


|
Listen to this story
|
Tabular data, commonly found in spreadsheets and databases, constitutes the backbone of decision-making in various industries, and most importantly, in machine learning. For these tasks, the primary requirement is a model that can handle tabular data efficiently, accurately, and interpretably. Arguably, XGBoost (Extreme Gradient Boosting) excels on all fronts, amid all the hype around other deep learning techniques, even LLMs.
XGBoost pic.twitter.com/V7BdVyE4Aw
— Bojan Tunguz (@tunguz) October 2, 2022
Bojan Tunguz, the quadruple Kaggle grandmaster who works at NVIDIA, states that XGBoost is all you need. But is it really true that XGBoost can be continually touted as the best low-code ML solution available today? Even beating out LLMs in terms of classification capabilities on tabular data?
Transformer is NOT all you need, only a little bit
Traditionally, there have been two distinct groups in the ML ecosystem: the tabular-data-focused data scientists that use XGBoost, lightBGM, and similar tools, and the LLM group. These both groups have used separate techniques and models. However, recent experiments have shown that LLMs can be applied effectively for classification on tabular data without extensive data cleaning or feature engineering, but the capabilities are still time consuming.
To apply LLMs to tabular data, prompt engineering can be one of the helpful solutions, but it is still in infancy. The LLMs produce textual output, but the focus here is on using the internal embeddings (latent structure embeddings) generated by LLMs, which can be passed to traditional tabular models like XGBoost. While Transformers have undoubtedly revolutionised generative AI, their strengths lie in unstructured data, sequential data, and tasks that involve complex patterns.
For example, in Kaggle competitions, where tabular data dominates, LLMs, when provided with appropriate prompts, demonstrated predictive power, though not at the level of top-performing traditional models like XGBoost. This suggests the potential for LLMs to become valuable tools in tabular data analysis is still under development, reigning XGBoost extreme.
But the case is limited to smaller datasets only, and stops when the size increases. To build LLMs, we need a corpus of data. On the other hand, Kaggle competitions have some megabytes or a few gigabytes of data, where it performs well. But as the size increases, Transformers prove to be the better option.
Krishna Rastogi, CTO of MachineHack said, “Transformers are like the H-bombs of machine learning, and XGBoost is the reliable sniper rifle. When it comes to tabular data, XGBoost proves to be the sharpshooter of choice.”
