



Dimensionality reduction is one of the important parts of unsupervised learning in data science and machine learning. This part is basically required when the dimensions of the data are very high and we are required to tell the story of the data by projecting it in a lower-dimensional space. There are various techniques for dimensionality reduction like PCA, SVD, truncatedSVD, LDA etc. t-SNA is also a technique for dimensionality reduction. In this article, we are going to discuss the t-SNA. The major points to be discussed in the article are listed below.
Table of contents
- About t-SNE
- How does t-SNE work?
- t-SNE for dimensionality reduction
- Use cases for t-SNE
- Using t-SNE more effectively
Let’s start by introducing t-SNE.
About t-SNE
t-SNE is a technique for dimensional analysis or reduction that is a short form of T-distributed Stochastic Neighbor Embedding. As the name suggests it is a nonlinear dimensionality technique that can be utilized in a scenario where the data is very high dimensional. We can also say this is a technique for visualizing high dimensional data into lower-dimensional space. For the first time, this technique was introduced by Laurens van der Maatens and Geoffrey Hinton in 2008.
Its nonlinearity behaviour against data makes it different from the other techniques. Where techniques such as PCA are the linear algorithms for dimensional reduction and preserve large pairwise distance that can lead to poor visualization of high dimensional data, the t-SNE works better than PCA by preserving small pairwise distance.
Are you looking for a complete repository of Python libraries used in data science, check out here.
How does t-SNE work?
As above mentioned it is a technique for visualizing the high dimensional data or we can say a technique for dimensionality reduction. This technique works by converting high dimensional data points to joint probabilities and uses these probabilities to minimize the Kullback-Leibler divergence so that low dimensional embeddings can be obtained. The cost function that this technique uses has a non-convex cost function which means every time we apply it we can get a different result. The proper working of t-SNE can be understood using the following steps:
- Firstly the algorithm of this technique first calculates the joint probabilities between the data points that represent the similarity between points.
- After the calculation of joint probability, it assigns the similarity between the data points on the basis of the calculated joint probability.
- After assigning the similarity, t-SNE represents the data points on lower dimensions on the basis of probability distribution until the minimum Kullback-Leibler divergence.
Kullback-Leibler divergence can be considered as a statistical distance where it represents the calculation of how one probability distribution is different from the other one.
t-SNE for dimensionality reduction
In this section, we are going to look at how we can use the t-SNE practically for dimensionality reduction through implementation in python. Before implementation, we are required to know that sklearn is a library that provides the function for implementing t-SNE under the manifold package. Let’s take a look at the simple implementation.
Let’s define random data using NumPy.
import numpy as np
X = np.array([[0, 0, 0], [0, 1, 1], [1, 0, 1], [1, 1, 1]])
X.shape
Output:

Here we can see the shape of the array that we have defined. Let’s apply the t-SNE on the array.
from sklearn.manifold import TSNE
t_sne = TSNE(n_components=2, learning_rate='auto',init='random')
X_embedded= t_sne.fit_transform(X)
X_embedded.shape
Output:
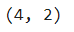
Here we can see that we have changed the shape of the defined array which means the dimension of the array is reduced. Let’s discuss places where we can be applying t-SNE with our data.
Use cases for t-SNE
In the above section, we have looked at the basic implementation and the working of the t-SNE and by looking at these things we can say that the t-SNE can be applied with very high dimensional data. Although the developer of the t-SNE has mentioned it uses cases in the fields like climate research, computer security, bioinformatics, cancer research, etc. after applying this technique we can use its outcome in different supervised modelling processes.
We can also use this method for clustering or separation of the data. In a variety of modelling procedures, we generally apply models to the separated data to get higher results. However, it is not a proper clustering algorithm or technique. This can also be applied to the fields where data exploration is required using the visualization of the data. Let’s take a look at the ways using which we can make the t-SNE more effective.
Using t-SNE more effectively
- Since we use this technique to analyze the high dimensional data we’re required to make sure that we are applying t-SNE iteratively using the different parameter values to reach a proper result.
- There is a use of a non-convex cost function in t-SNE and it is a stochastic process using it in iteration may represent changes in the outcome that can be solved by fixing the random state parameter.
- t-SNE is an algorithm that can also shrink sparse data and amplify non-sparse data. To apply the algorithm it is very necessary to fix the parameters of density/spread/variance before applying it.
- Perplexity is a parameter given under the t-SNE that relates to the number of neighbours and with the larger dataset, it is required to set a larger perplexity.
Final words
In this article, we have discussed the t-SNE(T-distributed Stochastic Neighbor Embedding) which is a technique used for dimensionality reduction. Along with this we also discuss the working, implementation and use cases of the t-SNE which is a nonlinear dimensionality reduction technique.















































































