



|
Listen to this story
|
Since Stable Diffusion got open-sourced, a lot of new innovations are coming to the surface. The newest one is for creating real-time AI generated music—Riffusion. Taking an interesting approach for creating music using images of audio instead of audio, Riffusion is built by fine-tuning Stable Diffusion to create images of spectrograms—essentially, visualisations of audio.
The model can generate infinite variations of a text prompt or an uploaded sound clip which can also be modified by entering further prompts.
Click here to try it out.
You can check out the code of the model here.
Read: Meet the Hot Cousin of Stable Diffusion, ‘Unstable Diffusion’
Process and Features
Spectrograms are visual representations of audio that display the amplitude of frequencies over time. These generated visuals can then be converted into audio clips. The spectrogram is computed from audio with Short-time Fourier Transform (STFT), approximating audio using a combination of sine waves that have varying amplitudes and phases.
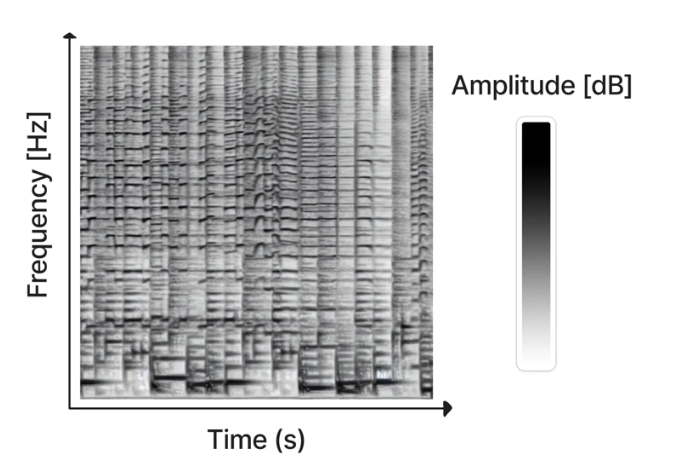
Apart from text-to-audio, Stable Diffusion-based models can also leverage image-to-image ability. This was useful for modifying sounds by making changes to the image while also preserving the original content of the audio using the de-noising strength parameter.
For creating infinite varying AI-generated music, the developers interpolated between prompts and seeds using the latent space present in diffusion models. Latent space consists of objects that are similar to each other, allowing buttery smooth transitions even with disparate prompts.
In September, a similar model built on Stable Diffusion, Dance Diffusion, was released and could generate music clips. It was trained on hundreds of hours of songs and was therefore considered as a borderline ethical choice for Stability AI.









































































