



In our daily lives, we all either use or give recommendations. In machine learning, the same system is developed that filters out undesired information and provides various outcomes based on different parameters that change from user to user. These recommender systems may be biased or unjust at times while recommending; the bias might be of any type, such as a model bias or data bias. There are several algorithms for determining the fairness of the recommendation system. In this article, we will use RexMex to assess the system’s fairness. Following are the topics to be covered.
Table of contents
- About Recommendation System
- Taxonomy of Fairness
- Evaluating Recommendation System with RexMex
Let’s start by talking about the Recommendation system and the various types of filtering methods used by the system.
About Recommendation System
Machine-learning algorithms are used to determine which items should be recommended to a specific user or customer through a recommendation engine. Based on the principle that patterns can be found in consumer behaviour data, it can collect implicit or explicit information. The types of filters used for these systems could be divided into three groups according to what information needs to be filtered.
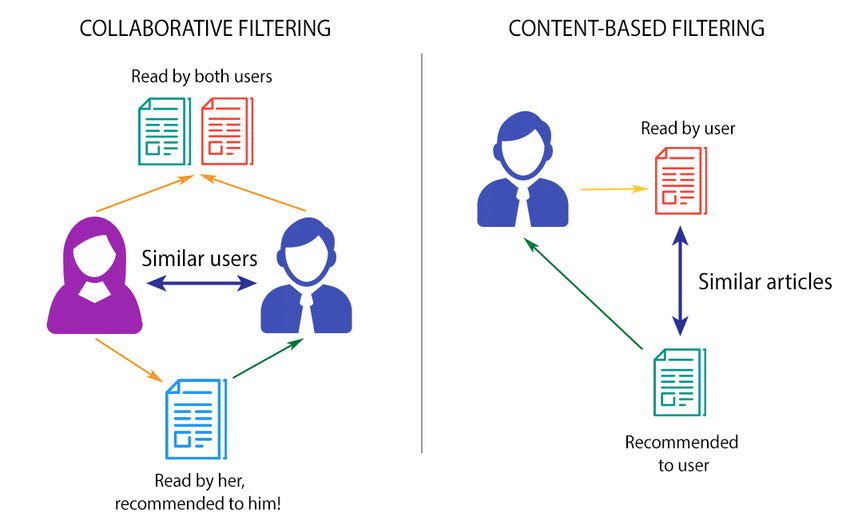
Collaborative filtering
Collaborative filtering is concerned with gathering and analysing data on user behaviour, activities, and preferences to predict what a person will like based on their similarities to other users. It employs a matrix-style formula to plot and calculate these similarities. One advantage of collaborative filtering is that it does not require content analysis or comprehension (products, films, books). It simply chooses which items to recommend based on what it knows about the user.
Content-based filtering
Content-based filtering relies on the assumption that if you like one item, you’ll enjoy this one as well. Algorithms employ cosine and Euclidean distances to calculate the similarity of objects based on a profile of the customer’s interests and a description of the item (genre, product category, colour, word length). The disadvantage of content-based filtering is that it may only propose items or content that are comparable to what the user is already purchasing or using. It is unable to make recommendations for other sorts of items or content. It couldn’t, for example, propose anything other than homeware if the user had only brought homeware.
Hybrid model
A hybrid recommendation engine takes into account both meta (collaborative) and transactional (content-based) data. As a result, it outperforms both. Natural language processing tags may be created for each product or item (movie, music) in a hybrid recommendation engine, and vector equations can be utilised to calculate product similarity. Then, based on the users’ behaviours, activities, and interests, a collaborative filtering matrix may be utilised to propose products to them.
One example of this model, Netflix is the epitome of a hybrid recommendation engine. It considers both the user’s interests (collaborative) and the descriptions or characteristics of the movie or show (content-based).
Are you looking for a complete repository of Python libraries used in data science, check out here.
Taxonomy of Fairness
Individual and Group Fairness
A distance-based approach is one technique to formulate individual fairness. Assume that the distance between two things is indicated by ‘d,’ and the distance between the outputs of an algorithm is denoted by ‘D.’ When two entities are similar, the output of the method should be smaller. The distance D between probability distributions assigned by the classifier should be no larger than the actual distance d between the items in statistics.
To grasp the concept of group fairness, consider two groups: the protected group and the privileged group. The recommender can examine the chances of items from each group appearing incomparably favourable ranking positions, as well as the chances of their being suggested. When the probabilities are equal, individuals of each group have the same probability of obtaining a favourable outcome. This will only occur if members of the non-privileged group are qualified. As a result, if it is not qualified, it will not be suggested.
User and Item Fairness
Item fairness focuses on items that are evaluated or recommended. In this case, rank or recommend similar articles or groups of articles as well. B. It will be displayed in the same position in the ranking. This is the main type of fairness described so far. For example, if a political party considers an article to be a protected attribute, you can request that the value of that attribute not affect the ranking of articles in search results or news feeds.
The user-side fairness is concerned with the users who get or consume data items in a ranking, such as a search result or a suggestion. In general, we want comparable individuals, or groups of people, to receive similar rankings or recommendations. For example, if a user’s gender is a protected characteristic and the user is getting job suggestions, we may request that the user’s gender not impact the job recommendations that the user gets.
Static and Dynamic Fairness
Static fairness does not take into account changes in the recommendation environment, such as changes in item utility or attributes; therefore, dynamic fairness has recently been studied, which takes into account dynamic factors in the environment and learns a strategy that accommodates such dynamics.
Evaluating fairness with RexMex
RexMex is designed with the assumption that end-users might want to use the evaluation metrics and utility functions without using the metric sets and scorecards. Because of this, the evaluation metrics and utility functions (e.g. binarisation and normalisation) can be used independently from the RexMex library.
Let’s start by installing RexMex.
! pip install rexmex
Read dataset and import libraries.
from rexmex import ClassificationMetricSet, DatasetReader, ScoreCard reader = DatasetReader() scores = reader.read_dataset()

Generating evaluation report.
metric_set = ClassificationMetricSet() score_card = ScoreCard(metric_set) report = score_card.generate_report(scores, grouping=["source_group"])

Comparing evaluation scores among specificity, sensitivity and precision for different source groups (0, 1, 2, 3, 4).
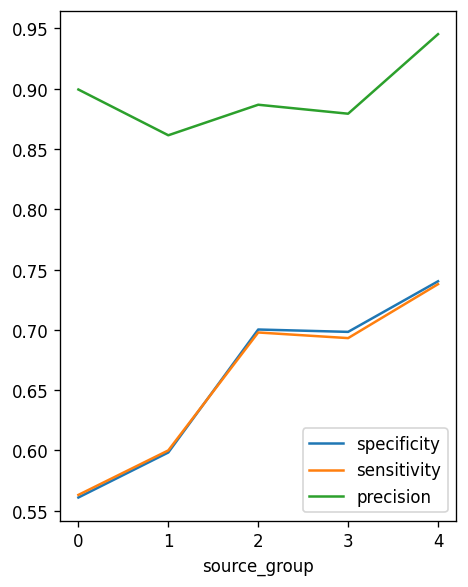
As observed the precision score for group 4 is the highest among the five source groups.
Final words
Algorithms are playing increasingly important decision-making roles in a wide range of social, corporate, and individual applications. As algorithmic decisions become more prevalent in major areas of societal impact, it becomes critical to ensure that they provide some level of fairness and trust, especially when individuals and groups representing minorities or protected classes in terms of gender, race, and so on, are subjected to the negative consequences of algorithmic decisions. With a hands-on implementation of this concept in this article, we could understand how to check the fairness of prediction.












































































