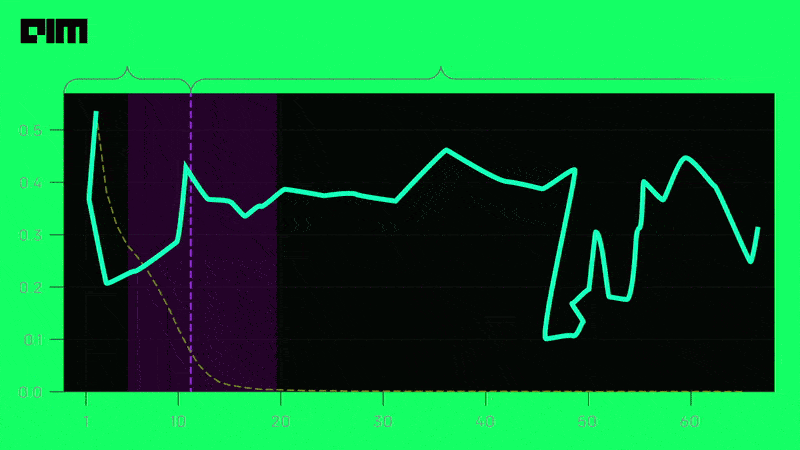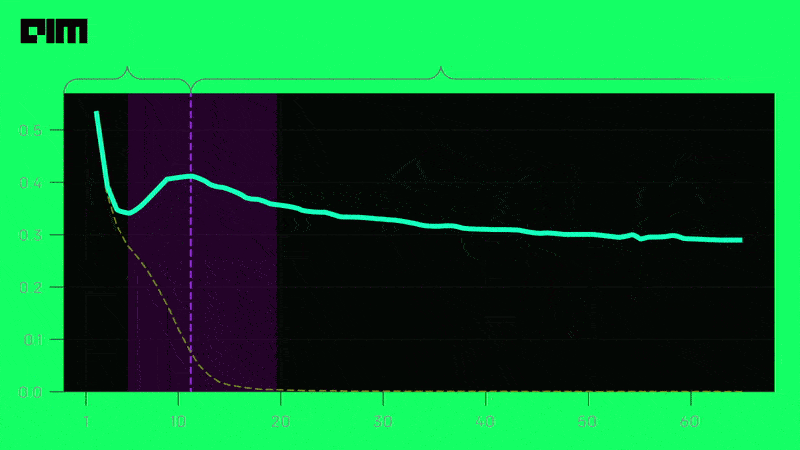
Is it time to bid farewell to bias-variance tradeoff when it comes to machine learning?

We are celebrating three pioneers from different ages whose work laid the foundations for modern day AI.

Matrix multiplication is among the most fundamental and compute-intensive operations in machine learning.

I’m a senior Technical Program Manager(PM) with the Cloud AI services team. I lead teams to build products/solutions for our customers.

Snippet: With increasing size of the language models, the computation complexity increases and Transformers, too, struggle while dealing with long contexts.

Researchers from Mila AI Institute, Quebec, in their survey, have departed from the traditional categorisation of RL exploration methods and given a treatise into RL exploration methods.

VICReg combines the variance term with a decorrelation mechanism based on redundancy reduction and covariance regularisation.

Last month, Apple announced that it will be introducing new child safety features in three areas, developed in collaboration with child safety experts. After backlash

“More than 5,000 organisations worldwide, and over 40% of the Fortune 500 rely on the Databricks Lakehouse Platform.” On Tuesday, the data and AI company

Not Quite My Tempo: Why Should We Care About AI Generated Music?

Today, many big data companies are founded on these open-source projects. But with scale comes cost.
So far, convolutional neural networks (CNNs) have been the de-facto model for visual data.

On Wednesday, the United States President Biden met with private sector and education leaders to discuss the whole-of-nation effort needed to address cybersecurity threats. The

Snippet: Copilot is based on the OpenAI Codex family of models. Codex models begin with a GPT-3 model, and then fine-tune it on code from GitHub.

Sriram Srinivasan who is currently working as a Technical Lead at Google. He primarily works on Optimizing Rewards on Google Pay.

The Weekend Hackathon Edition #2 – The Last Hacker Standing Tea Story challenge concluded successfully on 19 August 2021. The challenge involved creating a time

Deepmind introduced PonderNet, a new algorithm that allows artificial neural networks to learn to think for a while before answering.

Compared to most other machine learning models, foundation models are characterised by a vast increase in training data and complexity

Using CLIP, OpenAI demonstrated that scaling a simple pre-training task is sufficient to achieve competitive zero-shot performance.

Shivam has worked at Uber ATG for close to four and a half years prior to its merger with Aurora. He was part of the team that worked on creating state-of-the-art methods for object detection, tracking and sensor fusion.

Data leakages can increase risks of leaking any type of personal sensitive data that can be traced back to a real individual’s identity.

Federated learning provides a decentralised computation strategy to train a neural model.

The internet as we know today was introduced by Lee in 1991 as part of a project at CERN nuclear facility in Switzerland.

NVIDIA created the Isaac robotics platform, including the Isaac Sim application on the NVIDIA Omniverse platform for simulation and training of robots in virtual environments.

OpenAI’s Triton can hit peak hardware performance with relatively little effort

Federated learning framework offered an elevated level of privacy while maintaining utility of the global model.

Join the forefront of data innovation at the Data Engineering Summit 2024 where industry leaders redefine technology 8217 s future