



E-commerce websites generate large amounts of textual data. These firms hire data science professionals to refine this unstructured data and gather meaningful insights from it that can help in understanding the end-user in a better way. For example, by analyzing product reviews, Flipkart can understand the insights of the product, Netflix can find users’ likeness on their content and we can’t imagine doing this analysis will happen without Text analytics.
Topics we cover in this article:
- How to Extract Product reviews from Flipkart website
- Preprocessing of the Extracted reviews
- Extracting and Analyzing Positive reviews
- Extracting and Negative reviews
In this article, we will extract the reviews of Macbook air laptop from the Flipkart website and perform text analysis.
Hands-on implementation of Flipkart review scarping
#Importing required libraries import requests from bs4 import BeautifulSoup as bs import re import nltk import matplotlib.pyplot as plt from wordcloud import WordCloud import os
Extracting reviews from Flipkart for MacBook Air
Here we are going to extract reviews of Macbook air laptops from the URL.

#Scraping review using beautifulsoup macbook_reviews=[] for i in range(1,30): mac=[] url="https://www.flipkart.com/apple-macbook-air-core-i5-5th-gen-8-gb-128-gb-ssd-mac-os-sierra-mqd32hn-a-a1466/product-reviews/itmevcpqqhf6azn3?pid=COMEVCPQBXBDFJ8C&page="+str(i) response = requests.get(url) soup = bs(response.content,"html.parser")# creating soup object to iterate over the extracted content reviews = soup.findAll("div",attrs={"class","qwjRop"})# Extracting the content under specific tags for i in range(len(reviews)): mac.append(reviews[i].text) macbook_reviews=macbook_reviews+mac #here we saving the extracted data with open("macbook.txt","w",encoding='utf8') as output: output.write(str(macbook_reviews))
Until here we extracted reviews from the website and stored them in a file named macbook_reviews.
Preprocessing
The extracted product reviews include unwanted characters like spaces, capital letters, symbols, smiley emojis. We don’t want to include those unwanted characters in text analysis, so in preprocessing we need to clean the data by removing unwanted characters.
os.getcwd() os.chdir("/content/chider") # Joining all the reviews into single paragraph mac_rev_string = " ".join(macbook_reviews) # Removing unwanted symbols incase if exists mac_rev_string = re.sub("[^A-Za-z" "]+"," ",mac_rev_string).lower() mac_rev_string = re.sub("[0-9" "]+"," ",mac_rev_string) #here we are splitting the words as individual string mac_reviews_words = mac_rev_string.split(" ") #removing the stop words #stop_words = stopwords('english')
In the below code snippet, we will gather the words from the reviews and display it using the word cloud
with open("/content/stop.txt","r") as sw: stopwords = sw.read() temp = ["this","is","awsome","Data","Science"] [i for i in temp if i not in "is"] mac_reviews_words = [w for w in mac_reviews_words if not w in stopwords] mac_rev_string = " ".join(mac_reviews_words) #creating word cloud for all words wordcloud_mac = WordCloud( background_color='black', width=1800, height=1400 ).generate(mac_rev_string) plt.imshow(wordcloud_mac)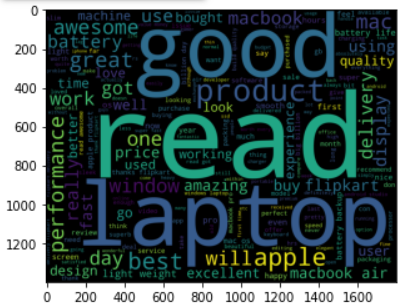
From word cloud output the words like good, read, the laptop appears in the bigger size that illustrates these words are repeated more times in the MacBook air reviews. By observing this word cloud, we can see the highlighted words like performance, battery, delivery, the laptop, we can’t conclude how the battery works and, how it performs, to get insights from this output we need to divide this into a positive and negative word cloud.
In the below code snippet we will extract Positive words from product reviews
with open("/content/positive-words.txt","r") as pos: poswords = pos.read().split("\n") poswords = poswords[36:] mac_pos_in_pos = " ".join ([w for w in mac_reviews_words if w in poswords]) wordcloud_pos_in_pos = WordCloud( background_color='black', width=1800, height=1400 ).generate(mac_pos_in_pos) plt.imshow(wordcloud_pos_in_pos) #here we get wordcloud of all postive words in reviews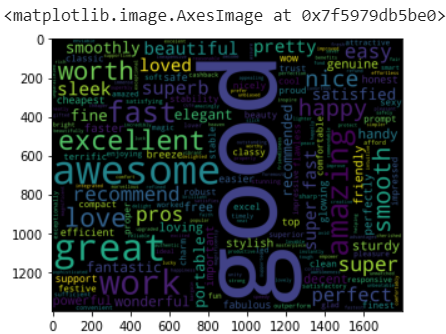
Here, through this positive word cloud, we can get some insights like the product was good, smooth, fast, awesome product, recommend to others, portable to use, beautiful product, these are the positive insights from the MacBook air product.
In the below code snippet we will extract Negative words from product reviews
with open("/content/negative-words.txt","r",encoding = "ISO-8859-1") as neg: negwords = neg.read().split("\n") negwords = negwords[37:] # negative word cloud # Choosing the only words which are present in negwords mac_neg_in_neg = " ".join ([w for w in mac_reviews_words if w in negwords]) wordcloud_neg_in_neg = WordCloud( background_color='black', width=1800, height=1400 ).generate(mac_neg_in_neg) plt.imshow(wordcloud_neg_in_neg) #here we are getting the most repeated negative Wordcloud
Now through this negative word cloud, we can illustrate that the product was lag, slow, crashed, we have issues in the product, it was so expensive, pathetic.
Conclusion
By analyzing the product reviews using text mining we gathered most appeared positive and negative words using the word clouds. We can conclude that text mining gains insights into customer sentiment and can help companies in addressing the problems. This technique provides an opportunity to improve the overall customer experience which returns huge profits.















































