He further explains that most MachineHackers also use XGBoost or CATBoost, but it’s because it works well in general for competitions. “But I believe the real world data is more messy and requires a whole level of data cleaning, checking duplicate, good and bad labelling, this is where Transformers outperform,” he added.
Why and when to XGBoost
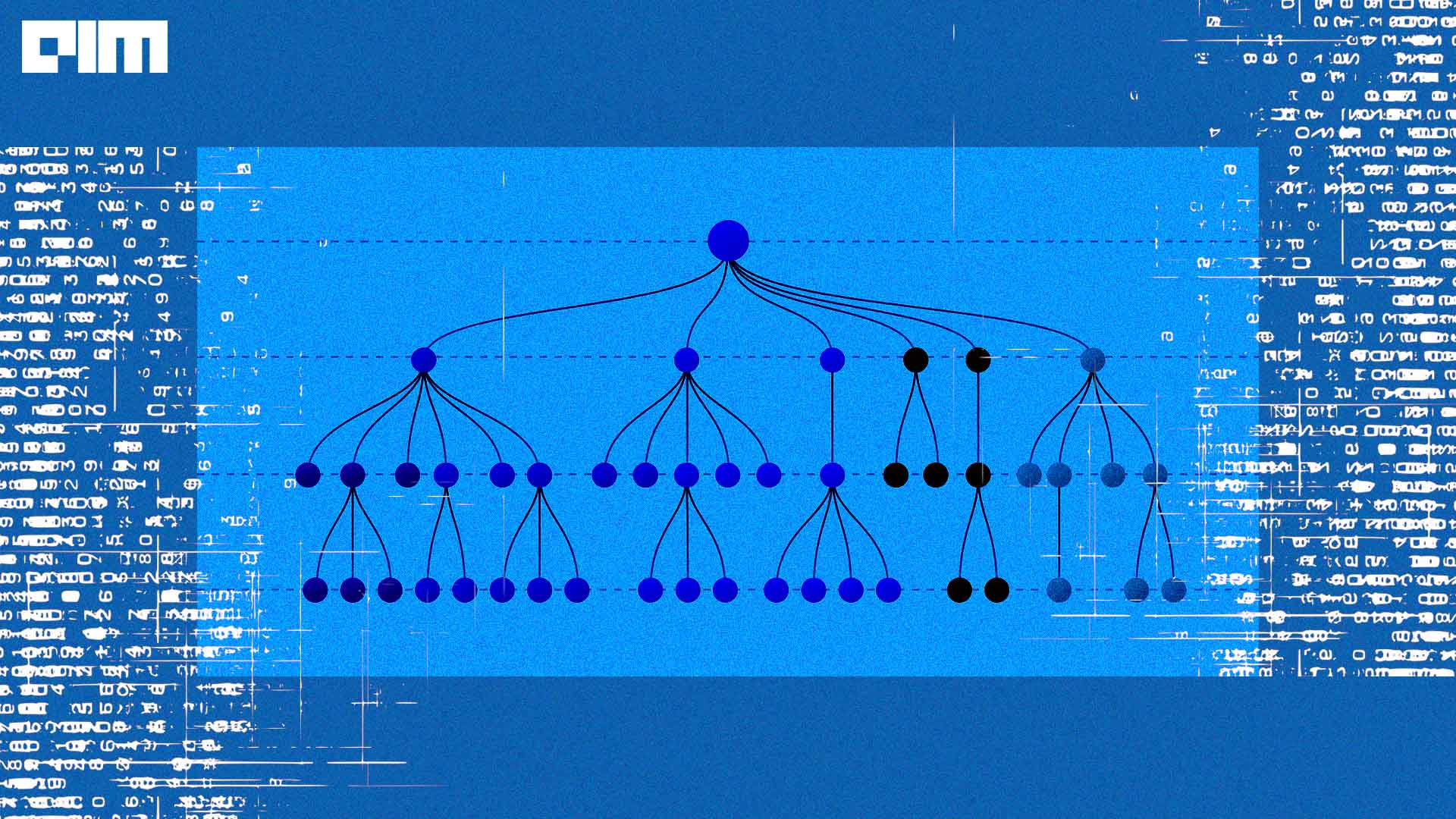
One of the key reasons for XGBoost’s prominence in tabular data tasks is its inherent interpretability. In many real-world applications, understanding why a model makes a particular prediction is as important as the prediction itself. This is especially crucial in fields like healthcare, finance, and regulatory compliance. Unlike deep learning models like Transformers, which are often considered “black boxes,” XGBoost provides clear and intuitive insights into feature importance.
Everyone is focussed on developing LLMs.
— Marc (@marccodess) August 29, 2023
When dealing with tabular datasets, efficiency is paramount. XGBoost’s optimised algorithms and the ability to parallelise training make it exceptionally fast. In contrast, deep learning models like Transformers often require extensive computational resources, including GPUs, to achieve similar performance on structured data. For many organisations, this efficiency can translate into cost savings and faster time-to-insight, as they do not have huge amounts of data.
XGBoost’s versatility extends beyond classification to regression and ranking tasks. Whether you need to predict a continuous target variable, rank items by relevance, or classify data into multiple categories, XGBoost can handle it with ease.
Another advantage of XGBoost is its robustness in handling noisy or incomplete datasets. Though people argue that it also falls into the trap of overfitting, as in real-world scenarios, data can be messy, with missing values, outliers, and inconsistencies. XGBoost mitigates this risk through its regularisation techniques, including L1 and L2 regularisation.
Moreover, when it comes to outliers, while often regarded as data artefacts, can carry valuable information or indicate anomalies in the dataset. XGBoost’s tree-based approach is naturally robust to outliers. Decision trees can capture the underlying patterns in the presence of extreme values, making XGBoost an ideal choice for tasks where outliers are significant.
Conclusively, when it comes to comparatively smaller amounts of structured data, XGBoost proves that sometimes the simplest solution is also the best one. Why not figure out if it can take another step and be used for AI models, and replace Transformers someday?








































































