Interest in deep learning is at an all-time high what with breakthroughs in areas of computer vision, speech recognition, language translation and most importantly pattern recognition in large datasets. However, despite recent advances in mission critical field such as autonomous driving where driverless cars require lightning-fast deep learning inference, usually within tens of milliseconds for each sample (inference is the AI lexicon for applying capability to new data), researchers are still shining a spotlight on challenges such as:
- Dealing with insufficient labeled training data
- Learning with less data
- Dealing with incremental data
While the prospect of using deep learning in challenging domains such as medical imaging improves, DL researchers are still grappling with the problems of continuous training in production systems. In this article, we will talk about recent trends and methods shaping research in deep neural networks which will offer a good starting point to readers.
Before we dive into the techniques, let’s talk about some of the challenges. First up is the problem of dealing with less data and insufficient labeled training data. Of late, researchers are pretraining state-of-the-art Deep Neural Networks (DNN) on large general-purpose data sets like ImageNet, and then fine-tuning the model on a smaller data set of interest. This helps tackle the problem of insufficient labeled training data for especially for areas such as medical diagnosis where obtaining labeled data is extremely cost and time -intensive.
According to Parth Shrivastava, Head of Digital Marketing at Parallel Dots, though AI is gaining traction in the market, AI capabilities are still falling short of fulfilling real-world problems. Citing a use case, he noted in a post: for example, in the case of image classification, most people would think it is a solved problem. We can classify images for example, into cat images or dog images matching human accuracy. But if one feeds the algorithm an image of a dog of rare breed, it will find it difficult to classify it as a dog. Interestingly, the startup is using most of these techniques to improve output.

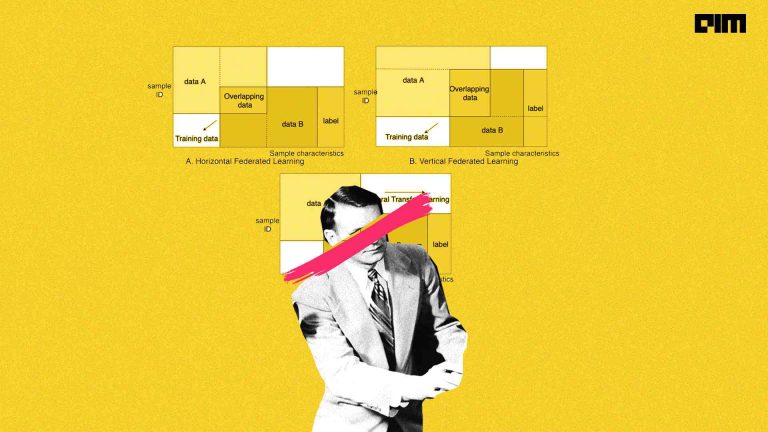
As Deep Learning marches into relatively tough domains, there is the problem of dealing with incremental learning – adjusting the ratio of old and new data, wherein new labels are added incrementally without disturbing previous training. For example, let’s say one wants to do incremental training of a CNN model as new classes are added to the existing data. The CNN model is initially trained for classifying, 500 classes with 1 million images. But with the availability of new data, there are 50 new classes with 10000 images in addition to the previous of 500 classes. It’s here that Transfer Learning techniques comes into play — models trained on one task capture relations in the data type and are repurposed for different problems in the same domain. Also, do check out the Microsoft Research paper that talks about incremental learning.
In this article, we list down emerging techniques that are reengineering AI research:
1.Transfer Learning: According to startup founder Sarthak Jain, in transfer learning, developers can work on a pretrained model, that was initially trained on a large dataset. In other words, the model was trained on a different task, with the same input but different output. He further explains how one should find layers which output reusable features and use the output of that layer as input features to train a small network that requires a smaller number of parameters. It is on the basis of the small network that one can learn the relations for the specific problem after gleaning the patterns in the data from the pretrained model. Transfer Learning helps scale AI solution with lesser quantity of data.
Known Use Cases: In fact, Mountain View search giant Google’s “Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy” is an example of transfer learning, applied to real-world image dataset.
2.Adversarial Learning: According to influential AI research scientist Ian Goodfellow, until recently, even an input could trick an object recognition model. Today, Goodfellow notes that object recognition algorithms have reached near human accuracy but fail to perform on unnatural inputs. Adversarial Learning sprung from Goodfellow’s research and he is also credited for coming up with the new framework — Generative Adversarial Nets. Inspired by game theory, this framework presents two algorithms, a generator and a discriminator, trying to trick the other during fool each other while they are training. Here’s the definition by Goodfellow: Adversarial examples are synthetic examples constructed by modifying real examples slightly in order to make a classifier believe they belong to the wrong class with high confidence.
Known Use Cases: Interestingly, researchers at University of Michigan and Max Planck Institute have come up with a paper on creating images from text – in other words text to image synthesis. Its real-world application would be a software probably like Adobe Photoshop that allows one to create new objects from text instructions. According to Goodfellow, Adversarial Learning give us some traction on safety in AI and can be deployed to prevent avoid potential security problems.
3. Multi Modal Multi Task Learning: Did you hear about Google’s neural network that is a multi-tasking pro. The search giant recently came up with a multi-tasking machine learning system called MultiModal that learnt how to detect objects in images, recognize speech and even translate between four pairs of languages besides parsing grammar – all this simultaneously. According to the company blog, this neural network architecture draws from the success of vision, language and audio networks to simultaneously solve a number of problems across multiple domains, such as image recognition, translation and speech recognition.
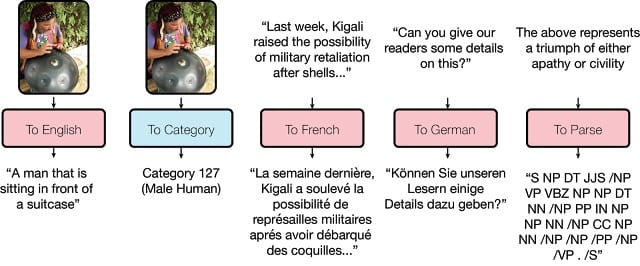
Known Use Cases: Well, Google’s Multilingual Neural Machine Translation System used in Google Translate, works on this approach an MultiModel and is a first step towards the convergence of vision, audio and language understanding into a single network.
4. Few Shot Learning: Used in image recognition, this technique is used when the number of categories is large and the number of examples per novel category is very limited, e.g. 1, 2, or 3, states the recently released paper on Few-Shot Image Recognition. This paper dealt with a new method wherein a pre-trained neural network can be adapted to new categories by directly predicting the parameters from the activations. Zero training is required in adaptation to novel categories, and fast inference is realized by a single forward pass.
Known Use Cases: AI researchers believe this technique is limited in terms of applicability, given the lack of large training data. Since the paper was tested on ImageNet database, these models have good image descriptors.