



|
Listen to this story
|
Chinchilla, the 70 billion-parameter model released by DeepMind in mid-April this year solidified certain assumptions about scaling large language models. The performance of LLMs was restricted by the amount of data a model was being trained on and not the size of the model — the comparatively smaller model proved that returns on additional data were huge while returns on additional model size was very little. The research around Chinchilla also demonstrated that the entire quantity of data available on specialised domains like coding was tiny as compared to the potential improvement only if more data was available. Even with all this data floating around, are we really running out of data?
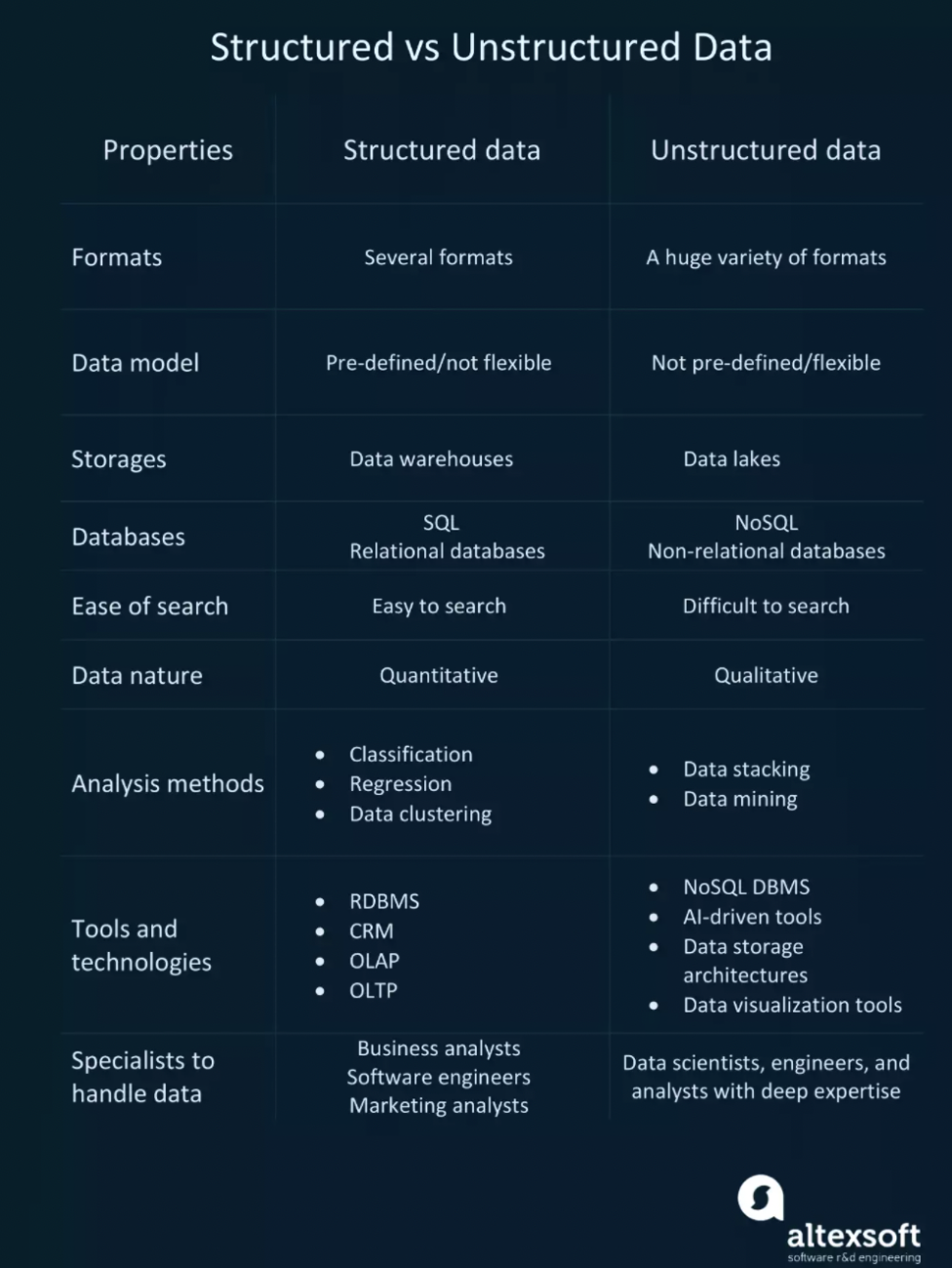
Structured data vs unstructured data
Most of these benchmark LLMs extracted huge amounts of data the one way it found easiest – web scraping. Data is usually picked up from a wide range of sources like public forums, tutorials, Wikipedia, English web documents, Q&A sites on programming and non-English web documents. This type of data is as myriad in its nature as can be – a lot of it also contains garbage which has to be aggressively filtered out. It’s easy to understand why this type of data is known as unstructured. It isn’t organised in a table on a relational database, it includes images, videos, text, audio, tagged formats like XML, HTML or JSON.


Important models like GPT, GPT-2, GPT-3 all have relied on raw data like this. DeepMind’s Gopher and Chinchilla use a dataset called MassiveText and the web scrape portion of the dataset is called the 506 billion token-MassiveWeb. Google AI’s PaLM uses a much smaller and more filtered web corpus of 143 billion tokens. But as the thirst for data amplifies, has AI modelling left behind a huge section of structured data?
Structured data is trapped within business applications like product repositories, transaction logs, Enterprise Resource Planning or ERP and Customer Relationship Management or CRM systems. Because model training has been hyperfocused on using unstructured data, the methods of processing tabular are still stuck in an erstwhile era. Older generations of data science techniques like rule-based systems or decision trees which are handcrafted features and difficult to maintain and require a lot of manually labelled data, are still used.

Why was structured data left behind?
Besides there is an existing notion that structured data is simply too ancient to be paired with deep learning techniques. For most experts combining a data paradigm like structured data that is 40 years old with something as new as deep learning is regressive.
As deep learning grew more popular, structured data was left for the dead. Structured datasets are simply considered too small to feed deep learning methods, especially when compared with the variety of data that unstructured datasets pull up. The objection to this can be that there are possibly huge labelled structured datasets which contain tens or thousands or even millions of examples but the time and efforts made to process these will also be immense.
While structured data is arranged in columns that contain numeric values like currency, temperature, time or other values along with non-numeric values, it can also be unstructured. Structured datasets can also include unstructured values like freeform text or references to XML documents etc.
On the other hand, unstructured data itself ironically doesn’t necessarily have zero structure. Value pairs in JSON are also a type of structure but it is still considered as unstructured because JSON values in their native state cannot be in a tabular form.
The other argument against structured data is that because of how popular deep learning has become, it has also been simplified, the relevant tools for it are much easier to use. Deep learning solutions can also be used by nonspecialists like the fast.ai library which allows novices to build deep learning models with just a few lines of code. Or even data science platforms like Watson Studio, which has model-builders without any coding. This is why structured data makes more sense for non-deep learning machine learning methods or traditional business intelligence applications in enterprises.
Need still remains
But as the incremental benefits of LLMs are running out of steam, researchers are realising that the only way to compensate for the continued dearth in data is by turning to structured datasets. Emad Mostaque, founder and CEO of text-to-image generative AI startup Stability.AI spoke about the need for more data, tweeting that our approach towards general artificial intelligence has to change for maximum impact. To help AI models reach out to as many folk as possible, researchers need to include more diverse highly structured datasets. “Stacking more layers is fine as GPT-4 is about to show but there are superior routes,” he stated.






































































