



In recent years, we have seen the success of transformers in every field of machine learning and data science. This effect of the transformer can also be seen in computer vision. But the only problem with the transformers is that they are highly weighted and complex in terms of computation architecture. MetaFormer is one of the solutions to this problem. In this article, we will discuss MetaFormer with examples of how it can be applied to computer vision. We will also understand one of its sub-models, named as PoolFormer in detail. The Major points to be discussed in this article are listed below.
Table of Contents
- What is MetaFormer?
- The method used for MetaFormer
- What is PoolFormer?
- PoolFormer’s Performance in Different Tasks
What is MetaFormer?
MetaFormer can be considered as a kind of model architecture that is abstracted from transformers where the token mixer module is not defined and replaces the token mixer with attention or spatial MLP. We can think of MetaFormer as the transformer/MLP-like model. We can find in many pieces of research that in computer vision using a transformer without specifying a token mixer module is more fruitful and essential for model performance.
For example, these attention token mixtures can be replaced with a simple spatial pooling operator to perform basic token mixing. We can also make this procedure work with transformers in computer vision tasks like ImageNet-1k and DieT-B/ResMLP-B24. So this is a general concept of MetaFormer, where abstracted architecture from transformers is not required to specify a token mixture module.
It can be a key player in the computer vision process to achieve noticeable higher performance. Here we can say we don’t need to provide focus on the token-mixture module. In the next parts of this article, we are going to discuss MetaFormer in detail before going for an example. Let’s have a look at the method which can be used for MetaFormer in the next section of the article.
The Method used for MetaFormer
As we have discussed in the above section, we can make a transformer work high performing without specifying token mixture and keeping the other components the same as in the transformer. Let’s take an example of ViT transformer, where It is the proposed input embedding as patch embedding:
X = InputEmb(I),
Where X is an embedding token of embedding dimensions C and sequence length of N. Now the embedding tokens can be fed to MetaFormer blocks where each block includes two sub-blocks. The first block can be represented as
Y = TokenMixer(Norm(X)) + X,
The work of the first block is to communicate information among tokens using a token mixture. Where in the above representation,
Norm = normalization (layer or batch normalization), and
TokenMixture = module for mixing tokens.
The main function of any token mixture in any transformer is to propagate information. Now the second sub-block can consist of an MLP with non-linear activation. There can be two layers in the MLP. Representation of the second sub-block can be as follows:
Z = σ(Norm(Y)W1)W2 + Y,
Where W1 and W2 are learnable parameters of MLP. After this, we are not required to specify the token mixture. The below image is a representation of the comparative architecture of MetaFormer with other transformer and MLP-like models.
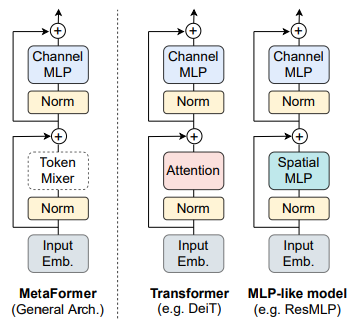
Hereby above, we can understand the basic difference between MetaFormers and transformer or MLP-like models. Now let’s take a look at an example of MetaFormer. In This article, we will be using the PoolFormer as an example of MetaFormer.
What is PoolFormer?
We have discussed how the design of transformers is focused on employing attention-based taken mixture. Here the PoolFormer, a model derived from MetaFormer for computer vision, is a work that focuses on employing the general architecture like MetaFormer.
The architecture of the PoolFormer is contributing most to the success of the recent transformer and MLP-like models. To make it high-performing, the researchers of the PoolFormer have deliberately applied a simple pooling operator in the place of the token mixture. Where the working of a pooling operator is to make a token to be averagely aggregated to its nearby token instead of mixing the information. Also, this MetaFormer is only focused on the computer vision task and this becomes the reason for input to be in channel first format.
In the PoolFormer the pooling operator has no learnable parameter and can be expressed as:
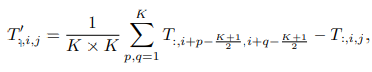
Where,
T = Tokens, and
K = pooling size.
It is just like other normal pooling actions which make the network calculation easier. In most cases, we see that a normal neural network has high computational complexity and a high number of learnable parameters where pooling becomes very easy in computation with no learnable parameters. This is the advantage of using a pooling operator instead of any network on it. The below image is a representation of the architecture of PoolFormer.
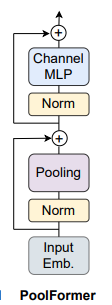
When we talk about the workflow of the PoolFormer, we can represent it using the below image.

The above image is a representation of the overall framework with PoolFormer blocks. It seems like the architecture of CNN models. This framework has 4 stages with H/4 x W/4, H/8 x W/8, H/16 x W/16 and H/32 x W/32 tokens respectively. (H and W are the height and width of the input images).
The MLP expansion ratio is set as 4 for now and According to the above model scaling, we can obtain 5 different model sizes of PoolFormer and their hyperparameters can be as follows:

Here we have seen how the pool former works behind, now we have some of the results of the PoolFormer on different datasets that can help us in defining whether the PoolFormer is working in a competitive nature or not.
PoolFormer’s Performance in Different Tasks
In computer vision, we see various datasets that can be used for checking the performance of any model for any specific task. In this section of the article, we will see the performance of PoolFormer in tasks like image classification, object detection, and semantic segmentation.
Image Classification
For image classification tasks one of the landmark datasets is ImageNet- 1k dataset which can also be used for various computer vision tasks. In the dataset we have 1.3 million training samples and 50,000 validation images, covering 1000 common classes. The below table is a representation of the PoolFormer in the ImageNet classification dataset.

Here in the table, we can see the comparative performance levels of the PoolFormer and other models and by seeing the accuracy reports on the validation set we can say that PoolFormer can achieve a competitive performance with CNN and other MetaFormer-like models. Let’s see the performance of the object detection procedure.
Object Detection
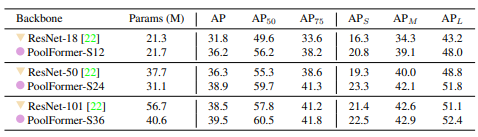
For object detection, there is a landmark dataset named COCO. The dataset includes 118 training samples and 5k validation samples. The below table is a representation of the performance level of PoolFormer and ResNet models on the COCO dataset for object detection.
Semantic Segmentation
Dataset ADE20K is a landmark dataset for semantic segmentation that includes 20,000 images in its training set and 2000 images in the validation set while covering 150 semantic categories. The below table is a representation of the performance level of models ResNet and ResNeXt that are CNN-Based, PVT that is transformer-based, and PoolFormer.
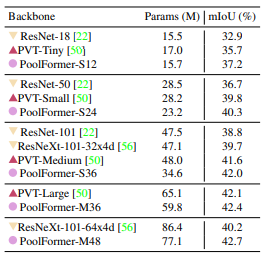
Here we can see that PoolFormer-12 achieves mIoU of 37.1, 4.3, and 1.5 better than ResNet-18 and PVT-Tiny, respectively.
Here we have seen the performance level of PoolFormer in various computer vision tasks, by looking at the results we can say that the MetaFormers are equivalent to the other transformers. In the case of computer vision, we can use them for these tasks. Github repository comprising more details of PoolFormer can be found here.
Final Words
Here in the article, we have discussed the intuition behind MetaFormers and how it solves the computational complexity of the transformer. Along with that, we have discussed the basic method which can be followed for MetaFormer. We also discussed an example of MetaFormers in the computer vision field and compared the performance level based on different computer vision tasks with other transformer and MetaFormer-like models.
Reference















































































